 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Distributed Machine Learning with Imbalanced Data as a Stackelberg Evolutionary Game
Dec 20, 2024
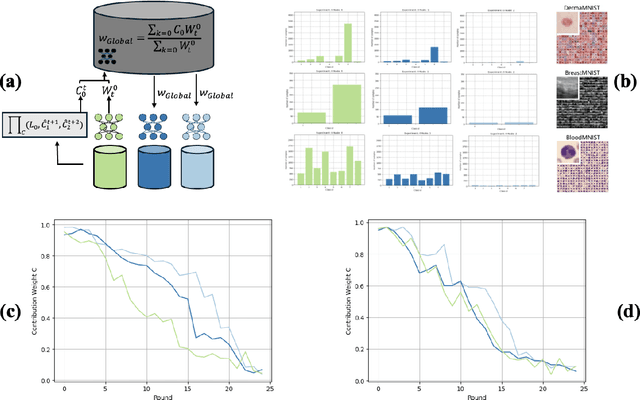
Decentralised learning enables the training of deep learning algorithms without centralising data sets, resulting in benefits such as improved data privacy, operational efficiency and the fostering of data ownership policies. However, significant data imbalances pose a challenge in this framework. Participants with smaller datasets in distributed learning environments often achieve poorer results than participants with larger datasets. Data imbalances are particularly pronounced in medical fields and are caused by different patient populations, technological inequalities and divergent data collection practices. In this paper, we consider distributed learning as an Stackelberg evolutionary game. We present two algorithms for setting the weights of each node's contribution to the global model in each training round: the Deterministic Stackelberg Weighting Model (DSWM) and the Adaptive Stackelberg Weighting Model (ASWM). We use three medical datasets to highlight the impact of dynamic weighting on underrepresented nodes in distributed learning. Our results show that the ASWM significantly favours underrepresented nodes by improving their performance by 2.713% in AUC. Meanwhile, nodes with larger datasets experience only a modest average performance decrease of 0.441%.
Quality control for more reliable integration of deep learning-based image segmentation into medical workflows
Dec 06, 2021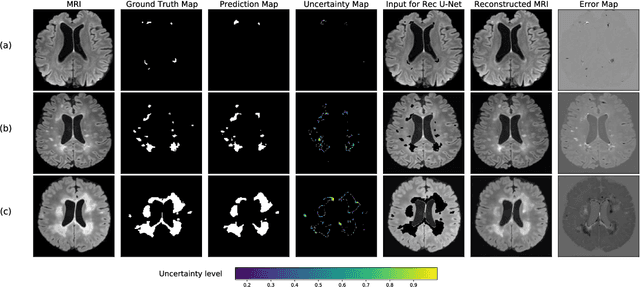

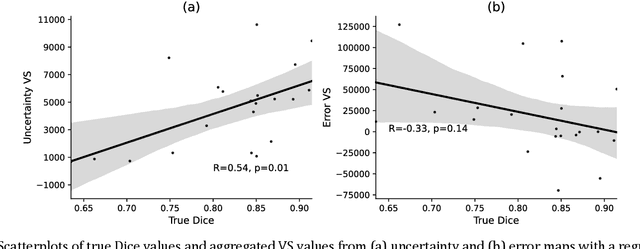
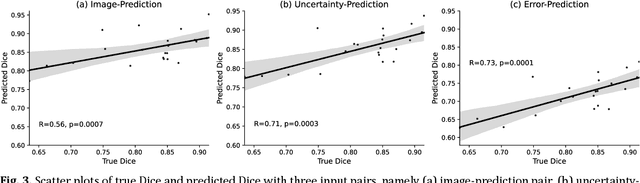
Machine learning algorithms underpin modern diagnostic-aiding software, which has proved valuable in clinical practice, particularly in radiology. However, inaccuracies, mainly due to the limited availability of clinical samples for training these algorithms, hamper their wider applicability, acceptance, and recognition amongst clinicians. We present an analysis of state-of-the-art automatic quality control (QC) approaches that can be implemented within these algorithms to estimate the certainty of their outputs. We validated the most promising approaches on a brain image segmentation task identifying white matter hyperintensities (WMH) in magnetic resonance imaging data. WMH are a correlate of small vessel disease common in mid-to-late adulthood and are particularly challenging to segment due to their varied size, and distributional patterns. Our results show that the aggregation of uncertainty and Dice prediction were most effective in failure detection for this task. Both methods independently improved mean Dice from 0.82 to 0.84. Our work reveals how QC methods can help to detect failed segmentation cases and therefore make automatic segmentation more reliable and suitable for clinical practice.
A comparative study of semi- and self-supervised semantic segmentation of biomedical microscopy data
Nov 23, 2020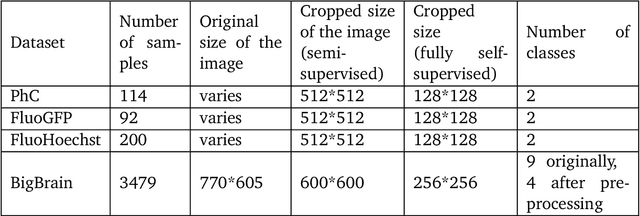


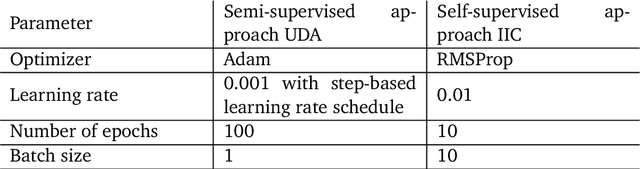
In recent years, Convolutional Neural Networks (CNNs) have become the state-of-the-art method for biomedical image analysis. However, these networks are usually trained in a supervised manner, requiring large amounts of labelled training data. These labelled data sets are often difficult to acquire in the biomedical domain. In this work, we validate alternative ways to train CNNs with fewer labels for biomedical image segmentation using. We adapt two semi- and self-supervised image classification methods and analyse their performance for semantic segmentation of biomedical microscopy images.
Convolutional neural network stacking for medical image segmentation in CT scans
Jul 23, 2019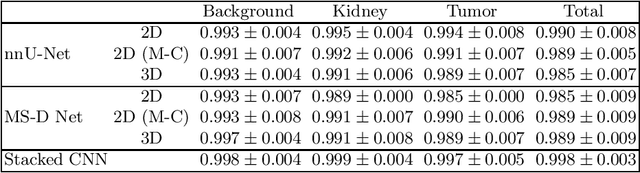
Computed tomography (CT) data poses many challenges to medical image segmentation based on convolutional neural networks(CNNs). The main challenges in handling CT scans with CNN are the scale of data (large range of Hounsfield Units) and the processing of the slices. In this paper, we consider a framework, which addresses these demands regarding the data pre-processing, the data augmentation, and the CNN architecture itself. For this purpose, we present a data preprocessing and an augmentation method tailored to CT data. We evaluate and compare different input dimensionalities and two different CNN architectures. One of the architectures is a modified U-Net and the other a modified Mixed-Scale Dense Network (MS-D Net). Thus, we compare dilated convolutions for parallel multi-scale processing to the U-Net approach with traditional scaling operations based on the different input dimensionalities. Finally, we merge a set of 3D modified MS-D Nets and a set of 2D modified U-Nets as a stacked CNN-model to combine the different strengths of both model.
Multi-Stage Reinforcement Learning For Object Detection
Oct 26, 2018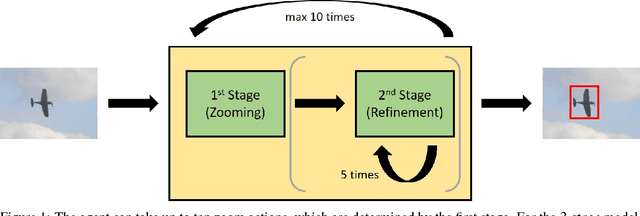
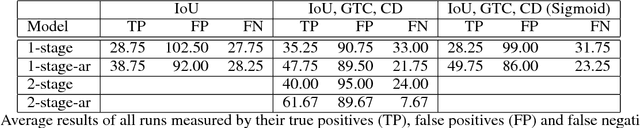
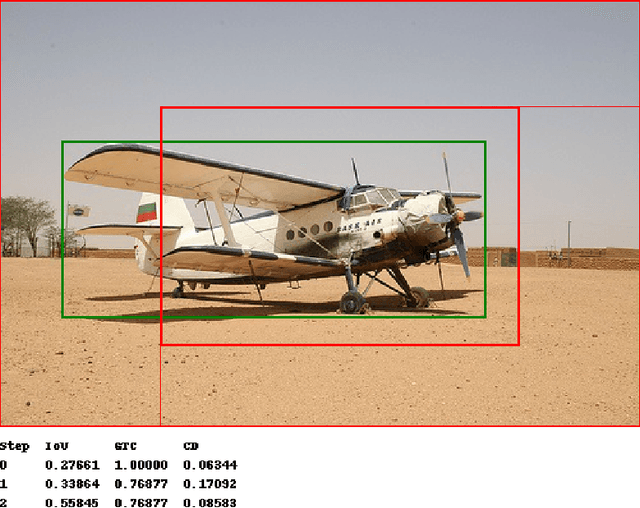
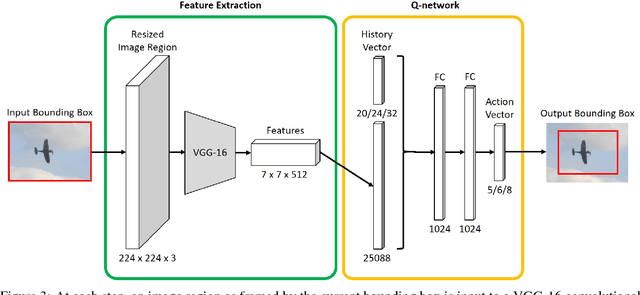
We present a reinforcement learning approach for detecting objects within an image. Our approach performs a step-wise deformation of a bounding box with the goal of tightly framing the object. It uses a hierarchical tree-like representation of predefined region candidates, which the agent can zoom in on. This reduces the number of region candidates that must be evaluated so that the agent can afford to compute new feature maps before each step to enhance detection quality. We compare an approach that is based purely on zoom actions with one that is extended by a second refinement stage to fine-tune the bounding box after each zoom step. We also improve the fitting ability by allowing for different aspect ratios of the bounding box. Finally, we propose different reward functions to lead to a better guidance of the agent while following its search trajectories. Experiments indicate that each of these extensions leads to more correct detections. The best performing approach comprises a zoom stage and a refinement stage, uses aspect-ratio modifying actions and is trained using a combination of three different reward metrics.