 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Fingerprints for Adversarial Attack Detection
Nov 07, 2024

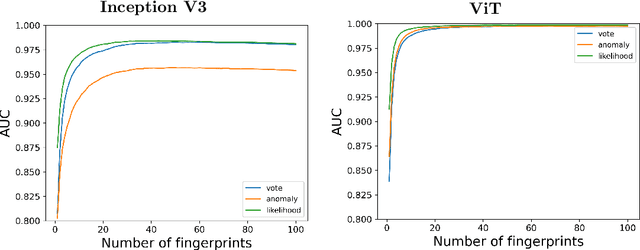

Deep learning models for image classification have become standard tools in recent years. A well known vulnerability of these models is their susceptibility to adversarial examples. These are generated by slightly altering an image of a certain class in a way that is imperceptible to humans but causes the model to classify it wrongly as another class. Many algorithms have been proposed to address this problem, falling generally into one of two categories: (i) building robust classifiers (ii) directly detecting attacked images. Despite the good performance of these detectors, we argue that in a white-box setting, where the attacker knows the configuration and weights of the network and the detector, they can overcome the detector by running many examples on a local copy, and sending only those that were not detected to the actual model. This problem is common in security applications where even a very good model is not sufficient to ensure safety. In this paper we propose to overcome this inherent limitation of any static defence with randomization. To do so, one must generate a very large family of detectors with consistent performance, and select one or more of them randomly for each input. For the individual detectors, we suggest the method of neural fingerprints. In the training phase, for each class we repeatedly sample a tiny random subset of neurons from certain layers of the network, and if their average is sufficiently different between clean and attacked images of the focal class they are considered a fingerprint and added to the detector bank. During test time, we sample fingerprints from the bank associated with the label predicted by the model, and detect attacks using a likelihood ratio test. We evaluate our detectors on ImageNet with different attack methods and model architectures, and show near-perfect detection with low rates of false detection.
Explainable AI and Adoption of Algorithmic Advisors: an Experimental Study
Jan 05, 2021
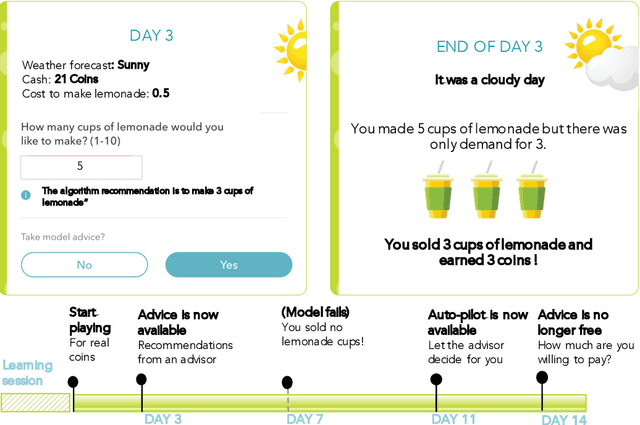
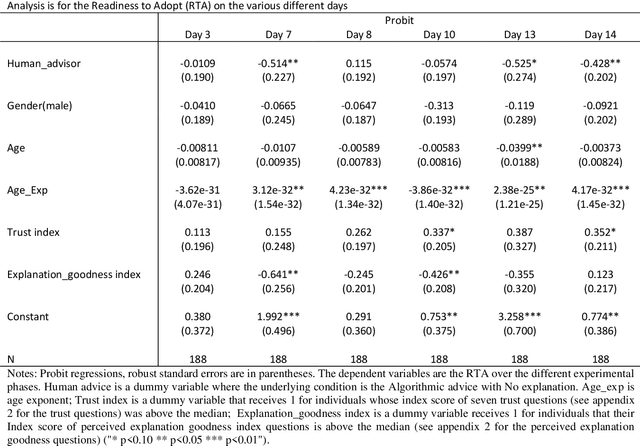

Machine learning is becoming a commonplace part of our technological experience. The notion of explainable AI (XAI) is attractive when regulatory or usability considerations necessitate the ability to back decisions with a coherent explanation. A large body of research has addressed algorithmic methods of XAI, but it is still unclear how to determine what is best suited to create human cooperation and adoption of automatic systems. Here we develop an experimental methodology where participants play a web-based game, during which they receive advice from either a human or algorithmic advisor, accompanied with explanations that vary in nature between experimental conditions. We use a reference-dependent decision-making framework, evaluate the game results over time, and in various key situations, to determine whether the different types of explanations affect the readiness to adopt, willingness to pay and trust a financial AI consultant. We find that the types of explanations that promotes adoption during first encounter differ from those that are most successful following failure or when cost is involved. Furthermore, participants are willing to pay more for AI-advice that includes explanations. These results add to the literature on the importance of XAI for algorithmic adoption and trust.
Paired-Consistency: An Example-Based Model-Agnostic Approach to Fairness Regularization in Machine Learning
Aug 07, 2019



As AI systems develop in complexity it is becoming increasingly hard to ensure non-discrimination on the basis of protected attributes such as gender, age, and race. Many recent methods have been developed for dealing with this issue as long as the protected attribute is explicitly available for the algorithm. We address the setting where this is not the case (with either no explicit protected attribute, or a large set of them). Instead, we assume the existence of a fair domain expert capable of generating an extension to the labeled dataset - a small set of example pairs, each having a different value on a subset of protected variables, but judged to warrant a similar model response. We define a performance metric - paired consistency. Paired consistency measures how close the output (assigned by a classifier or a regressor) is on these carefully selected pairs of examples for which fairness dictates identical decisions. In some cases consistency can be embedded within the loss function during optimization and serve as a fairness regularizer, and in others it is a tool for fair model selection. We demonstrate our method using the well studied Income Census dataset.
Privacy-Adversarial User Representations in Recommender Systems
Jul 10, 2018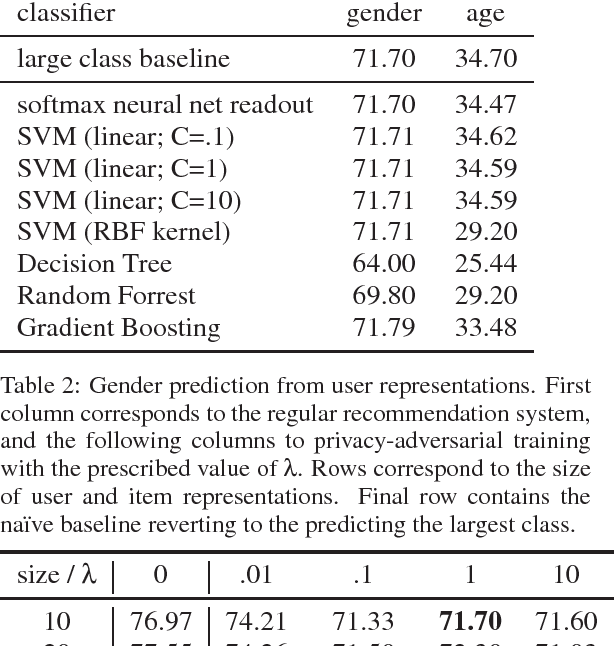
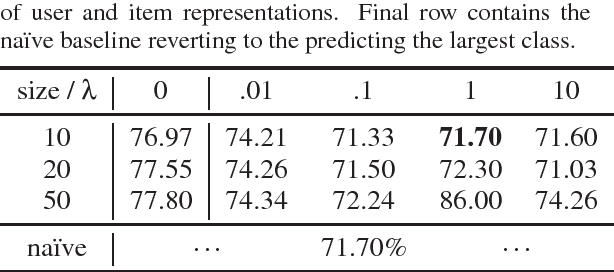
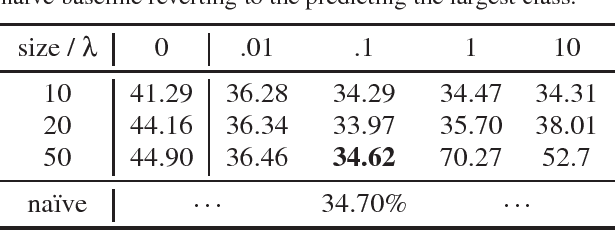
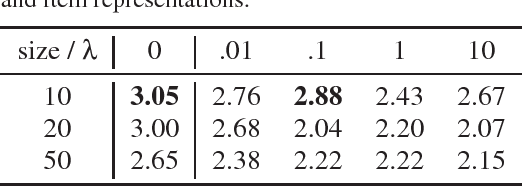
Latent factor models for recommender systems represent users and items as low dimensional vectors. Privacy risks have been previously studied mostly in the context of recovery of personal information in the form of usage records from the training data. However, the user representations themselves may be used together with external data to recover private user information such as gender and age. In this paper we show that user vectors calculated by a common recommender system can be exploited in this way. We propose the privacy-adversarial framework to eliminate such leakage, and study the trade-off between recommender performance and leakage both theoretically and empirically using a benchmark dataset. We briefly discuss further applications of this method towards the generation of deeper and more insightful recommendations.
Fusing Multifaceted Transaction Data for User Modeling and Demographic Prediction
Dec 19, 2017

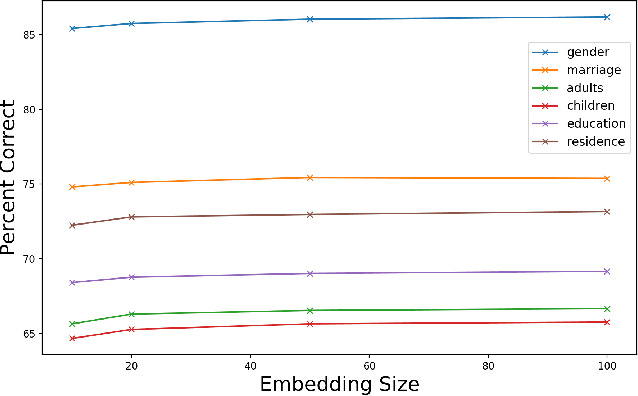
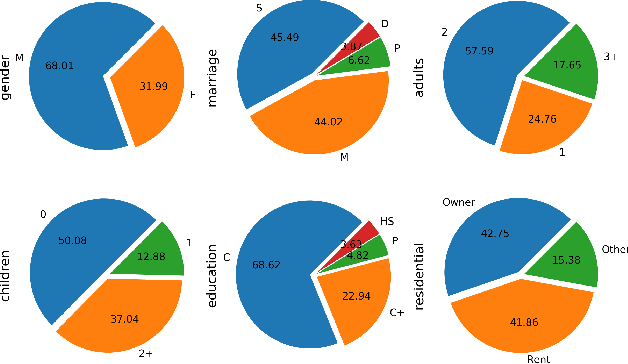
Inferring user characteristics such as demographic attributes is of the utmost importance in many user-centric applications. Demographic data is an enabler of personalization, identity security, and other applications. Despite that, this data is sensitive and often hard to obtain. Previous work has shown that purchase history can be used for multi-task prediction of many demographic fields such as gender and marital status. Here we present an embedding based method to integrate multifaceted sequences of transaction data, together with auxiliary relational tables, for better user modeling and demographic prediction.
Every Untrue Label is Untrue in its Own Way: Controlling Error Type with the Log Bilinear Loss
Apr 20, 2017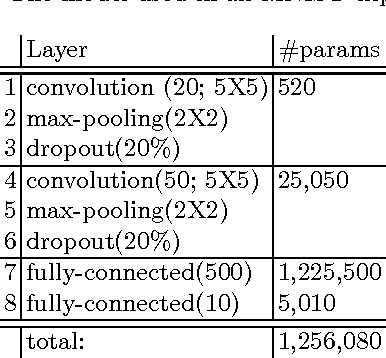
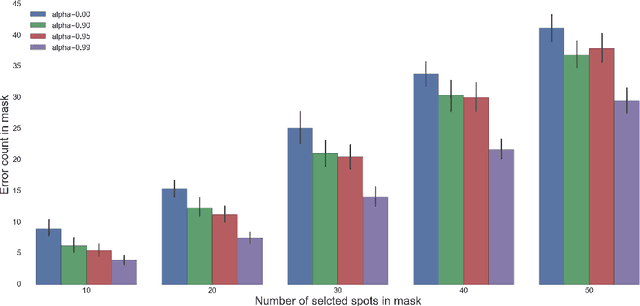
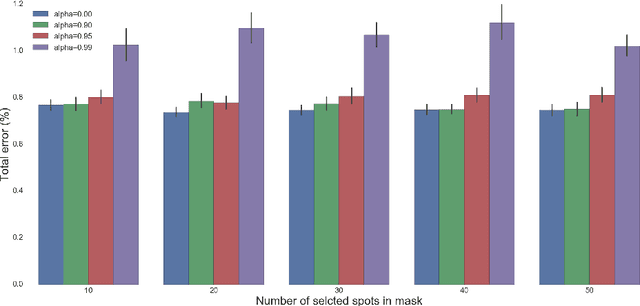
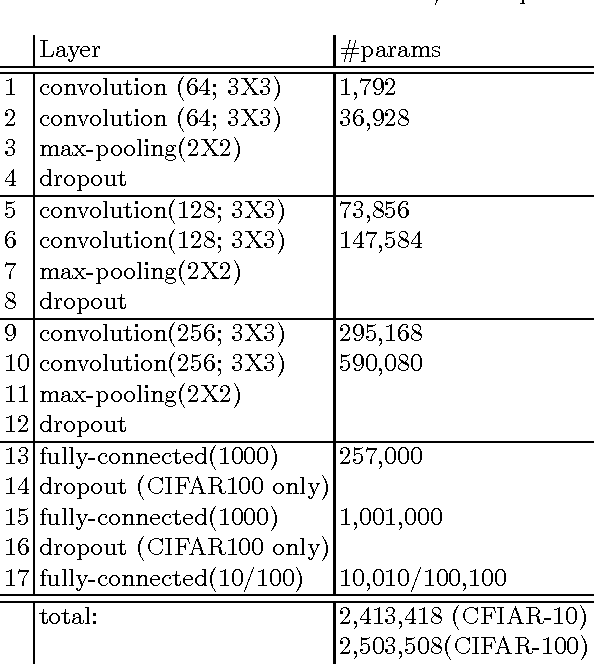
Deep learning has become the method of choice in many application domains of machine learning in recent years, especially for multi-class classification tasks. The most common loss function used in this context is the cross-entropy loss, which reduces to the log loss in the typical case when there is a single correct response label. While this loss is insensitive to the identity of the assigned class in the case of misclassification, in practice it is often the case that some errors may be more detrimental than others. Here we present the bilinear-loss (and related log-bilinear-loss) which differentially penalizes the different wrong assignments of the model. We thoroughly test this method using standard models and benchmark image datasets. As one application, we show the ability of this method to better contain error within the correct super-class, in the hierarchically labeled CIFAR100 dataset, without affecting the overall performance of the classifier.
Optimized Linear Imputation
Dec 07, 2016

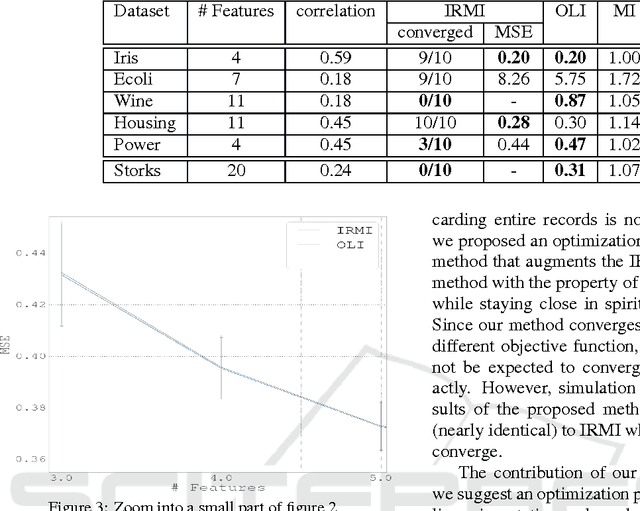
Often in real-world datasets, especially in high dimensional data, some feature values are missing. Since most data analysis and statistical methods do not handle gracefully missing values, the first step in the analysis requires the imputation of missing values. Indeed, there has been a long standing interest in methods for the imputation of missing values as a pre-processing step. One recent and effective approach, the IRMI stepwise regression imputation method, uses a linear regression model for each real-valued feature on the basis of all other features in the dataset. However, the proposed iterative formulation lacks convergence guarantee. Here we propose a closely related method, stated as a single optimization problem and a block coordinate-descent solution which is guaranteed to converge to a local minimum. Experiments show results on both synthetic and benchmark datasets, which are comparable to the results of the IRMI method whenever it converges. However, while in the set of experiments described here IRMI often does not converge, the performance of our methods is shown to be markedly superior in comparison with other methods.
Online Trajectory Segmentation and Summary With Applications to Visualization and Retrieval
Jul 24, 2016



Trajectory segmentation is the process of subdividing a trajectory into parts either by grouping points similar with respect to some measure of interest, or by minimizing a global objective function. Here we present a novel online algorithm for segmentation and summary, based on point density along the trajectory, and based on the nature of the naturally occurring structure of intermittent bouts of locomotive and local activity. We show an application to visualization of trajectory datasets, and discuss the use of the summary as an index allowing efficient queries which are otherwise impossible or computationally expensive, over very large datasets.
Topic Modeling of Behavioral Modes Using Sensor Data
Nov 16, 2015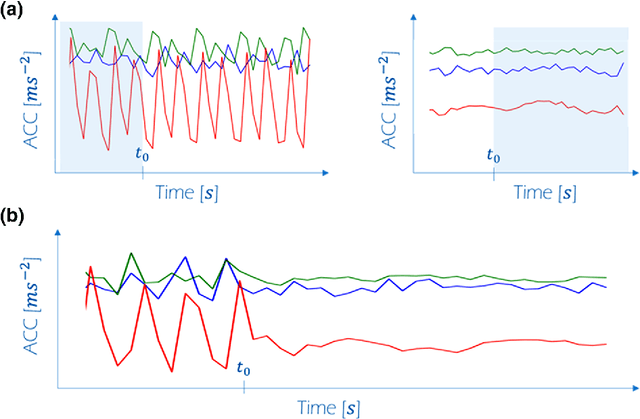
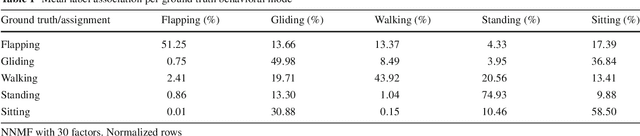

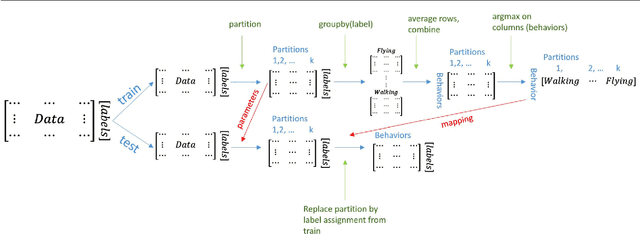
The field of Movement Ecology, like so many other fields, is experiencing a period of rapid growth in availability of data. As the volume rises, traditional methods are giving way to machine learning and data science, which are playing an increasingly large part it turning this data into science-driving insights. One rich and interesting source is the bio-logger. These small electronic wearable devices are attached to animals free to roam in their natural habitats, and report back readings from multiple sensors, including GPS and accelerometer bursts. A common use of accelerometer data is for supervised learning of behavioral modes. However, we need unsupervised analysis tools as well, in order to overcome the inherent difficulties of obtaining a labeled dataset, which in some cases is either infeasible or does not successfully encompass the full repertoire of behavioral modes of interest. Here we present a matrix factorization based topic-model method for accelerometer bursts, derived using a linear mixture property of patch features. Our method is validated via comparison to a labeled dataset, and is further compared to standard clustering algorithms.
* Invited Extended version of a paper \cite{resheffmatrix} presented at the international conference \textit{Data Science and Advanced Analytics}, Paris, France, 19-21 OCtober 2015