 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Dyna-style Planning Under Limited Model Capacity
Jul 05, 2020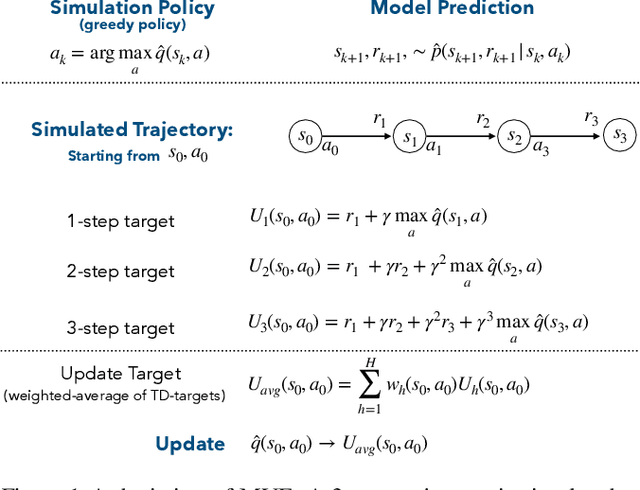


In model-based reinforcement learning, planning with an imperfect model of the environment has the potential to harm learning progress. But even when a model is imperfect, it may still contain information that is useful for planning. In this paper, we investigate the idea of using an imperfect model selectively. The agent should plan in parts of the state space where the model would be helpful but refrain from using the model where it would be harmful. An effective selective planning mechanism requires estimating predictive uncertainty, which arises out of aleatoric uncertainty, parameter uncertainty, and model inadequacy, among other sources. Prior work has focused on parameter uncertainty for selective planning. In this work, we emphasize the importance of model inadequacy. We show that heteroscedastic regression can signal predictive uncertainty arising from model inadequacy that is complementary to that which is detected by methods designed for parameter uncertainty, indicating that considering both parameter uncertainty and model inadequacy may be a more promising direction for effective selective planning than either in isolation.
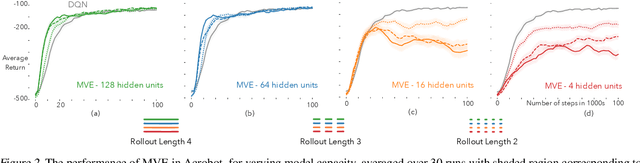
Incrementally Learning Functions of the Return
Jul 05, 2019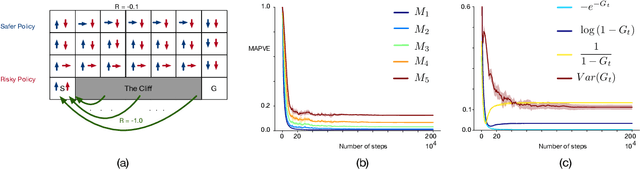
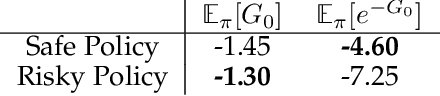
Temporal difference methods enable efficient estimation of value functions in reinforcement learning in an incremental fashion, and are of broader interest because they correspond learning as observed in biological systems. Standard value functions correspond to the expected value of a sum of discounted returns. While this formulation is often sufficient for many purposes, it would often be useful to be able to represent functions of the return as well. Unfortunately, most such functions cannot be estimated directly using TD methods. We propose a means of estimating functions of the return using its moments, which can be learned online using a modified TD algorithm. The moments of the return are then used as part of a Taylor expansion to approximate analytic functions of the return.
Planning with Expectation Models
Apr 03, 2019


Distribution and sample models are two popular model choices in model-based reinforcement learning (MBRL). However, learning these models can be intractable, particularly when the state and action spaces are large. Expectation models, on the other hand, are relatively easier to learn due to their compactness and have also been widely used for deterministic environments. For stochastic environments, it is not obvious how expectation models can be used for planning as they only partially characterize a distribution. In this paper, we propose a sound way of using approximate expectation models for MBRL. In particular, we 1) show that planning with an expectation model is equivalent to planning with a distribution model if the state value function is linear in state features, 2) analyze two common parametrization choices for approximating the expectation: linear and non-linear expectation models, 3) propose a sound model-based policy evaluation algorithm and present its convergence results, and 4) empirically demonstrate the effectiveness of the proposed planning algorithm.
Organizing Experience: A Deeper Look at Replay Mechanisms for Sample-based Planning in Continuous State Domains
Jun 12, 2018
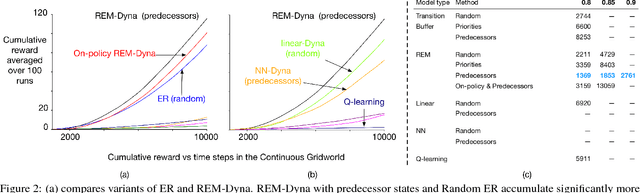
Model-based strategies for control are critical to obtain sample efficient learning. Dyna is a planning paradigm that naturally interleaves learning and planning, by simulating one-step experience to update the action-value function. This elegant planning strategy has been mostly explored in the tabular setting. The aim of this paper is to revisit sample-based planning, in stochastic and continuous domains with learned models. We first highlight the flexibility afforded by a model over Experience Replay (ER). Replay-based methods can be seen as stochastic planning methods that repeatedly sample from a buffer of recent agent-environment interactions and perform updates to improve data efficiency. We show that a model, as opposed to a replay buffer, is particularly useful for specifying which states to sample from during planning, such as predecessor states that propagate information in reverse from a state more quickly. We introduce a semi-parametric model learning approach, called Reweighted Experience Models (REMs), that makes it simple to sample next states or predecessors. We demonstrate that REM-Dyna exhibits similar advantages over replay-based methods in learning in continuous state problems, and that the performance gap grows when moving to stochastic domains, of increasing size.