 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAliCG: Fine-grained and Evolvable Conceptual Graph Construction for Semantic Search at Alibaba
Jun 03, 2021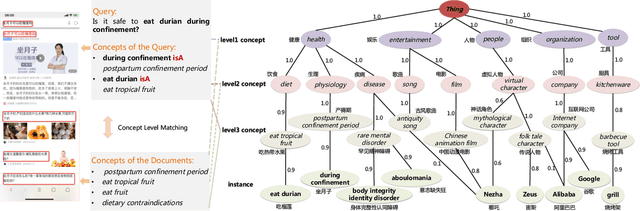
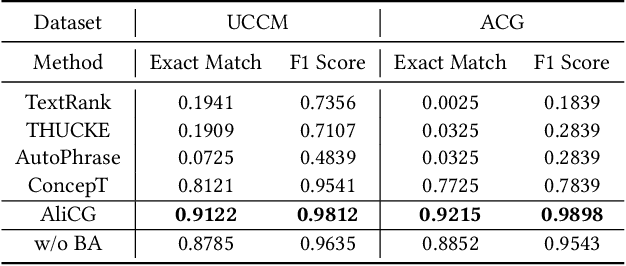
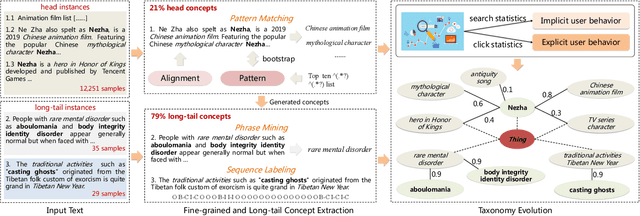

Conceptual graphs, which is a particular type of Knowledge Graphs, play an essential role in semantic search. Prior conceptual graph construction approaches typically extract high-frequent, coarse-grained, and time-invariant concepts from formal texts. In real applications, however, it is necessary to extract less-frequent, fine-grained, and time-varying conceptual knowledge and build taxonomy in an evolving manner. In this paper, we introduce an approach to implementing and deploying the conceptual graph at Alibaba. Specifically, We propose a framework called AliCG which is capable of a) extracting fine-grained concepts by a novel bootstrapping with alignment consensus approach, b) mining long-tail concepts with a novel low-resource phrase mining approach, c) updating the graph dynamically via a concept distribution estimation method based on implicit and explicit user behaviors. We have deployed the framework at Alibaba UC Browser. Extensive offline evaluation as well as online A/B testing demonstrate the efficacy of our approach.
Conceptualized Representation Learning for Chinese Biomedical Text Mining
Aug 25, 2020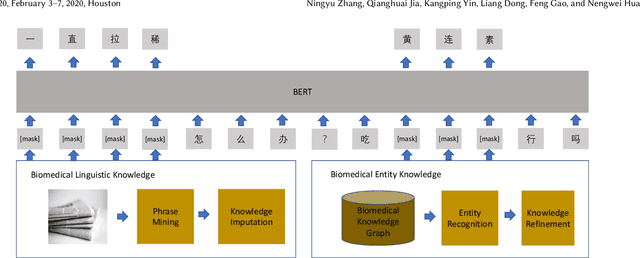

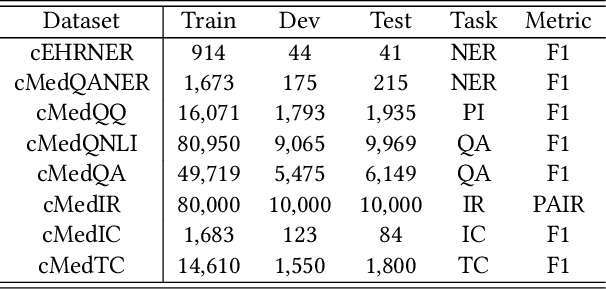
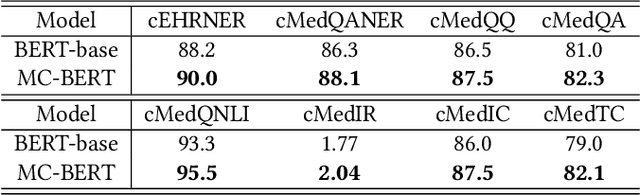
Biomedical text mining is becoming increasingly important as the number of biomedical documents and web data rapidly grows. Recently, word representation models such as BERT has gained popularity among researchers. However, it is difficult to estimate their performance on datasets containing biomedical texts as the word distributions of general and biomedical corpora are quite different. Moreover, the medical domain has long-tail concepts and terminologies that are difficult to be learned via language models. For the Chinese biomedical text, it is more difficult due to its complex structure and the variety of phrase combinations. In this paper, we investigate how the recently introduced pre-trained language model BERT can be adapted for Chinese biomedical corpora and propose a novel conceptualized representation learning approach. We also release a new Chinese Biomedical Language Understanding Evaluation benchmark (\textbf{ChineseBLUE}). We examine the effectiveness of Chinese pre-trained models: BERT, BERT-wwm, RoBERTa, and our approach. Experimental results on the benchmark show that our approach could bring significant gain. We release the pre-trained model on GitHub: https://github.com/alibaba-research/ChineseBLUE.
Context-aware Deep Model for Entity Recommendation in Search Engine at Alibaba
Sep 06, 2019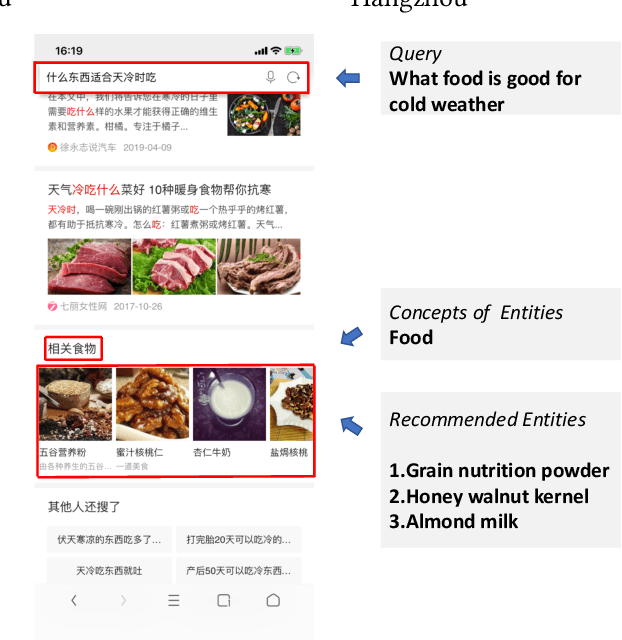
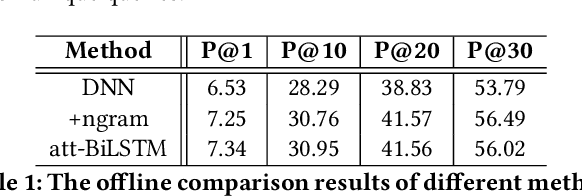
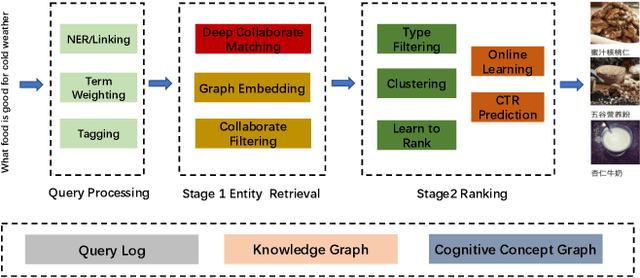
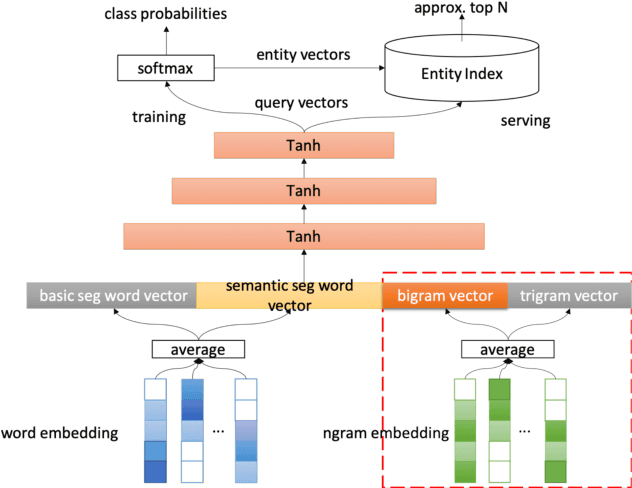
Entity recommendation, providing search users with an improved experience via assisting them in finding related entities for a given query, has become an indispensable feature of today's search engines. Existing studies typically only consider the queries with explicit entities. They usually fail to handle complex queries that without entities, such as "what food is good for cold weather", because their models could not infer the underlying meaning of the input text. In this work, we believe that contexts convey valuable evidence that could facilitate the semantic modeling of queries, and take them into consideration for entity recommendation. In order to better model the semantics of queries and entities, we learn the representation of queries and entities jointly with attentive deep neural networks. We evaluate our approach using large-scale, real-world search logs from a widely used commercial Chinese search engine. Our system has been deployed in ShenMa Search Engine and you can fetch it in UC Browser of Alibaba. Results from online A/B test suggest that the impression efficiency of click-through rate increased by 5.1% and page view increased by 5.5%.