 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBench-Marking And Improving Arabic Automatic Image Captioning Through The Use Of Multi-Task Learning Paradigm
Feb 11, 2022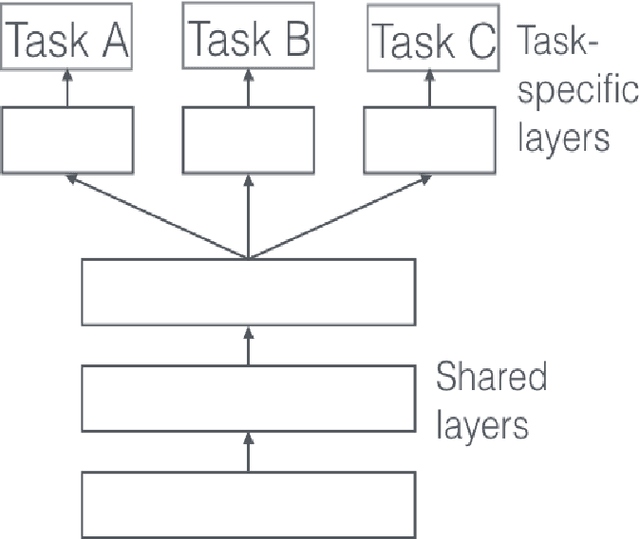

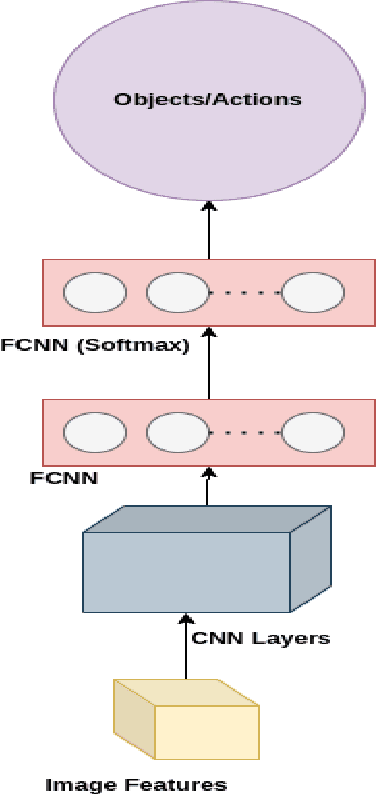
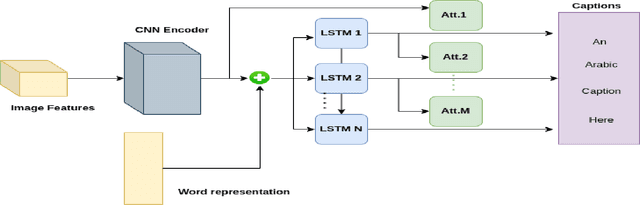
The continuous increase in the use of social media and the visual content on the internet have accelerated the research in computer vision field in general and the image captioning task in specific. The process of generating a caption that best describes an image is a useful task for various applications such as it can be used in image indexing and as a hearing aid for the visually impaired. In recent years, the image captioning task has witnessed remarkable advances regarding both datasets and architectures, and as a result, the captioning quality has reached an astounding performance. However, the majority of these advances especially in datasets are targeted for English, which left other languages such as Arabic lagging behind. Although Arabic language, being spoken by more than 450 million people and being the most growing language on the internet, lacks the fundamental pillars it needs to advance its image captioning research, such as benchmarks or unified datasets. This works is an attempt to expedite the synergy in this task by providing unified datasets and benchmarks, while also exploring methods and techniques that could enhance the performance of Arabic image captioning. The use of multi-task learning is explored, alongside exploring various word representations and different features. The results showed that the use of multi-task learning and pre-trained word embeddings noticeably enhanced the quality of image captioning, however the presented results shows that Arabic captioning still lags behind when compared to the English language. The used dataset and code are available at this link.