Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Embeddings and Their Use In Sentence Classification Tasks
Paper and Code

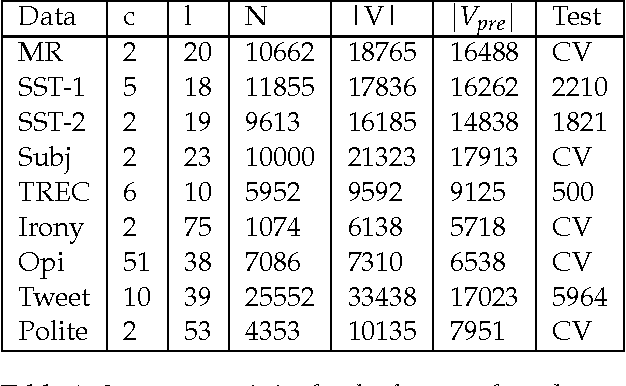
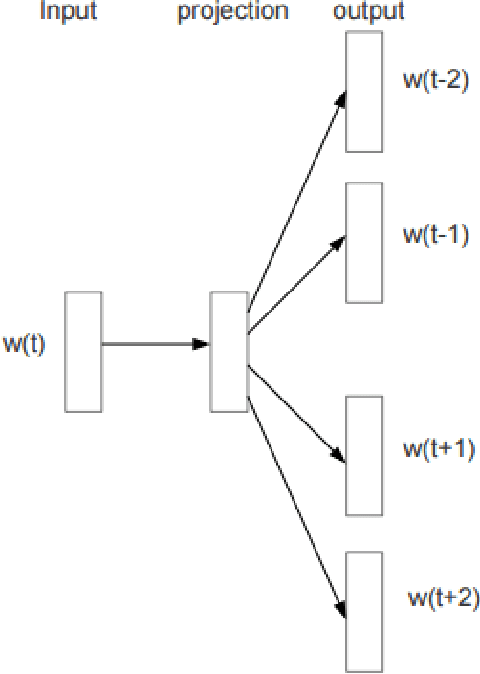

This paper have two parts. In the first part we discuss word embeddings. We discuss the need for them, some of the methods to create them, and some of their interesting properties. We also compare them to image embeddings and see how word embedding and image embedding can be combined to perform different tasks. In the second part we implement a convolutional neural network trained on top of pre-trained word vectors. The network is used for several sentence-level classification tasks, and achieves state-of-art (or comparable) results, demonstrating the great power of pre-trainted word embeddings over random ones.
* 13 pages, 10 figures
View paper on