 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Fingerprints for Adversarial Attack Detection
Paper and Code


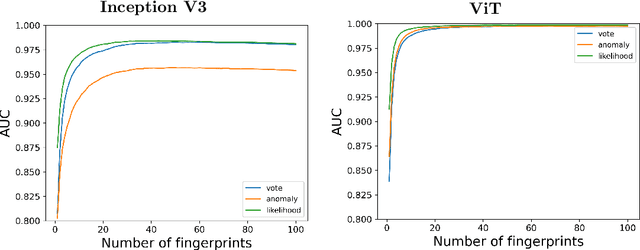

Deep learning models for image classification have become standard tools in recent years. A well known vulnerability of these models is their susceptibility to adversarial examples. These are generated by slightly altering an image of a certain class in a way that is imperceptible to humans but causes the model to classify it wrongly as another class. Many algorithms have been proposed to address this problem, falling generally into one of two categories: (i) building robust classifiers (ii) directly detecting attacked images. Despite the good performance of these detectors, we argue that in a white-box setting, where the attacker knows the configuration and weights of the network and the detector, they can overcome the detector by running many examples on a local copy, and sending only those that were not detected to the actual model. This problem is common in security applications where even a very good model is not sufficient to ensure safety. In this paper we propose to overcome this inherent limitation of any static defence with randomization. To do so, one must generate a very large family of detectors with consistent performance, and select one or more of them randomly for each input. For the individual detectors, we suggest the method of neural fingerprints. In the training phase, for each class we repeatedly sample a tiny random subset of neurons from certain layers of the network, and if their average is sufficiently different between clean and attacked images of the focal class they are considered a fingerprint and added to the detector bank. During test time, we sample fingerprints from the bank associated with the label predicted by the model, and detect attacks using a likelihood ratio test. We evaluate our detectors on ImageNet with different attack methods and model architectures, and show near-perfect detection with low rates of false detection.