 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Play Learning Without a Reward Metric
Dec 16, 2019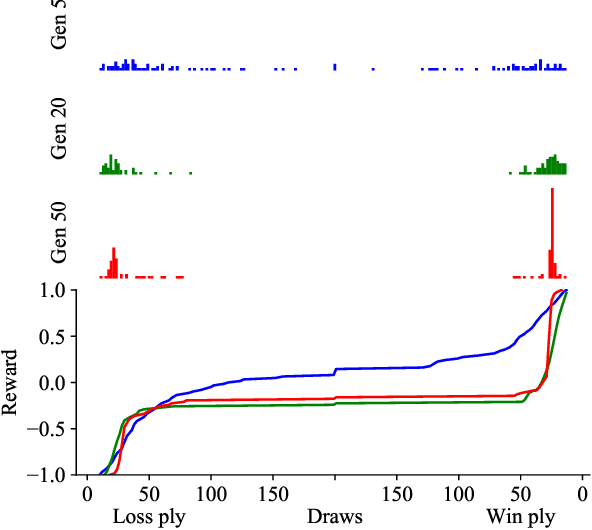
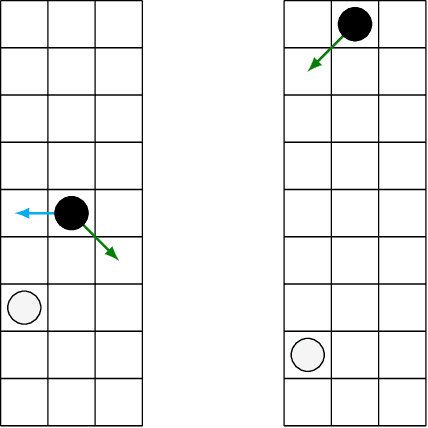
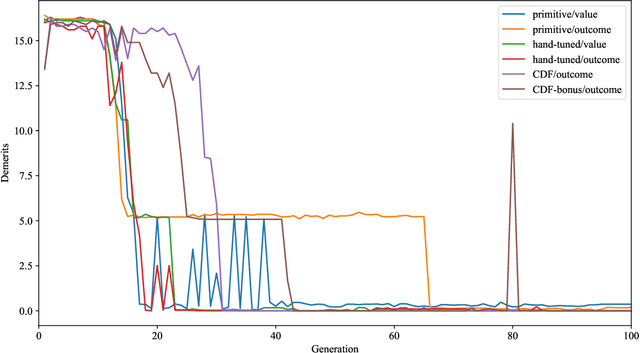

The AlphaZero algorithm for the learning of strategy games via self-play, which has produced superhuman ability in the games of Go, chess, and shogi, uses a quantitative reward function for game outcomes, requiring the users of the algorithm to explicitly balance different components of the reward against each other, such as the game winner and margin of victory. We present a modification to the AlphaZero algorithm that requires only a total ordering over game outcomes, obviating the need to perform any quantitative balancing of reward components. We demonstrate that this system learns optimal play in a comparable amount of time to AlphaZero on a sample game.
Noisier2Noise: Learning to Denoise from Unpaired Noisy Data
Oct 25, 2019
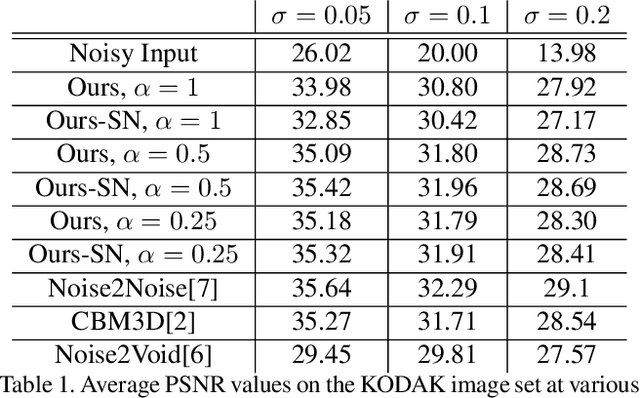

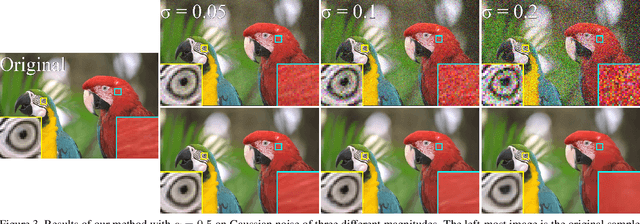
We present a method for training a neural network to perform image denoising without access to clean training examples or access to paired noisy training examples. Our method requires only a single noisy realization of each training example and a statistical model of the noise distribution, and is applicable to a wide variety of noise models, including spatially structured noise. Our model produces results which are competitive with other learned methods which require richer training data, and outperforms traditional non-learned denoising methods. We present derivations of our method for arbitrary additive noise, an improvement specific to Gaussian additive noise, and an extension to multiplicative Bernoulli noise.
Reconstructing Network Inputs with Additive Perturbation Signatures
Apr 11, 2019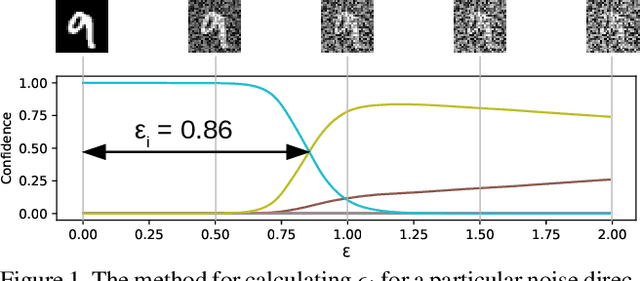


In this work, we present preliminary results demonstrating the ability to recover a significant amount of information about secret model inputs given only very limited access to model outputs and the ability evaluate the model on additive perturbations to the input.
Coevolutionary Neural Population Models
Apr 11, 2018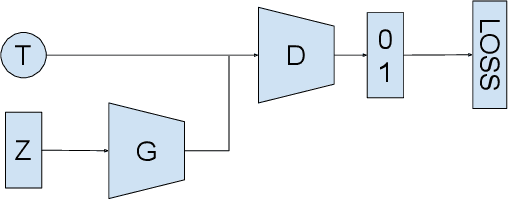
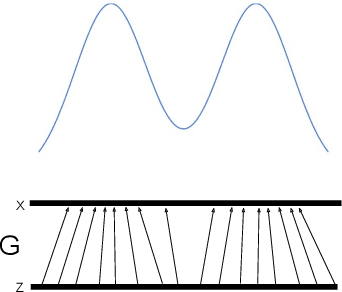

We present a method for using neural networks to model evolutionary population dynamics, and draw parallels to recent deep learning advancements in which adversarially-trained neural networks engage in coevolutionary interactions. We conduct experiments which demonstrate that models from evolutionary game theory are capable of describing the behavior of these neural population systems.
Deflecting Adversarial Attacks with Pixel Deflection
Mar 30, 2018
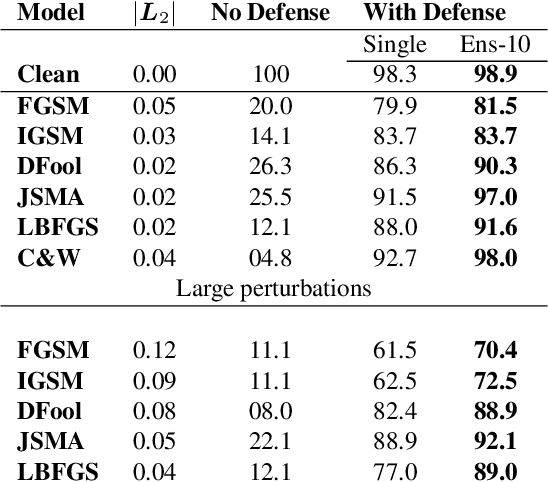
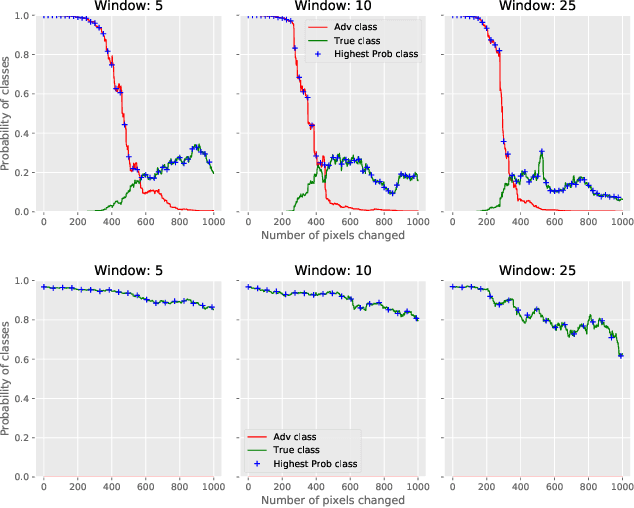
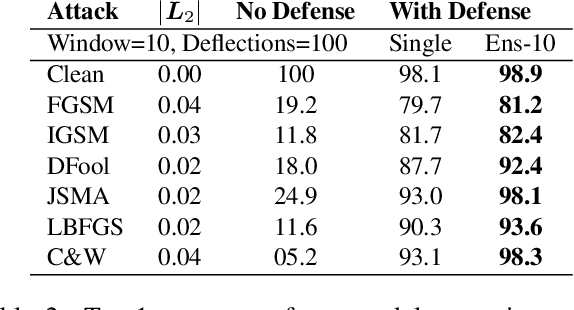
CNNs are poised to become integral parts of many critical systems. Despite their robustness to natural variations, image pixel values can be manipulated, via small, carefully crafted, imperceptible perturbations, to cause a model to misclassify images. We present an algorithm to process an image so that classification accuracy is significantly preserved in the presence of such adversarial manipulations. Image classifiers tend to be robust to natural noise, and adversarial attacks tend to be agnostic to object location. These observations motivate our strategy, which leverages model robustness to defend against adversarial perturbations by forcing the image to match natural image statistics. Our algorithm locally corrupts the image by redistributing pixel values via a process we term pixel deflection. A subsequent wavelet-based denoising operation softens this corruption, as well as some of the adversarial changes. We demonstrate experimentally that the combination of these techniques enables the effective recovery of the true class, against a variety of robust attacks. Our results compare favorably with current state-of-the-art defenses, without requiring retraining or modifying the CNN.
Protecting JPEG Images Against Adversarial Attacks
Mar 02, 2018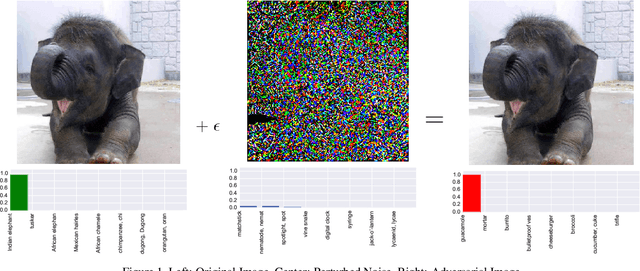
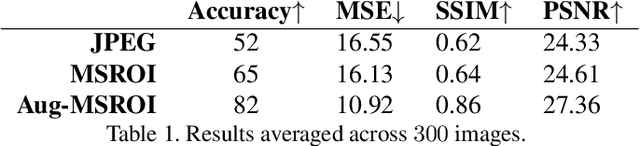
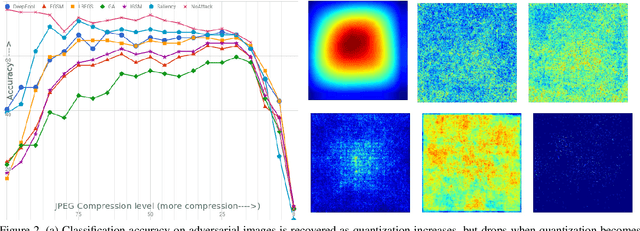
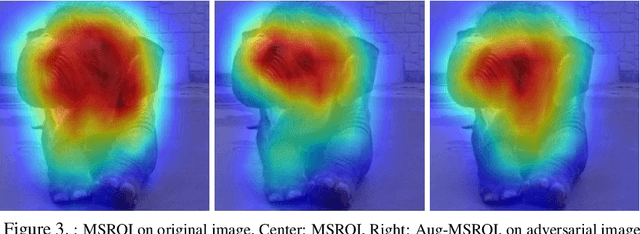
As deep neural networks (DNNs) have been integrated into critical systems, several methods to attack these systems have been developed. These adversarial attacks make imperceptible modifications to an image that fool DNN classifiers. We present an adaptive JPEG encoder which defends against many of these attacks. Experimentally, we show that our method produces images with high visual quality while greatly reducing the potency of state-of-the-art attacks. Our algorithm requires only a modest increase in encoding time, produces a compressed image which can be decompressed by an off-the-shelf JPEG decoder, and classified by an unmodified classifier
Semantic Perceptual Image Compression using Deep Convolution Networks
Mar 29, 2017
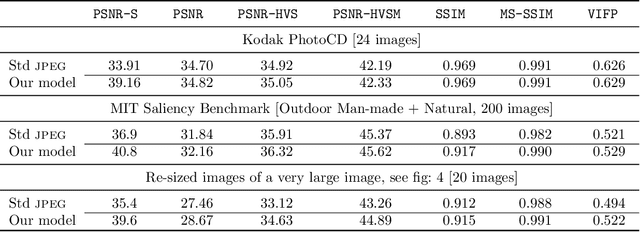


It has long been considered a significant problem to improve the visual quality of lossy image and video compression. Recent advances in computing power together with the availability of large training data sets has increased interest in the application of deep learning cnns to address image recognition and image processing tasks. Here, we present a powerful cnn tailored to the specific task of semantic image understanding to achieve higher visual quality in lossy compression. A modest increase in complexity is incorporated to the encoder which allows a standard, off-the-shelf jpeg decoder to be used. While jpeg encoding may be optimized for generic images, the process is ultimately unaware of the specific content of the image to be compressed. Our technique makes jpeg content-aware by designing and training a model to identify multiple semantic regions in a given image. Unlike object detection techniques, our model does not require labeling of object positions and is able to identify objects in a single pass. We present a new cnn architecture directed specifically to image compression, which generates a map that highlights semantically-salient regions so that they can be encoded at higher quality as compared to background regions. By adding a complete set of features for every class, and then taking a threshold over the sum of all feature activations, we generate a map that highlights semantically-salient regions so that they can be encoded at a better quality compared to background regions. Experiments are presented on the Kodak PhotoCD dataset and the MIT Saliency Benchmark dataset, in which our algorithm achieves higher visual quality for the same compressed size.