 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrid-World Representations in Transformers Reflect Predictive Geometry
Mar 17, 2026Next-token predictors often appear to develop internal representations of the latent world and its rules. The probabilistic nature of these models suggests a deep connection between the structure of the world and the geometry of probability distributions. In order to understand this link more precisely, we use a minimal stochastic process as a controlled setting: constrained random walks on a two-dimensional lattice that must reach a fixed endpoint after a predetermined number of steps. Optimal prediction of this process solely depends on a sufficient vector determined by the walker's position relative to the target and the remaining time horizon; in other words, the probability distributions are parametrized by the world's geometry. We train decoder-only transformers on prefixes sampled from the exact distribution of these walks and compare their hidden activations to the analytically derived sufficient vectors. Across models and layers, the learned representations align strongly with the ground-truth predictive vectors and are often low-dimensional. This provides a concrete example in which world-model-like representations can be directly traced back to the predictive geometry of the data itself. Although demonstrated in a simplified toy system, the analysis suggests that geometric representations supporting optimal prediction may provide a useful lens for studying how neural networks internalize grammatical and other structural constraints.
Relative Geometry of Neural Forecasters: Linking Accuracy and Alignment in Learned Latent Geometry
Feb 17, 2026Neural networks can accurately forecast complex dynamical systems, yet how they internally represent underlying latent geometry remains poorly understood. We study neural forecasters through the lens of representational alignment, introducing anchor-based, geometry-agnostic relative embeddings that remove rotational and scaling ambiguities in latent spaces. Applying this framework across seven canonical dynamical systems - ranging from periodic to chaotic - we reveal reproducible family-level structure: multilayer perceptrons align with other MLPs, recurrent networks with RNNs, while transformers and echo-state networks achieve strong forecasts despite weaker alignment. Alignment generally correlates with forecasting accuracy, yet high accuracy can coexist with low alignment. Relative geometry thus provides a simple, reproducible foundation for comparing how model families internalize and represent dynamical structure.
Stochastic Decision Horizons for Constrained Reinforcement Learning
Feb 04, 2026Constrained Markov decision processes (CMDPs) provide a principled model for handling constraints, such as safety and other auxiliary objectives, in reinforcement learning. The common approach of using additive-cost constraints and dual variables often hinders off-policy scalability. We propose a Control as Inference formulation based on stochastic decision horizons, where constraint violations attenuate reward contributions and shorten the effective planning horizon via state-action-dependent continuation. This yields survival-weighted objectives that remain replay-compatible for off-policy actor-critic learning. We propose two violation semantics, absorbing and virtual termination, that share the same survival-weighted return but result in distinct optimization structures that lead to SAC/MPO-style policy improvement. Experiments demonstrate improved sample efficiency and favorable return-violation trade-offs on standard benchmarks. Moreover, MPO with virtual termination (VT-MPO) scales effectively to our high-dimensional musculoskeletal Hyfydy setup.
Physical Embodiment Enables Information Processing Beyond Explicit Sensing in Active Matter
Aug 25, 2025Living microorganisms have evolved dedicated sensory machinery to detect environmental perturbations, processing these signals through biochemical networks to guide behavior. Replicating such capabilities in synthetic active matter remains a fundamental challenge. Here, we demonstrate that synthetic active particles can adapt to hidden hydrodynamic perturbations through physical embodiment alone, without explicit sensing mechanisms. Using reinforcement learning to control self-thermophoretic particles, we show that they learn navigation strategies to counteract unobserved flow fields by exploiting information encoded in their physical dynamics. Remarkably, particles successfully navigate perturbations that are not included in their state inputs, revealing that embodied dynamics can serve as an implicit sensing mechanism. This discovery establishes physical embodiment as a computational resource for information processing in active matter, with implications for autonomous microrobotic systems and bio-inspired computation.
Multimodal Recurrent Ensembles for Predicting Brain Responses to Naturalistic Movies (Algonauts 2025)
Jul 23, 2025


Accurately predicting distributed cortical responses to naturalistic stimuli requires models that integrate visual, auditory and semantic information over time. We present a hierarchical multimodal recurrent ensemble that maps pretrained video, audio, and language embeddings to fMRI time series recorded while four subjects watched almost 80 hours of movies provided by the Algonauts 2025 challenge. Modality-specific bidirectional RNNs encode temporal dynamics; their hidden states are fused and passed to a second recurrent layer, and lightweight subject-specific heads output responses for 1000 cortical parcels. Training relies on a composite MSE-correlation loss and a curriculum that gradually shifts emphasis from early sensory to late association regions. Averaging 100 model variants further boosts robustness. The resulting system ranked third on the competition leaderboard, achieving an overall Pearson r = 0.2094 and the highest single-parcel peak score (mean r = 0.63) among all participants, with particularly strong gains for the most challenging subject (Subject 5). The approach establishes a simple, extensible baseline for future multimodal brain-encoding benchmarks.
Exploring Geometric Representational Alignment through Ollivier-Ricci Curvature and Ricci Flow
Jan 01, 2025

Representational analysis explores how input data of a neural system are encoded in high dimensional spaces of its distributed neural activations, and how we can compare different systems, for instance, artificial neural networks and brains, on those grounds. While existing methods offer important insights, they typically do not account for local intrinsic geometrical properties within the high-dimensional representation spaces. To go beyond these limitations, we explore Ollivier-Ricci curvature and Ricci flow as tools to study the alignment of representations between humans and artificial neural systems on a geometric level. As a proof-of-principle study, we compared the representations of face stimuli between VGG-Face, a human-aligned version of VGG-Face, and corresponding human similarity judgments from a large online study. Using this discrete geometric framework, we were able to identify local structural similarities and differences by examining the distributions of node and edge curvature and higher-level properties by detecting and comparing community structure in the representational graphs.
Fair Distributed Machine Learning with Imbalanced Data as a Stackelberg Evolutionary Game
Dec 20, 2024
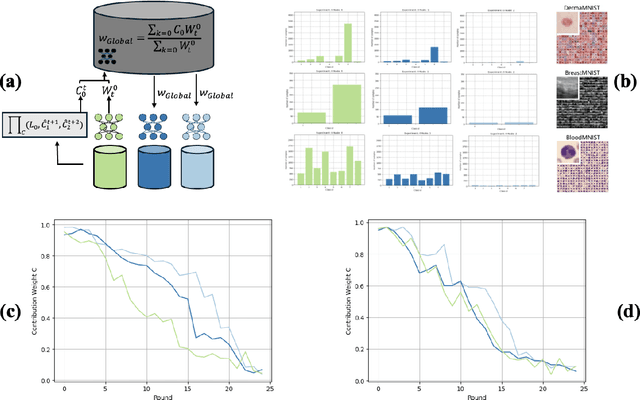
Decentralised learning enables the training of deep learning algorithms without centralising data sets, resulting in benefits such as improved data privacy, operational efficiency and the fostering of data ownership policies. However, significant data imbalances pose a challenge in this framework. Participants with smaller datasets in distributed learning environments often achieve poorer results than participants with larger datasets. Data imbalances are particularly pronounced in medical fields and are caused by different patient populations, technological inequalities and divergent data collection practices. In this paper, we consider distributed learning as an Stackelberg evolutionary game. We present two algorithms for setting the weights of each node's contribution to the global model in each training round: the Deterministic Stackelberg Weighting Model (DSWM) and the Adaptive Stackelberg Weighting Model (ASWM). We use three medical datasets to highlight the impact of dynamic weighting on underrepresented nodes in distributed learning. Our results show that the ASWM significantly favours underrepresented nodes by improving their performance by 2.713% in AUC. Meanwhile, nodes with larger datasets experience only a modest average performance decrease of 0.441%.
Embedding Safety into RL: A New Take on Trust Region Methods
Nov 05, 2024



Reinforcement Learning (RL) agents are able to solve a wide variety of tasks but are prone to producing unsafe behaviors. Constrained Markov Decision Processes (CMDPs) provide a popular framework for incorporating safety constraints. However, common solution methods often compromise reward maximization by being overly conservative or allow unsafe behavior during training. We propose Constrained Trust Region Policy Optimization (C-TRPO), a novel approach that modifies the geometry of the policy space based on the safety constraints and yields trust regions composed exclusively of safe policies, ensuring constraint satisfaction throughout training. We theoretically study the convergence and update properties of C-TRPO and highlight connections to TRPO, Natural Policy Gradient (NPG), and Constrained Policy Optimization (CPO). Finally, we demonstrate experimentally that C-TRPO significantly reduces constraint violations while achieving competitive reward maximization compared to state-of-the-art CMDP algorithms.
Revealing the learning process in reinforcement learning agents through attention-oriented metrics
Jun 20, 2024



The learning process of a reinforcement learning (RL) agent remains poorly understood beyond the mathematical formulation of its learning algorithm. To address this gap, we introduce attention-oriented metrics (ATOMs) to investigate the development of an RL agent's attention during training. We tested ATOMs on three variations of a Pong game, each designed to teach the agent distinct behaviours, complemented by a behavioural assessment. Our findings reveal that ATOMs successfully delineate the attention patterns of an agent trained on each game variation, and that these differences in attention patterns translate into differences in the agent's behaviour. Through continuous monitoring of ATOMs during training, we observed that the agent's attention developed in phases, and that these phases were consistent across games. Finally, we noted that the agent's attention to its paddle emerged relatively late in the training and coincided with a marked increase in its performance score. Overall, we believe that ATOMs could significantly enhance our understanding of RL agents' learning processes, which is essential for improving their reliability and efficiency.
Open Problem: Active Representation Learning
Jun 06, 2024
In this work, we introduce the concept of Active Representation Learning, a novel class of problems that intertwines exploration and representation learning within partially observable environments. We extend ideas from Active Simultaneous Localization and Mapping (active SLAM), and translate them to scientific discovery problems, exemplified by adaptive microscopy. We explore the need for a framework that derives exploration skills from representations that are in some sense actionable, aiming to enhance the efficiency and effectiveness of data collection and model building in the natural sciences.