 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Semantic Search and its Role in Retrieved-Augmented-Generation for Arabic Language
Mar 27, 2024The latest advancements in machine learning and deep learning have brought forth the concept of semantic similarity, which has proven immensely beneficial in multiple applications and has largely replaced keyword search. However, evaluating semantic similarity and conducting searches for a specific query across various documents continue to be a complicated task. This complexity is due to the multifaceted nature of the task, the lack of standard benchmarks, whereas these challenges are further amplified for Arabic language. This paper endeavors to establish a straightforward yet potent benchmark for semantic search in Arabic. Moreover, to precisely evaluate the effectiveness of these metrics and the dataset, we conduct our assessment of semantic search within the framework of retrieval augmented generation (RAG).
A New Benchmark for Evaluating Automatic Speech Recognition in the Arabic Call Domain
Mar 07, 2024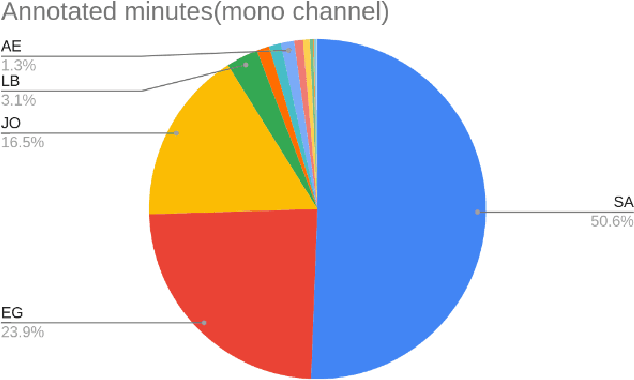
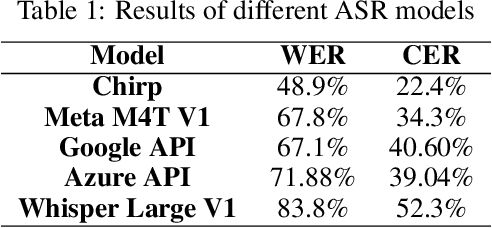
This work is an attempt to introduce a comprehensive benchmark for Arabic speech recognition, specifically tailored to address the challenges of telephone conversations in Arabic language. Arabic, characterized by its rich dialectal diversity and phonetic complexity, presents a number of unique challenges for automatic speech recognition (ASR) systems. These challenges are further amplified in the domain of telephone calls, where audio quality, background noise, and conversational speech styles negatively affect recognition accuracy. Our work aims to establish a robust benchmark that not only encompasses the broad spectrum of Arabic dialects but also emulates the real-world conditions of call-based communications. By incorporating diverse dialectical expressions and accounting for the variable quality of call recordings, this benchmark seeks to provide a rigorous testing ground for the development and evaluation of ASR systems capable of navigating the complexities of Arabic speech in telephonic contexts. This work also attempts to establish a baseline performance evaluation using state-of-the-art ASR technologies.