 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARTA: Speaker Profiling for ARabic TAlk
Dec 13, 2020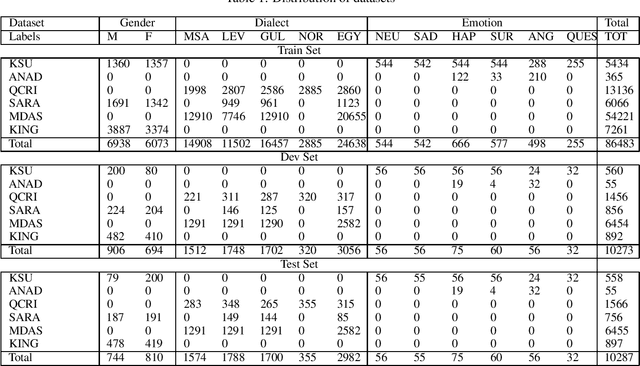
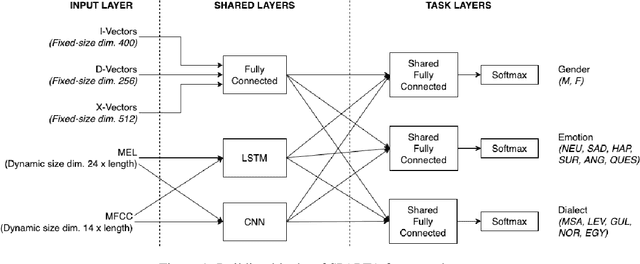

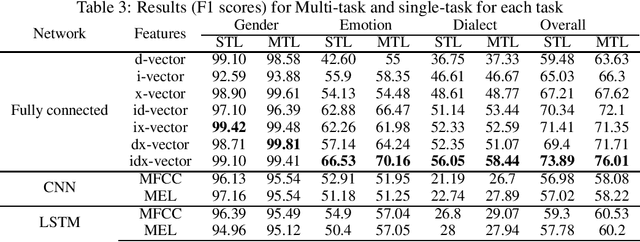
This paper proposes a novel approach to an automatic estimation of three speaker traits from Arabic speech: gender, emotion, and dialect. After showing promising results on different text classification tasks, the multi-task learning (MTL) approach is used in this paper for Arabic speech classification tasks. The dataset was assembled from six publicly available datasets. First, The datasets were edited and thoroughly divided into train, development, and test sets (open to the public), and a benchmark was set for each task and dataset throughout the paper. Then, three different networks were explored: Long Short Term Memory (LSTM), Convolutional Neural Network (CNN), and Fully-Connected Neural Network (FCNN) on five different types of features: two raw features (MFCC and MEL) and three pre-trained vectors (i-vectors, d-vectors, and x-vectors). LSTM and CNN networks were implemented using raw features: MFCC and MEL, where FCNN was explored on the pre-trained vectors while varying the hyper-parameters of these networks to obtain the best results for each dataset and task. MTL was evaluated against the single task learning (STL) approach for the three tasks and six datasets, in which the MTL and pre-trained vectors almost constantly outperformed STL. All the data and pre-trained models used in this paper are available and can be acquired by the public.