 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Sample Testing in Reinforcement Learning
Paper and Code
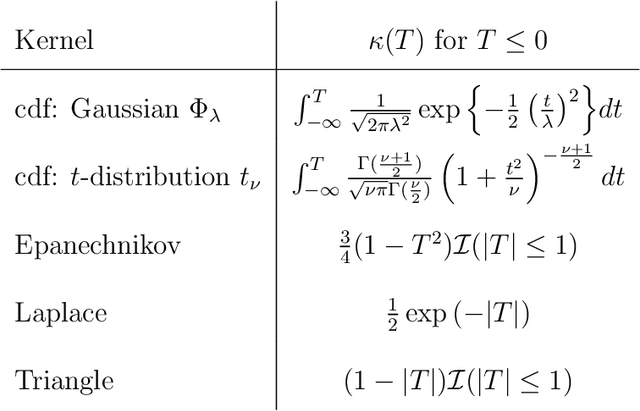
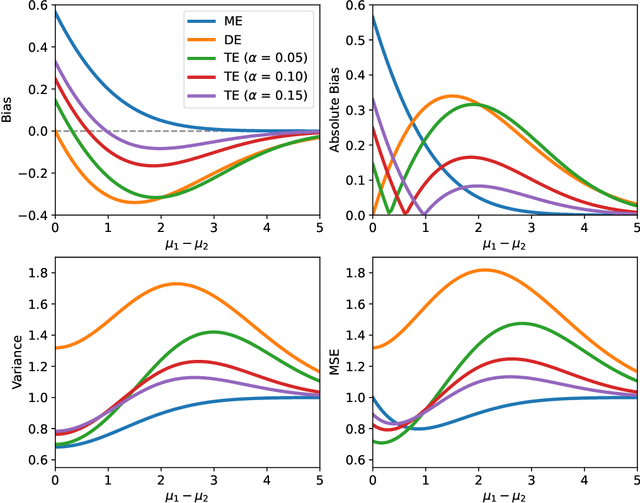
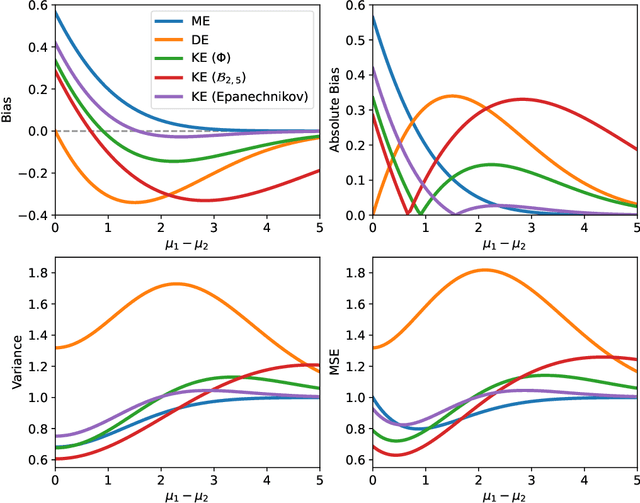
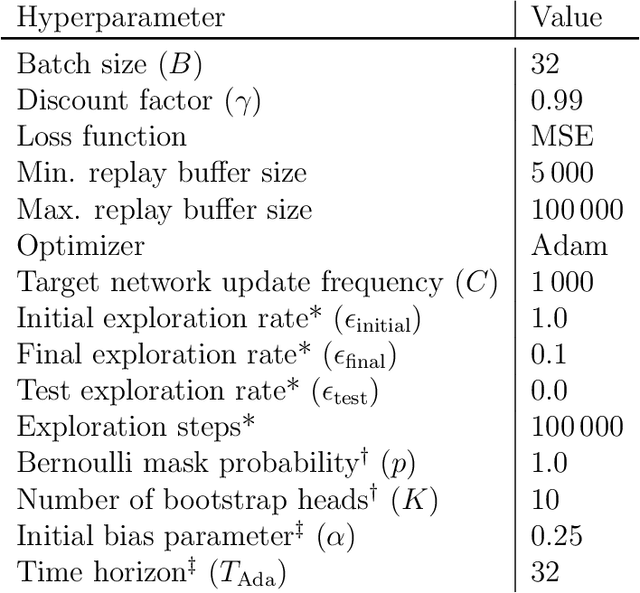
Value-based reinforcement-learning algorithms have shown strong performances in games, robotics, and other real-world applications. The most popular sample-based method is $Q$-Learning. A $Q$-value is the expected return for a state-action pair when following a particular policy, and the algorithm subsequently performs updates by adjusting the current $Q$-value towards the observed reward and the maximum of the $Q$-values of the next state. The procedure introduces maximization bias, and solutions like Double $Q$-Learning have been considered. We frame the bias problem statistically and consider it an instance of estimating the maximum expected value (MEV) of a set of random variables. We propose the $T$-Estimator (TE) based on two-sample testing for the mean. The TE flexibly interpolates between over- and underestimation by adjusting the level of significance of the underlying hypothesis tests. A generalization termed $K$-Estimator (KE) obeys the same bias and variance bounds as the TE while relying on a nearly arbitrary kernel function. Using the TE and the KE, we introduce modifications of $Q$-Learning and its neural network analog, the Deep $Q$-Network. The proposed estimators and algorithms are thoroughly tested and validated on a diverse set of tasks and environments, illustrating the performance potential of the TE and KE.