 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Datacenter Congestion Control
Feb 18, 2021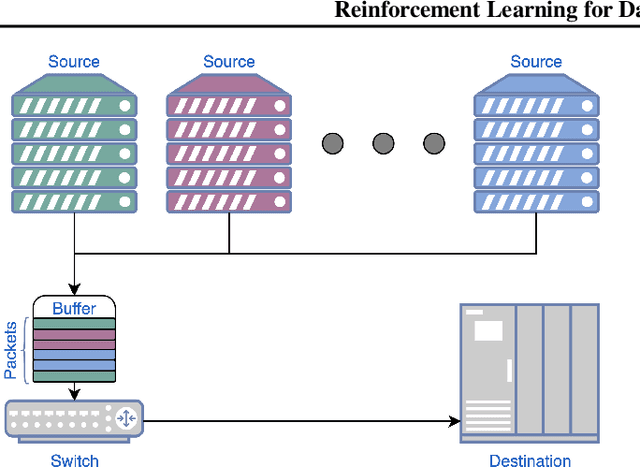

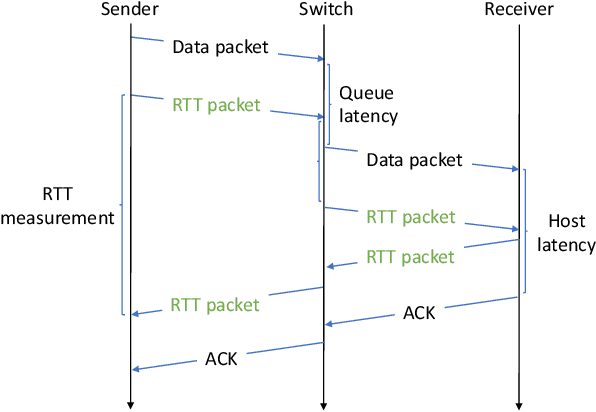
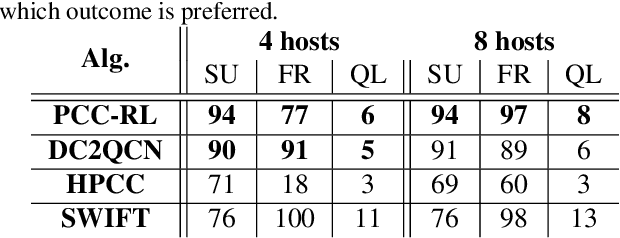
We approach the task of network congestion control in datacenters using Reinforcement Learning (RL). Successful congestion control algorithms can dramatically improve latency and overall network throughput. Until today, no such learning-based algorithms have shown practical potential in this domain. Evidently, the most popular recent deployments rely on rule-based heuristics that are tested on a predetermined set of benchmarks. Consequently, these heuristics do not generalize well to newly-seen scenarios. Contrarily, we devise an RL-based algorithm with the aim of generalizing to different configurations of real-world datacenter networks. We overcome challenges such as partial-observability, non-stationarity, and multi-objectiveness. We further propose a policy gradient algorithm that leverages the analytical structure of the reward function to approximate its derivative and improve stability. We show that this scheme outperforms alternative popular RL approaches, and generalizes to scenarios that were not seen during training. Our experiments, conducted on a realistic simulator that emulates communication networks' behavior, exhibit improved performance concurrently on the multiple considered metrics compared to the popular algorithms deployed today in real datacenters. Our algorithm is being productized to replace heuristics in some of the largest datacenters in the world.
Distance-based Confidence Score for Neural Network Classifiers
Sep 28, 2017



The reliable measurement of confidence in classifiers' predictions is very important for many applications and is, therefore, an important part of classifier design. Yet, although deep learning has received tremendous attention in recent years, not much progress has been made in quantifying the prediction confidence of neural network classifiers. Bayesian models offer a mathematically grounded framework to reason about model uncertainty, but usually come with prohibitive computational costs. In this paper we propose a simple, scalable method to achieve a reliable confidence score, based on the data embedding derived from the penultimate layer of the network. We investigate two ways to achieve desirable embeddings, by using either a distance-based loss or Adversarial Training. We then test the benefits of our method when used for classification error prediction, weighting an ensemble of classifiers, and novelty detection. In all tasks we show significant improvement over traditional, commonly used confidence scores.
Every Untrue Label is Untrue in its Own Way: Controlling Error Type with the Log Bilinear Loss
Apr 20, 2017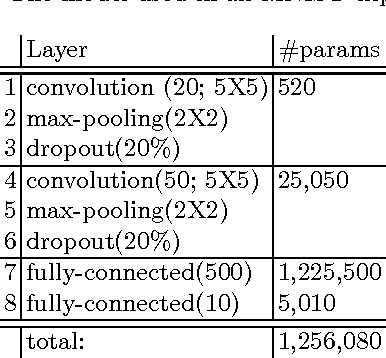
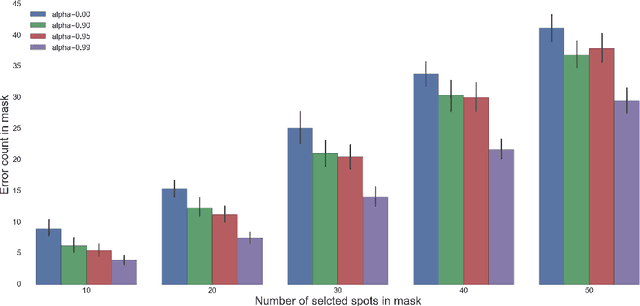
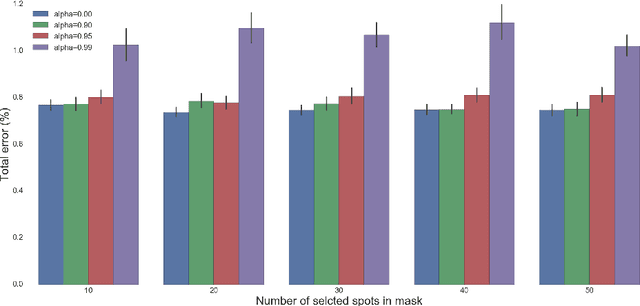
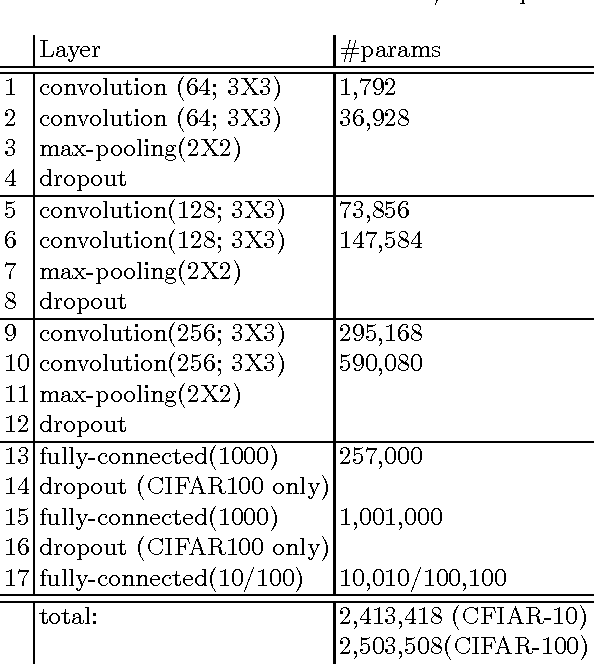
Deep learning has become the method of choice in many application domains of machine learning in recent years, especially for multi-class classification tasks. The most common loss function used in this context is the cross-entropy loss, which reduces to the log loss in the typical case when there is a single correct response label. While this loss is insensitive to the identity of the assigned class in the case of misclassification, in practice it is often the case that some errors may be more detrimental than others. Here we present the bilinear-loss (and related log-bilinear-loss) which differentially penalizes the different wrong assignments of the model. We thoroughly test this method using standard models and benchmark image datasets. As one application, we show the ability of this method to better contain error within the correct super-class, in the hierarchically labeled CIFAR100 dataset, without affecting the overall performance of the classifier.
Word Embeddings and Their Use In Sentence Classification Tasks
Oct 26, 2016
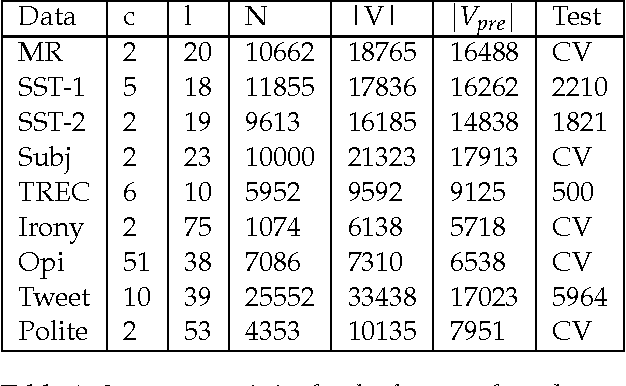
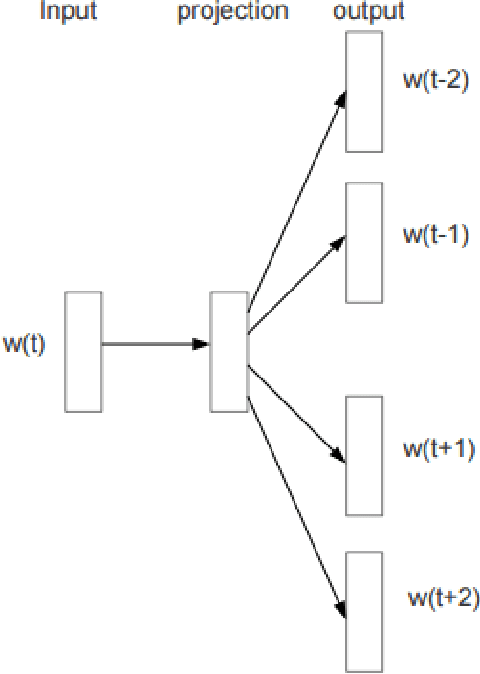

This paper have two parts. In the first part we discuss word embeddings. We discuss the need for them, some of the methods to create them, and some of their interesting properties. We also compare them to image embeddings and see how word embedding and image embedding can be combined to perform different tasks. In the second part we implement a convolutional neural network trained on top of pre-trained word vectors. The network is used for several sentence-level classification tasks, and achieves state-of-art (or comparable) results, demonstrating the great power of pre-trainted word embeddings over random ones.