 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Adversarial Learning for Complementary Item Recommendation
Mar 10, 2023Complementary item recommendations are a ubiquitous feature of modern e-commerce sites. Such recommendations are highly effective when they are based on collaborative signals like co-purchase statistics. In certain online marketplaces, however, e.g., on online auction sites, constantly new items are added to the catalog. In such cases, complementary item recommendations are often based on item side-information due to a lack of interaction data. In this work, we propose a novel approach that can leverage both item side-information and labeled complementary item pairs to generate effective complementary recommendations for cold items, i.e., for items for which no co-purchase statistics yet exist. Given that complementary items typically have to be of a different category than the seed item, we technically maintain a latent space for each item category. Simultaneously, we learn to project distributed item representations into these category spaces to determine suitable recommendations. The main learning process in our architecture utilizes labeled pairs of complementary items. In addition, we adopt ideas from Cycle Generative Adversarial Networks (CycleGAN) to leverage available item information even in case no labeled data exists for a given item and category. Experiments on three e-commerce datasets show that our method is highly effective.
A Black-Box Attack Model for Visually-Aware Recommender Systems
Nov 05, 2020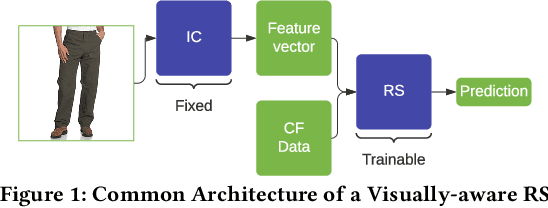

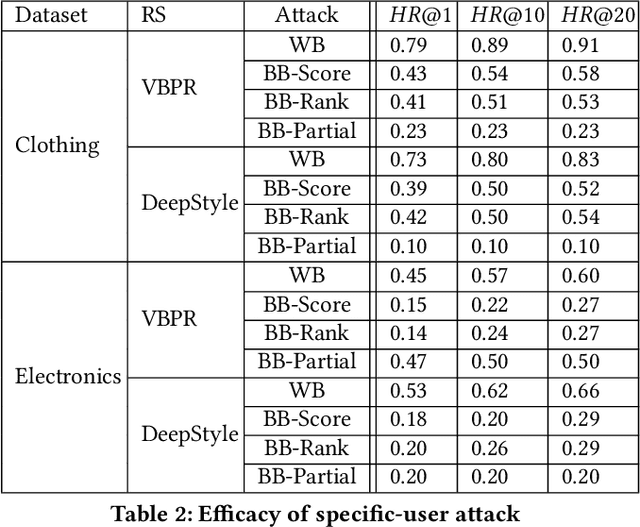
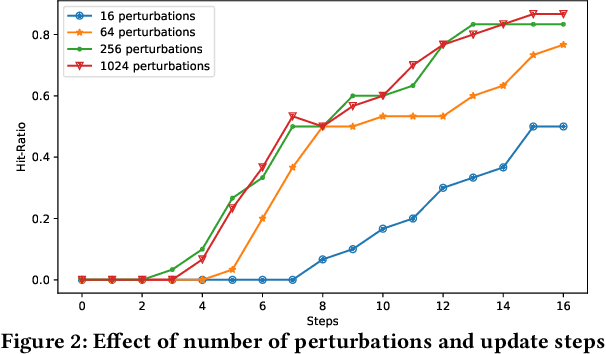
Due to the advances in deep learning, visually-aware recommender systems (RS) have recently attracted increased research interest. Such systems combine collaborative signals with images, usually represented as feature vectors outputted by pre-trained image models. Since item catalogs can be huge, recommendation service providers often rely on images that are supplied by the item providers. In this work, we show that relying on such external sources can make an RS vulnerable to attacks, where the goal of the attacker is to unfairly promote certain pushed items. Specifically, we demonstrate how a new visual attack model can effectively influence the item scores and rankings in a black-box approach, i.e., without knowing the parameters of the model. The main underlying idea is to systematically create small human-imperceptible perturbations of the pushed item image and to devise appropriate gradient approximation methods to incrementally raise the pushed item's score. Experimental evaluations on two datasets show that the novel attack model is effective even when the contribution of the visual features to the overall performance of the recommender system is modest.
Understanding Convolutional Neural Networks for Text Classification
Sep 21, 2018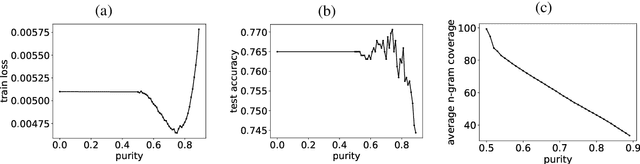
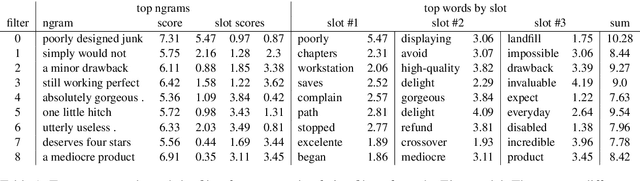
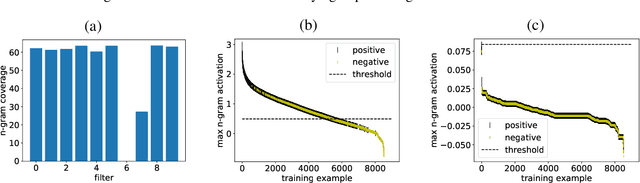
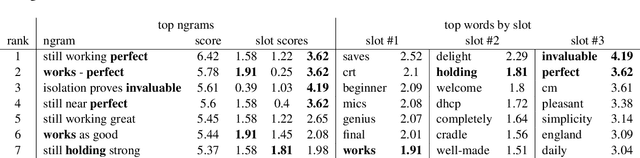
We present an analysis into the inner workings of Convolutional Neural Networks (CNNs) for processing text. CNNs used for computer vision can be interpreted by projecting filters into image space, but for discrete sequence inputs CNNs remain a mystery. We aim to understand the method by which the networks process and classify text. We examine common hypotheses to this problem: that filters, accompanied by global max-pooling, serve as ngram detectors. We show that filters may capture several different semantic classes of ngrams by using different activation patterns, and that global max-pooling induces behavior which separates important ngrams from the rest. Finally, we show practical use cases derived from our findings in the form of model interpretability (explaining a trained model by deriving a concrete identity for each filter, bridging the gap between visualization tools in vision tasks and NLP) and prediction interpretability (explaining predictions).
Rank and Rate: Multi-task Learning for Recommender Systems
Jul 31, 2018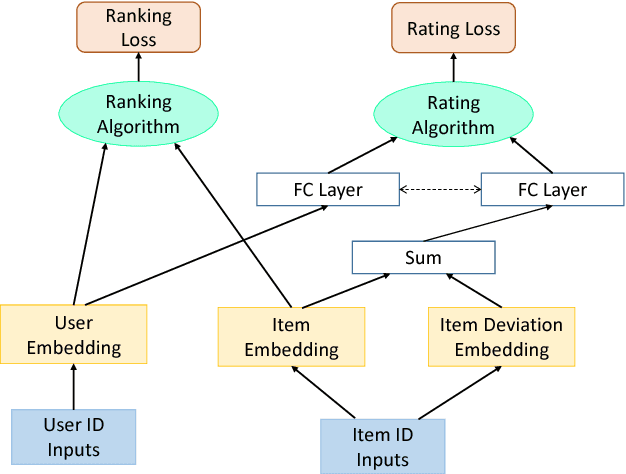
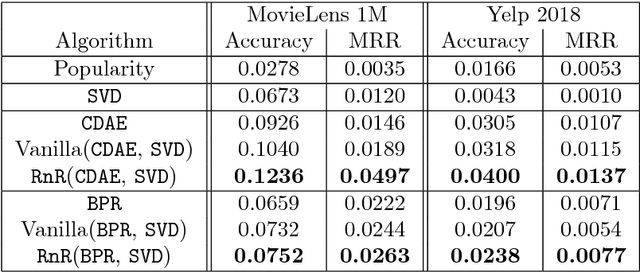
The two main tasks in the Recommender Systems domain are the ranking and rating prediction tasks. The rating prediction task aims at predicting to what extent a user would like any given item, which would enable to recommend the items with the highest predicted scores. The ranking task on the other hand directly aims at recommending the most valuable items for the user. Several previous approaches proposed learning user and item representations to optimize both tasks simultaneously in a multi-task framework. In this work we propose a novel multi-task framework that exploits the fact that a user does a two-phase decision process - first decides to interact with an item (ranking task) and only afterward to rate it (rating prediction task). We evaluated our framework on two benchmark datasets, on two different configurations and showed its superiority over state-of-the-art methods.
Privacy-Adversarial User Representations in Recommender Systems
Jul 10, 2018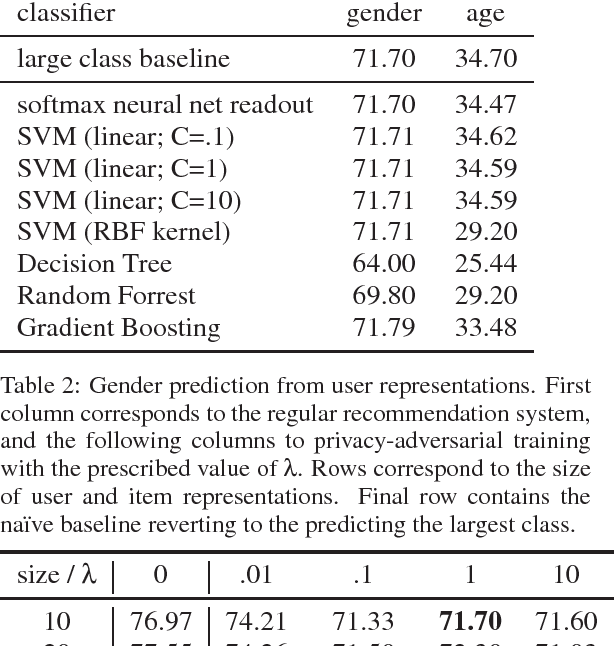
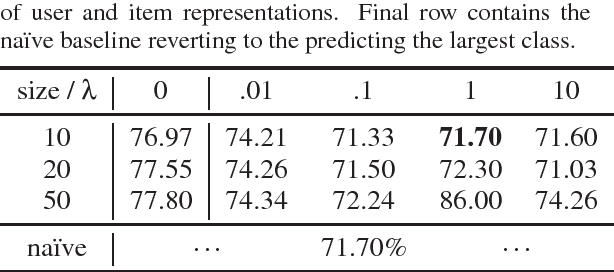
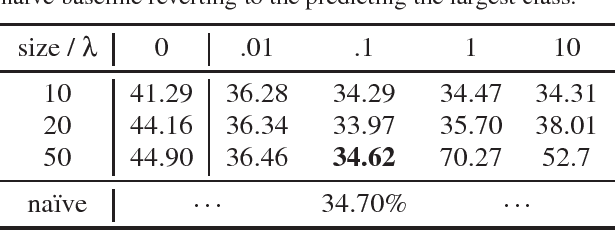
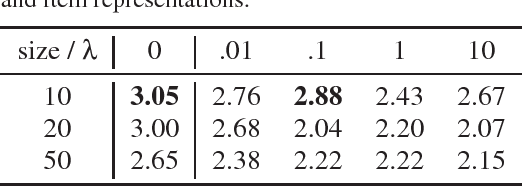
Latent factor models for recommender systems represent users and items as low dimensional vectors. Privacy risks have been previously studied mostly in the context of recovery of personal information in the form of usage records from the training data. However, the user representations themselves may be used together with external data to recover private user information such as gender and age. In this paper we show that user vectors calculated by a common recommender system can be exploited in this way. We propose the privacy-adversarial framework to eliminate such leakage, and study the trade-off between recommender performance and leakage both theoretically and empirically using a benchmark dataset. We briefly discuss further applications of this method towards the generation of deeper and more insightful recommendations.