 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicEval-XL: Bridging Linguistic Diversity in Code Generation Across Indic Languages
Feb 26, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation from natural language prompts, revolutionizing software development workflows. As we advance towards agent-based development paradigms, these models form the cornerstone of next-generation software development lifecycles. However, current benchmarks for evaluating multilingual code generation capabilities are predominantly English-centric, limiting their applicability across the global developer community. To address this limitation, we present IndicEval-XL, a comprehensive benchmark for code generation that incorporates 6 major Indic languages, collectively spoken by approximately 14\% of the world's population. Our benchmark bridges these languages with 12 programming languages, creating a robust evaluation framework. This work is particularly significant given India's representation of one-eighth of the global population and the crucial role Indic languages play in Indian society. IndicEval-XL represents a significant step toward expanding the linguistic diversity in code generation systems and evaluation frameworks. By developing resources that support multiple languages, we aim to make AI-powered development tools more inclusive and accessible to developers of various linguistic backgrounds. To facilitate further research and development in this direction, we make our dataset and evaluation benchmark publicly available at https://github.com/telekom/IndicEval-XL
Covidex: Neural Ranking Models and Keyword Search Infrastructure for the COVID-19 Open Research Dataset
Jul 14, 2020

We present Covidex, a search engine that exploits the latest neural ranking models to provide information access to the COVID-19 Open Research Dataset curated by the Allen Institute for AI. Our system has been online and serving users since late March 2020. The Covidex is the user application component of our three-pronged strategy to develop technologies for helping domain experts tackle the ongoing global pandemic. In addition, we provide robust and easy-to-use keyword search infrastructure that exploits mature fusion-based methods as well as standalone neural ranking models that can be incorporated into other applications. These techniques have been evaluated in the ongoing TREC-COVID challenge: Our infrastructure and baselines have been adopted by many participants, including some of the highest-scoring runs in rounds 1, 2, and 3. In round 3, we report the highest-scoring run that takes advantage of previous training data and the second-highest fully automatic run.
Unsupervised Learning of KB Queries in Task Oriented Dialogs
Apr 30, 2020



Task-oriented dialog (TOD) systems converse with users to accomplish a specific task. This task requires the system to query a knowledge base (KB) and use the retrieved results to fulfil user needs. Predicting the KB queries is crucial and can lead to severe under-performance if made incorrectly. KB queries are usually annotated in real-world datasets and are learnt using supervised approaches to achieve acceptable task completion. This need for query annotations prevents TOD systems from easily adapting to new domains. In this paper, we propose a novel problem of learning end-to-end TOD systems using dialogs that do not contain KB query annotations. Our approach first learns to predict the KB queries using reinforcement learning (RL) and then learns the end-to-end system using the predicted queries. However, predicting the correct query in TOD systems is uniquely plagued by correlated attributes, in which, due to data bias, certain attributes always occur together in the KB. This prevents the RL system to generalise and accuracy suffers as a result. We propose Correlated Attributes Resilient RL (CARRL), a modification to the RL gradient estimation, which mitigates the problem of correlated attributes and predicts KB queries better than existing weakly supervised approaches. Finally, we compare the performance of our end-to-end system trained using predicted queries to a system trained using annotated gold queries.
Rapidly Bootstrapping a Question Answering Dataset for COVID-19
Apr 23, 2020
We present CovidQA, the beginnings of a question answering dataset specifically designed for COVID-19, built by hand from knowledge gathered from Kaggle's COVID-19 Open Research Dataset Challenge. To our knowledge, this is the first publicly available resource of its type, and intended as a stopgap measure for guiding research until more substantial evaluation resources become available. While this dataset, comprising 124 question-article pairs as of the present version 0.1 release, does not have sufficient examples for supervised machine learning, we believe that it can be helpful for evaluating the zero-shot or transfer capabilities of existing models on topics specifically related to COVID-19. This paper describes our methodology for constructing the dataset and presents the effectiveness of a number of baselines, including term-based techniques and various transformer-based models. The dataset is available at http://covidqa.ai/
Rapidly Deploying a Neural Search Engine for the COVID-19 Open Research Dataset: Preliminary Thoughts and Lessons Learned
Apr 10, 2020

We present the Neural Covidex, a search engine that exploits the latest neural ranking architectures to provide information access to the COVID-19 Open Research Dataset curated by the Allen Institute for AI. This web application exists as part of a suite of tools that we have developed over the past few weeks to help domain experts tackle the ongoing global pandemic. We hope that improved information access capabilities to the scientific literature can inform evidence-based decision making and insight generation. This paper describes our initial efforts and offers a few thoughts about lessons we have learned along the way.
Hierarchical-Pointer Generator Memory Network for Task Oriented Dialog
Jul 11, 2018

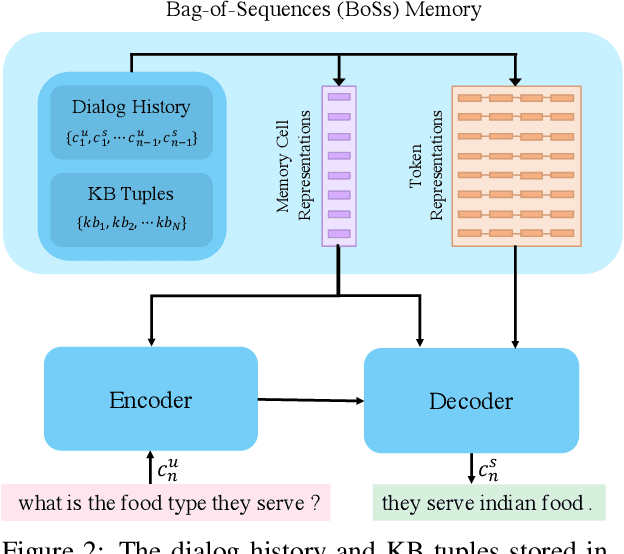
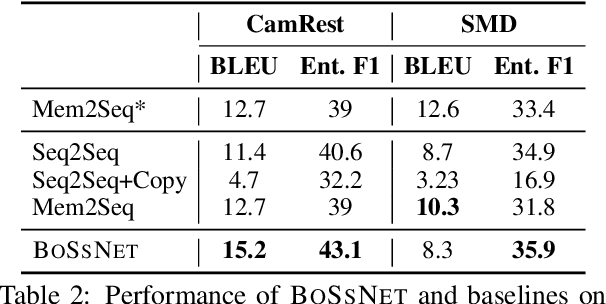
End-to-end networks trained for task-oriented dialog, such as for recommending restaurants to a user, suffer from out-of-vocabulary (OOV) problem -- the entities in the Knowledge Base (KB) may not be seen by the network at training time, making it hard to use them in dialog. We propose a novel Hierarchical Pointer Generator Memory Network (HyP-MN), in which the next word may be generated from the decode vocabulary or copied from a hierarchical memory maintaining KB results and previous utterances. This hierarchical memory layout along with a novel KB dropout helps to alleviate the OOV problem. Evaluating over the dialog bAbI tasks, we find that HyP-MN outperforms state-of-the-art results, with considerable improvements (10% on OOV test set). HyP-MN also achieves competitive performances on various real-world datasets such as CamRest676 and In-car assistant dataset.