 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-organized arrival system for urban air mobility
Apr 04, 2024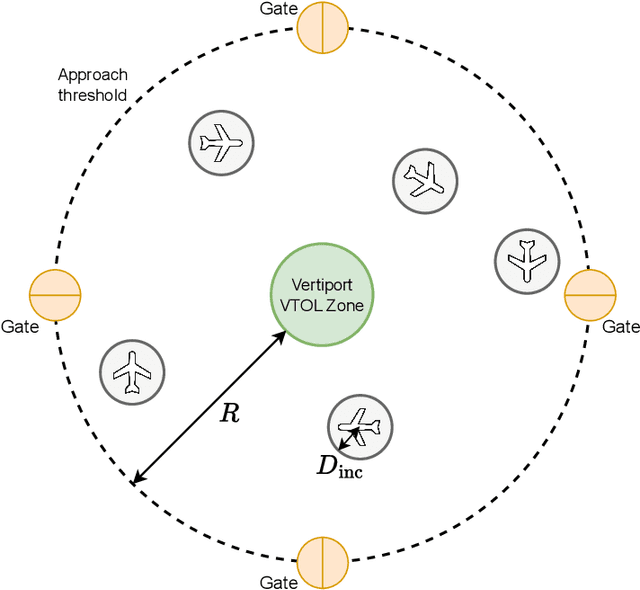

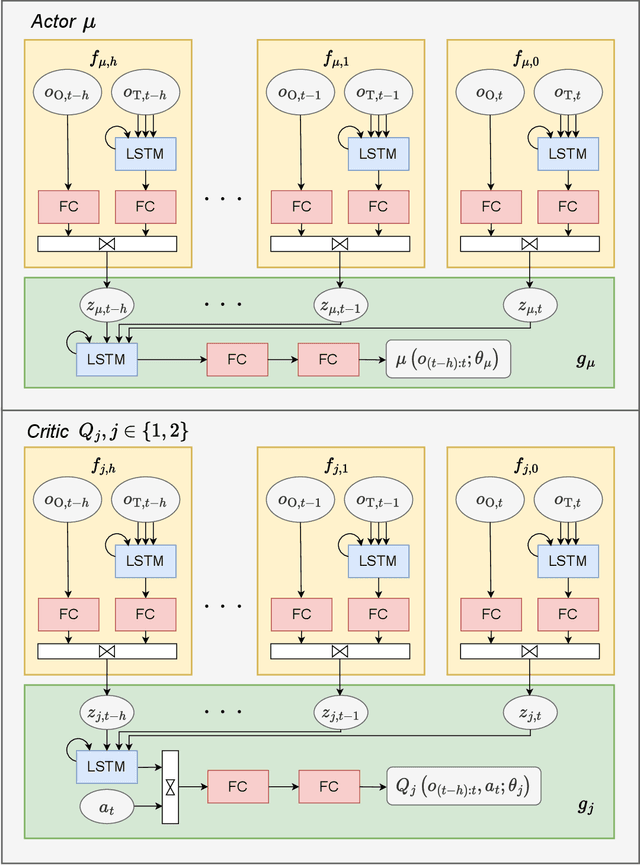
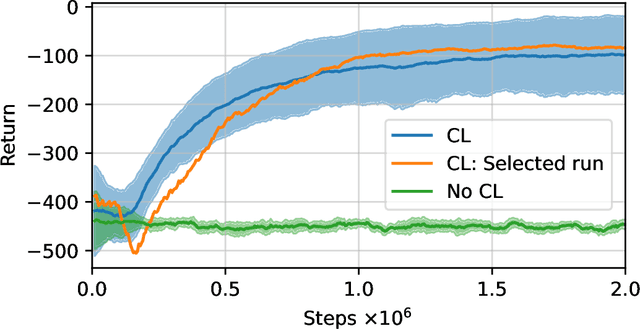
Urban air mobility is an innovative mode of transportation in which electric vertical takeoff and landing (eVTOL) vehicles operate between nodes called vertiports. We outline a self-organized vertiport arrival system based on deep reinforcement learning. The airspace around the vertiport is assumed to be circular, and the vehicles can freely operate inside. Each aircraft is considered an individual agent and follows a shared policy, resulting in decentralized actions that are based on local information. We investigate the development of the reinforcement learning policy during training and illustrate how the algorithm moves from suboptimal local holding patterns to a safe and efficient final policy. The latter is validated in simulation-based scenarios and also deployed on small-scale unmanned aerial vehicles to showcase its real-world usability.
Two-step dynamic obstacle avoidance
Nov 28, 2023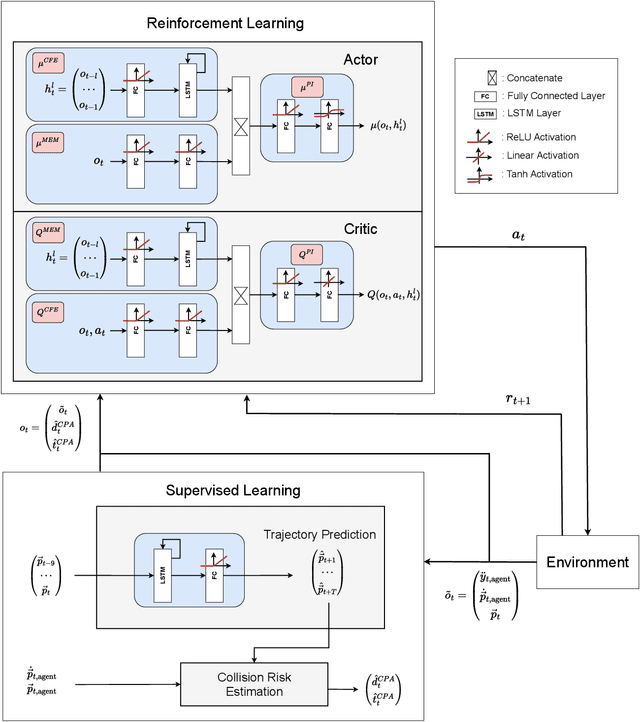
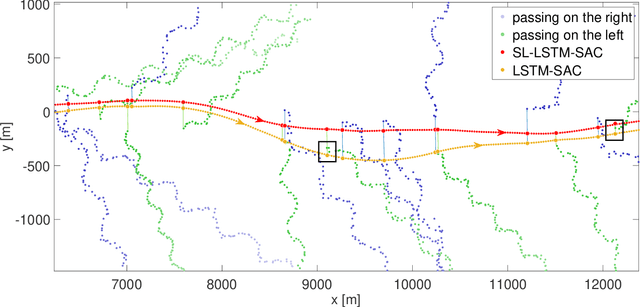


Dynamic obstacle avoidance (DOA) is a fundamental challenge for any autonomous vehicle, independent of whether it operates in sea, air, or land. This paper proposes a two-step architecture for handling DOA tasks by combining supervised and reinforcement learning (RL). In the first step, we introduce a data-driven approach to estimate the collision risk of an obstacle using a recurrent neural network, which is trained in a supervised fashion and offers robustness to non-linear obstacle movements. In the second step, we include these collision risk estimates into the observation space of an RL agent to increase its situational awareness.~We illustrate the power of our two-step approach by training different RL agents in a challenging environment that requires to navigate amid multiple obstacles. The non-linear movements of obstacles are exemplarily modeled based on stochastic processes and periodic patterns, although our architecture is suitable for any obstacle dynamics. The experiments reveal that integrating our collision risk metrics into the observation space doubles the performance in terms of reward, which is equivalent to halving the number of collisions in the considered environment. Furthermore, we show that the architecture's performance improvement is independent of the applied RL algorithm.
2-Level Reinforcement Learning for Ships on Inland Waterways
Jul 25, 2023



This paper proposes a realistic modularized framework for controlling autonomous surface vehicles (ASVs) on inland waterways (IWs) based on deep reinforcement learning (DRL). The framework comprises two levels: a high-level local path planning (LPP) unit and a low-level path following (PF) unit, each consisting of a DRL agent. The LPP agent is responsible for planning a path under consideration of nearby vessels, traffic rules, and the geometry of the waterway. We thereby leverage a recently proposed spatial-temporal recurrent neural network architecture, which is transferred to continuous action spaces. The PF agent is responsible for low-level actuator control while accounting for shallow water influences on the marine craft and the environmental forces winds, waves, and currents. Both agents are thoroughly validated in simulation, employing the lower Elbe in northern Germany as an example case and using real AIS trajectories to model the behavior of other ships.
Spatial-temporal recurrent reinforcement learning for autonomous ships
Nov 02, 2022The paper proposes a spatial-temporal recurrent neural network architecture for Deep $Q$-Networks to steer an autonomous ship. The network design allows handling an arbitrary number of surrounding target ships while offering robustness to partial observability. Further, a state-of-the-art collision risk metric is proposed to enable an easier assessment of different situations by the agent. The COLREG rules of maritime traffic are explicitly considered in the design of the reward function. The final policy is validated on a custom set of newly created single-ship encounters called "Around the Clock" problems and the commonly chosen Imazu (1987) problems, which include 18 multi-ship scenarios. Additionally, the framework shows robustness when deployed simultaneously in multi-agent scenarios. The proposed network architecture is compatible with other deep reinforcement learning algorithms, including actor-critic frameworks.
Two-Sample Testing in Reinforcement Learning
Jan 20, 2022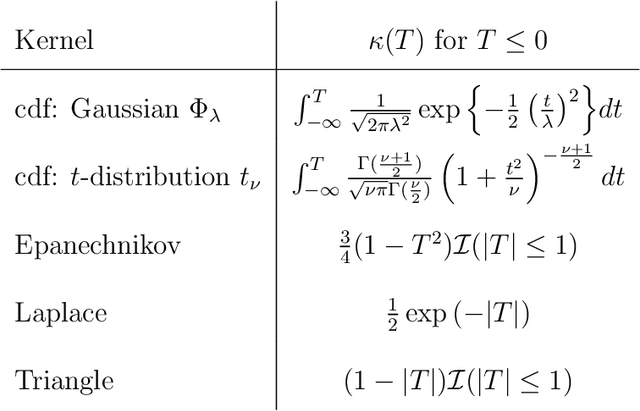
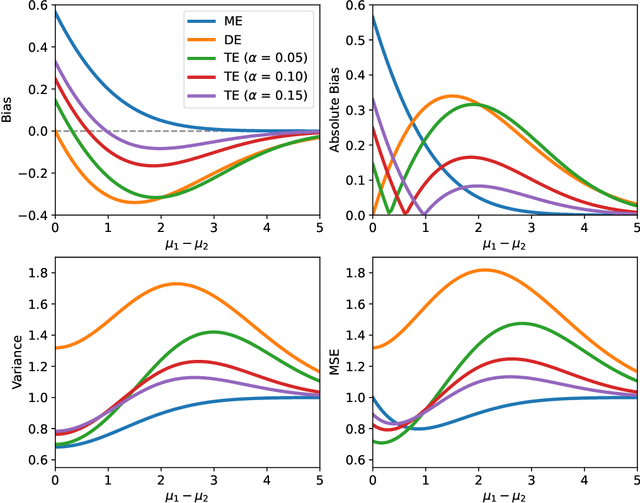
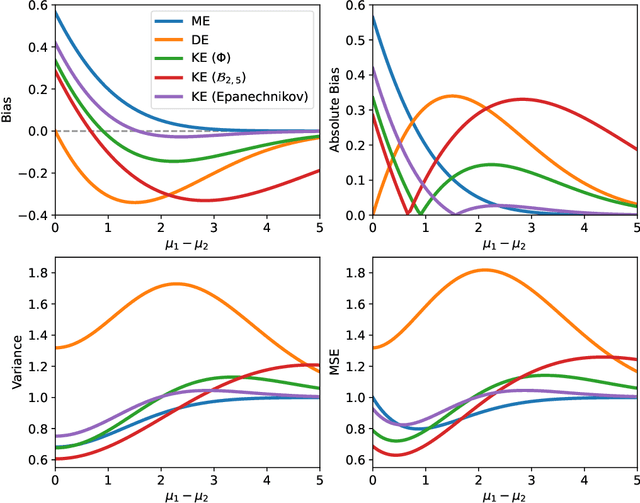
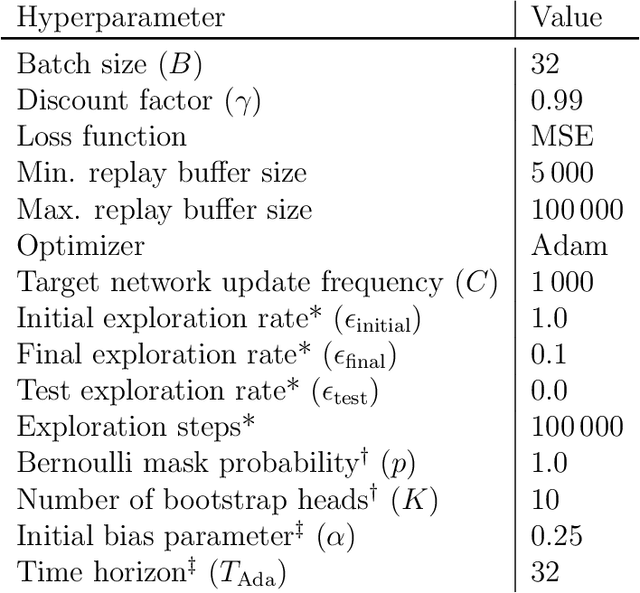
Value-based reinforcement-learning algorithms have shown strong performances in games, robotics, and other real-world applications. The most popular sample-based method is $Q$-Learning. A $Q$-value is the expected return for a state-action pair when following a particular policy, and the algorithm subsequently performs updates by adjusting the current $Q$-value towards the observed reward and the maximum of the $Q$-values of the next state. The procedure introduces maximization bias, and solutions like Double $Q$-Learning have been considered. We frame the bias problem statistically and consider it an instance of estimating the maximum expected value (MEV) of a set of random variables. We propose the $T$-Estimator (TE) based on two-sample testing for the mean. The TE flexibly interpolates between over- and underestimation by adjusting the level of significance of the underlying hypothesis tests. A generalization termed $K$-Estimator (KE) obeys the same bias and variance bounds as the TE while relying on a nearly arbitrary kernel function. Using the TE and the KE, we introduce modifications of $Q$-Learning and its neural network analog, the Deep $Q$-Network. The proposed estimators and algorithms are thoroughly tested and validated on a diverse set of tasks and environments, illustrating the performance potential of the TE and KE.
Missing Velocity in Dynamic Obstacle Avoidance based on Deep Reinforcement Learning
Dec 28, 2021

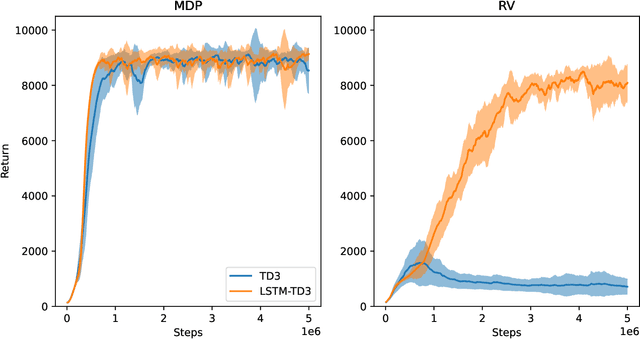

We introduce a novel approach to dynamic obstacle avoidance based on Deep Reinforcement Learning by defining a traffic type independent environment with variable complexity. Filling a gap in the current literature, we thoroughly investigate the effect of missing velocity information on an agent's performance in obstacle avoidance tasks. This is a crucial issue in practice since several sensors yield only positional information of objects or vehicles. We evaluate frequently-applied approaches in scenarios of partial observability, namely the incorporation of recurrency in the deep neural networks and simple frame-stacking. For our analysis, we rely on state-of-the-art model-free deep RL algorithms. The lack of velocity information is found to significantly impact the performance of an agent. Both approaches - recurrency and frame-stacking - cannot consistently replace missing velocity information in the observation space. However, in simplified scenarios, they can significantly boost performance and stabilize the overall training procedure.