 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Stage Warm-Start Deep Learning Framework for Unit Commitment
Apr 23, 2026Maintaining instantaneous balance between electricity supply and demand is critical for reliability and grid instability. System operators achieve this through solving the task of Unit Commitment (UC),ca high dimensional large-scale Mixed-integer Linear Programming (MILP) problem that is strictly and heavily governed by the grid physical constraints. As grid integrate variable renewable sources, and new technologies such as long duration storage in the grid, UC must be optimally solved for multi-day horizons and potentially with greater frequency. Therefore, traditional MILP solvers increasingly struggle to compute solutions within these tightening operational time limits. To bypass these computational bottlenecks, this paper proposes a novel framework utilizing a transformer-based architecture to predict generator commitment schedules over a 72-hour horizon. Also, because raw predictions in highly dimensional spaces often yield physically infeasible results, the pipeline integrates the self-attention network with deterministic post-processing heuristics that systematically enforce minimum up/down times and minimize excess capacity. Finally, these refined predictions are utilized as a warm start for a downstream MILP solver, while employing a confidence-based variable fixation strategy to drastically reduce the combinatorial search space. Validated on a single-bus test system, the complete multi-stage pipeline achieves 100\% feasibility and significantly accelerates computation times. Notably, in approximately 20\% of test instances, the proposed model reached a feasible operational schedule with a lower overall system cost than relying solely on the solver.
Leveraging Multi-Task Learning for Multi-Label Power System Security Assessment
May 09, 2025This paper introduces a novel approach to the power system security assessment using Multi-Task Learning (MTL), and reformulating the problem as a multi-label classification task. The proposed MTL framework simultaneously assesses static, voltage, transient, and small-signal stability, improving both accuracy and interpretability with respect to the most state of the art machine learning methods. It consists of a shared encoder and multiple decoders, enabling knowledge transfer between stability tasks. Experiments on the IEEE 68-bus system demonstrate a measurable superior performance of the proposed method compared to the extant state-of-the-art approaches.
Semi-Supervised Multi-Task Learning Based Framework for Power System Security Assessment
Jul 11, 2024



This paper develops a novel machine learning-based framework using Semi-Supervised Multi-Task Learning (SS-MTL) for power system dynamic security assessment that is accurate, reliable, and aware of topological changes. The learning algorithm underlying the proposed framework integrates conditional masked encoders and employs multi-task learning for classification-aware feature representation, which improves the accuracy and scalability to larger systems. Additionally, this framework incorporates a confidence measure for its predictions, enhancing its reliability and interpretability. A topological similarity index has also been incorporated to add topological awareness to the framework. Various experiments on the IEEE 68-bus system were conducted to validate the proposed method, employing two distinct database generation techniques to generate the required data to train the machine learning algorithm. The results demonstrate that our algorithm outperforms existing state-of-the-art machine learning based techniques for security assessment in terms of accuracy and robustness. Finally, our work underscores the value of employing auto-encoders for security assessment, highlighting improvements in accuracy, reliability, and robustness. All datasets and codes used have been made publicly available to ensure reproducibility and transparency.
Evaluation of Semantic Search and its Role in Retrieved-Augmented-Generation for Arabic Language
Mar 27, 2024The latest advancements in machine learning and deep learning have brought forth the concept of semantic similarity, which has proven immensely beneficial in multiple applications and has largely replaced keyword search. However, evaluating semantic similarity and conducting searches for a specific query across various documents continue to be a complicated task. This complexity is due to the multifaceted nature of the task, the lack of standard benchmarks, whereas these challenges are further amplified for Arabic language. This paper endeavors to establish a straightforward yet potent benchmark for semantic search in Arabic. Moreover, to precisely evaluate the effectiveness of these metrics and the dataset, we conduct our assessment of semantic search within the framework of retrieval augmented generation (RAG).
Arabic Text-To-Speech (TTS) Data Preparation
Apr 07, 2022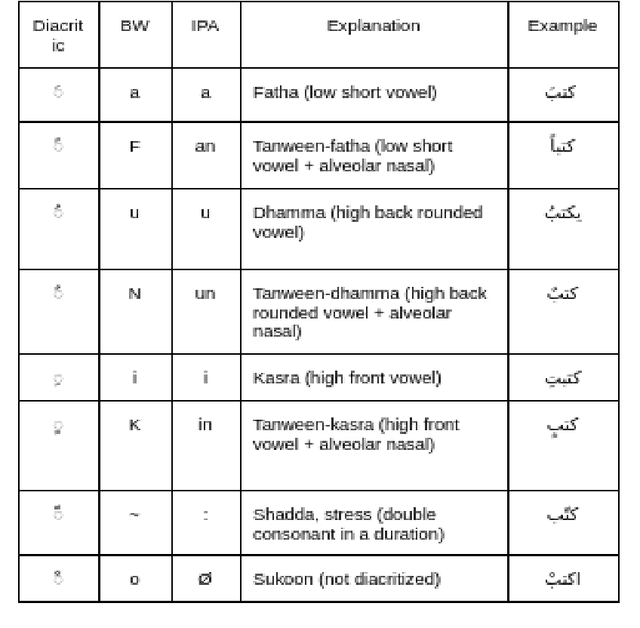
People may be puzzled by the fact that voice over recordings data sets exist in addition to Text-to-Speech (TTS), Synthesis system advancements, albeit this is not the case. The goal of this study is to explain the relevance of TTS as well as the data preparation procedures. TTS relies heavily on recorded data since it can have a substantial influence on the outcomes of TTS modules. Furthermore, whether the domain is specialized or general, appropriate data should be developed to address all predicted language variants and domains. Different recording methodologies, taking into account quality and behavior, may also be advantageous in the development of the module. In light of the lack of Arabic language in present synthesizing systems, numerous variables that impact the flow of recorded utterances are being considered in order to manipulate an Arabic TTS module. In this study, two viewpoints will be discussed: linguistics and the creation of high-quality recordings for TTS. The purpose of this work is to offer light on how ground-truth utterances may influence the evolution of speech systems in terms of naturalness, intelligibility, and understanding. Well provide voice actor specs as well as data specs that will assist both voice actors and voice coaches in the studio as well as the annotators who will be evaluating the audios.
Bench-Marking And Improving Arabic Automatic Image Captioning Through The Use Of Multi-Task Learning Paradigm
Feb 11, 2022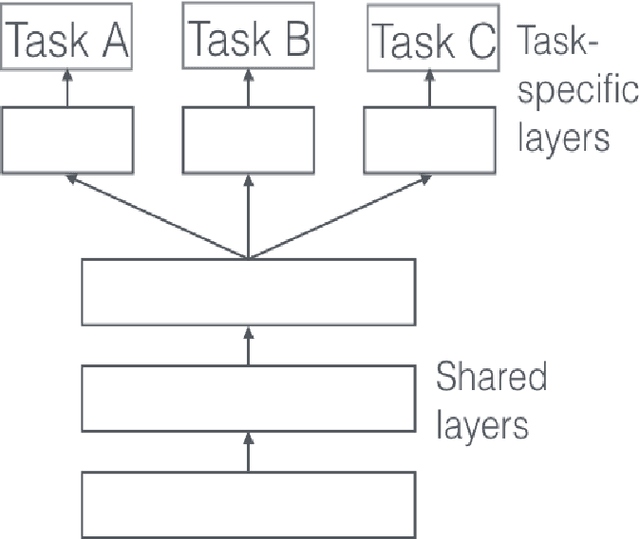

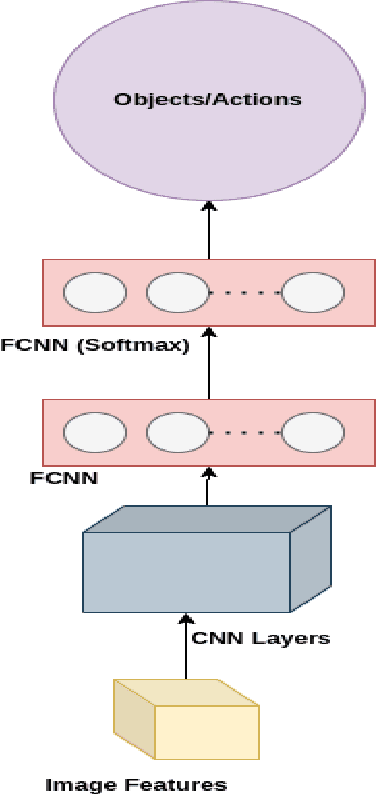
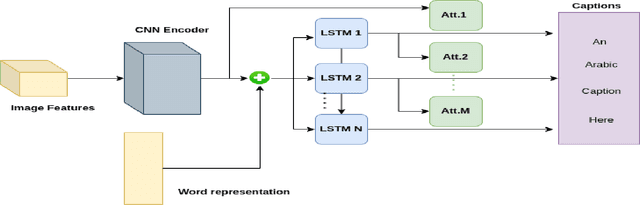
The continuous increase in the use of social media and the visual content on the internet have accelerated the research in computer vision field in general and the image captioning task in specific. The process of generating a caption that best describes an image is a useful task for various applications such as it can be used in image indexing and as a hearing aid for the visually impaired. In recent years, the image captioning task has witnessed remarkable advances regarding both datasets and architectures, and as a result, the captioning quality has reached an astounding performance. However, the majority of these advances especially in datasets are targeted for English, which left other languages such as Arabic lagging behind. Although Arabic language, being spoken by more than 450 million people and being the most growing language on the internet, lacks the fundamental pillars it needs to advance its image captioning research, such as benchmarks or unified datasets. This works is an attempt to expedite the synergy in this task by providing unified datasets and benchmarks, while also exploring methods and techniques that could enhance the performance of Arabic image captioning. The use of multi-task learning is explored, alongside exploring various word representations and different features. The results showed that the use of multi-task learning and pre-trained word embeddings noticeably enhanced the quality of image captioning, however the presented results shows that Arabic captioning still lags behind when compared to the English language. The used dataset and code are available at this link.
sarcasm detection and quantification in arabic tweets
Aug 03, 2021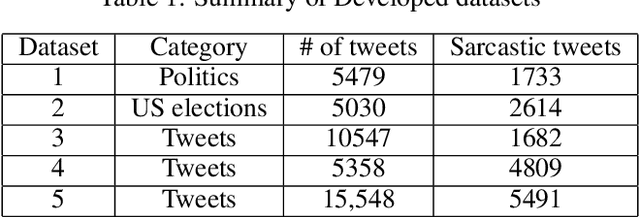
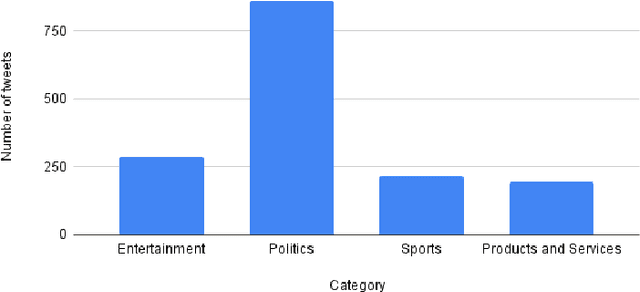
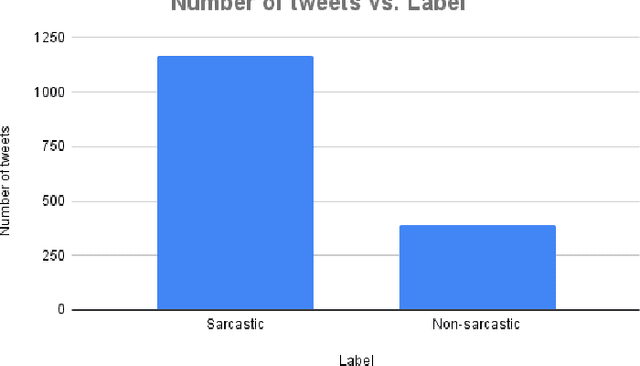

The role of predicting sarcasm in the text is known as automatic sarcasm detection. Given the prevalence and challenges of sarcasm in sentiment-bearing text, this is a critical phase in most sentiment analysis tasks. With the increasing popularity and usage of different social media platforms among users around the world, people are using sarcasm more and more in their day-to-day conversations, social media posts and tweets, and it is considered as a way for people to express their sentiment about some certain topics or issues. As a result of the increasing popularity, researchers started to focus their research endeavors on detecting sarcasm from a text in different languages especially the English language. However, the task of sarcasm detection is a challenging task due to the nature of sarcastic texts; which can be relative and significantly differs from one person to another depending on the topic, region, the user's mentality and other factors. In addition to these challenges, sarcasm detection in the Arabic language has its own challenges due to the complexity of the Arabic language, such as being morphologically rich, with many dialects that significantly vary between each other, while also being lowly resourced. In recent years, only few research attempts started tackling the task of sarcasm detection in Arabic, including creating and collecting corpora, organizing workshops and establishing baseline models. This paper intends to create a new humanly annotated Arabic corpus for sarcasm detection collected from tweets, and implementing a new approach for sarcasm detection and quantification in Arabic tweets. The annotation technique followed in this paper is unique in sarcasm detection and the proposed approach tackles the problem as a regression problem instead of classification; i.e., the model attempts to predict the level of sarcasm instead of binary classification.
SPARTA: Speaker Profiling for ARabic TAlk
Dec 13, 2020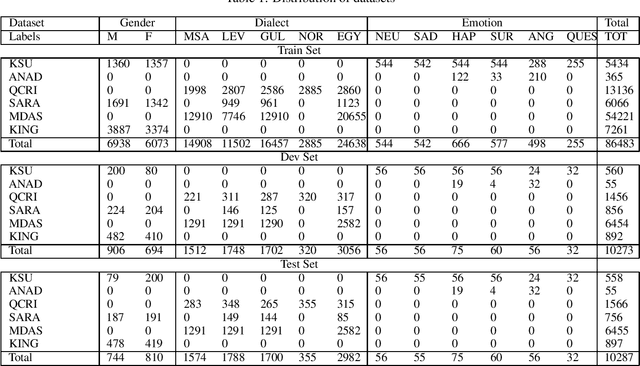
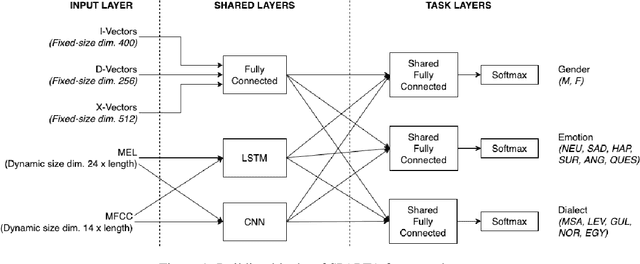

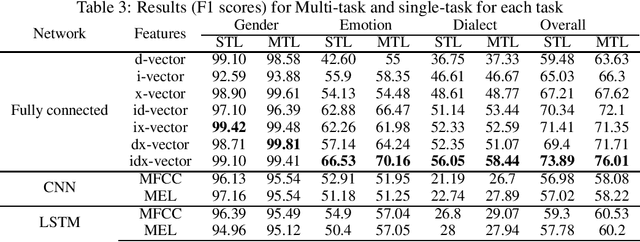
This paper proposes a novel approach to an automatic estimation of three speaker traits from Arabic speech: gender, emotion, and dialect. After showing promising results on different text classification tasks, the multi-task learning (MTL) approach is used in this paper for Arabic speech classification tasks. The dataset was assembled from six publicly available datasets. First, The datasets were edited and thoroughly divided into train, development, and test sets (open to the public), and a benchmark was set for each task and dataset throughout the paper. Then, three different networks were explored: Long Short Term Memory (LSTM), Convolutional Neural Network (CNN), and Fully-Connected Neural Network (FCNN) on five different types of features: two raw features (MFCC and MEL) and three pre-trained vectors (i-vectors, d-vectors, and x-vectors). LSTM and CNN networks were implemented using raw features: MFCC and MEL, where FCNN was explored on the pre-trained vectors while varying the hyper-parameters of these networks to obtain the best results for each dataset and task. MTL was evaluated against the single task learning (STL) approach for the three tasks and six datasets, in which the MTL and pre-trained vectors almost constantly outperformed STL. All the data and pre-trained models used in this paper are available and can be acquired by the public.
Multi-Dialect Arabic BERT for Country-Level Dialect Identification
Jul 10, 2020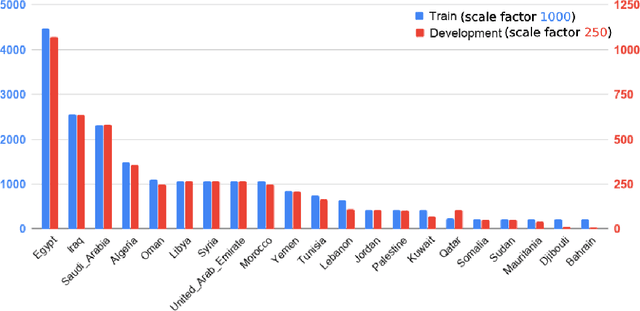
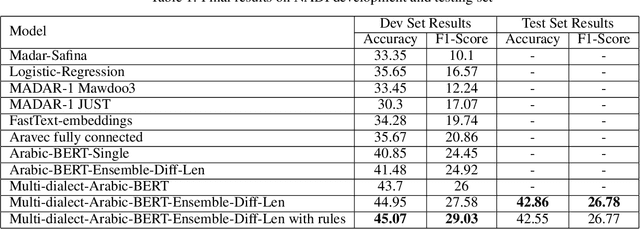
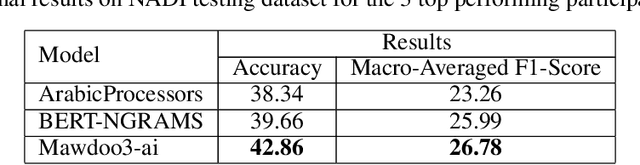
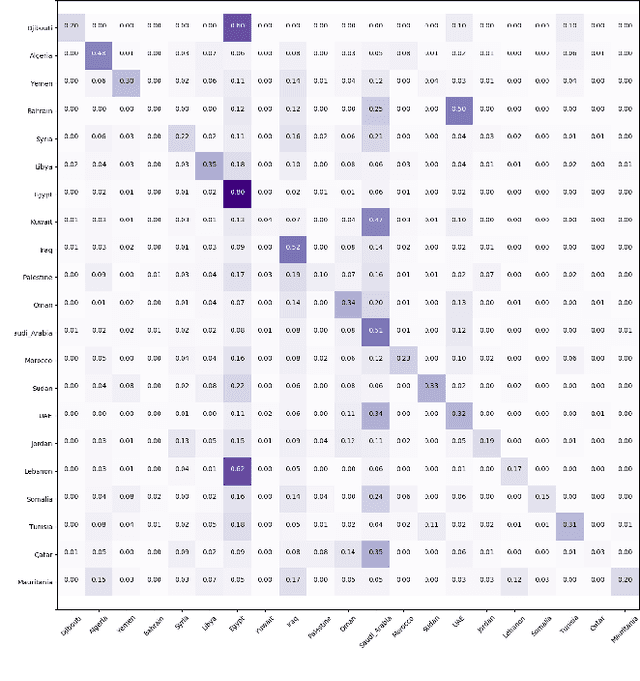
Arabic dialect identification is a complex problem for a number of inherent properties of the language itself. In this paper, we present the experiments conducted, and the models developed by our competing team, Mawdoo3 AI, along the way to achieving our winning solution to subtask 1 of the Nuanced Arabic Dialect Identification (NADI) shared task. The dialect identification subtask provides 21,000 country-level labeled tweets covering all 21 Arab countries. An unlabeled corpus of 10M tweets from the same domain is also presented by the competition organizers for optional use. Our winning solution itself came in the form of an ensemble of different training iterations of our pre-trained BERT model, which achieved a micro-averaged F1-score of 26.78% on the subtask at hand. We publicly release the pre-trained language model component of our winning solution under the name of Multi-dialect-Arabic-BERT model, for any interested researcher out there.