 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-SpeQ: Speculative Quantized Decoding with Proactive Expert Prefetching and Offloading for Mixture-of-Experts
Nov 18, 2025The immense memory requirements of state-of-the-art Mixture-of-Experts (MoE) models present a significant challenge for inference, often exceeding the capacity of a single accelerator. While offloading experts to host memory is a common solution, it introduces a severe I/O bottleneck over the PCIe bus, as the data-dependent nature of expert selection places these synchronous transfers directly on the critical path of execution, crippling performance. This paper argues that the I/O bottleneck can be overcome by trading a small amount of cheap, on-device computation to hide the immense cost of data movement. We present MoE-SpeQ, a new inference system built on a novel co-design of speculative execution and expert offloading. MoE-SpeQ employs a small, on-device draft model to predict the sequence of required experts for future tokens. This foresight enables a runtime orchestrator to prefetch these experts from host memory, effectively overlapping the expensive I/O with useful computation and hiding the latency from the critical path. To maximize performance, an adaptive governor, guided by an Amortization Roofline Model, dynamically tunes the speculation strategy to the underlying hardware. Our evaluation on memory-constrained devices shows that for the Phi-MoE model, MoE-SpeQ achieves at most 2.34x speedup over the state-of-the-art offloading framework. Our work establishes a new, principled approach for managing data-dependent memory access in resource-limited environments, making MoE inference more accessible on commodity hardware.
TooBadRL: Trigger Optimization to Boost Effectiveness of Backdoor Attacks on Deep Reinforcement Learning
Jun 12, 2025Deep reinforcement learning (DRL) has achieved remarkable success in a wide range of sequential decision-making domains, including robotics, healthcare, smart grids, and finance. Recent research demonstrates that attackers can efficiently exploit system vulnerabilities during the training phase to execute backdoor attacks, producing malicious actions when specific trigger patterns are present in the state observations. However, most existing backdoor attacks rely primarily on simplistic and heuristic trigger configurations, overlooking the potential efficacy of trigger optimization. To address this gap, we introduce TooBadRL (Trigger Optimization to Boost Effectiveness of Backdoor Attacks on DRL), the first framework to systematically optimize DRL backdoor triggers along three critical axes, i.e., temporal, spatial, and magnitude. Specifically, we first introduce a performance-aware adaptive freezing mechanism for injection timing. Then, we formulate dimension selection as a cooperative game, utilizing Shapley value analysis to identify the most influential state variable for the injection dimension. Furthermore, we propose a gradient-based adversarial procedure to optimize the injection magnitude under environment constraints. Evaluations on three mainstream DRL algorithms and nine benchmark tasks show that TooBadRL significantly improves attack success rates, while ensuring minimal degradation of normal task performance. These results highlight the previously underappreciated importance of principled trigger optimization in DRL backdoor attacks. The source code of TooBadRL can be found at https://github.com/S3IC-Lab/TooBadRL.
Magnitude Pruning of Large Pretrained Transformer Models with a Mixture Gaussian Prior
Nov 01, 2024
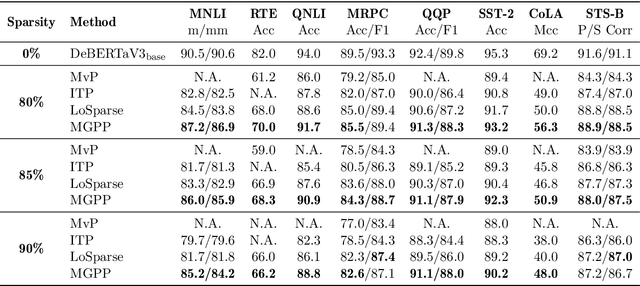


Large pretrained transformer models have revolutionized modern AI applications with their state-of-the-art performance in natural language processing (NLP). However, their substantial parameter count poses challenges for real-world deployment. To address this, researchers often reduce model size by pruning parameters based on their magnitude or sensitivity. Previous research has demonstrated the limitations of magnitude pruning, especially in the context of transfer learning for modern NLP tasks. In this paper, we introduce a new magnitude-based pruning algorithm called mixture Gaussian prior pruning (MGPP), which employs a mixture Gaussian prior for regularization. MGPP prunes non-expressive weights under the guidance of the mixture Gaussian prior, aiming to retain the model's expressive capability. Extensive evaluations across various NLP tasks, including natural language understanding, question answering, and natural language generation, demonstrate the superiority of MGPP over existing pruning methods, particularly in high sparsity settings. Additionally, we provide a theoretical justification for the consistency of the sparse transformer, shedding light on the effectiveness of the proposed pruning method.
Sparse Deep Learning for Time Series Data: Theory and Applications
Oct 05, 2023



Sparse deep learning has become a popular technique for improving the performance of deep neural networks in areas such as uncertainty quantification, variable selection, and large-scale network compression. However, most existing research has focused on problems where the observations are independent and identically distributed (i.i.d.), and there has been little work on the problems where the observations are dependent, such as time series data and sequential data in natural language processing. This paper aims to address this gap by studying the theory for sparse deep learning with dependent data. We show that sparse recurrent neural networks (RNNs) can be consistently estimated, and their predictions are asymptotically normally distributed under appropriate assumptions, enabling the prediction uncertainty to be correctly quantified. Our numerical results show that sparse deep learning outperforms state-of-the-art methods, such as conformal predictions, in prediction uncertainty quantification for time series data. Furthermore, our results indicate that the proposed method can consistently identify the autoregressive order for time series data and outperform existing methods in large-scale model compression. Our proposed method has important practical implications in fields such as finance, healthcare, and energy, where both accurate point estimates and prediction uncertainty quantification are of concern.
Curriculum Knowledge Switching for Pancreas Segmentation
Jun 22, 2023Pancreas segmentation is challenging due to the small proportion and highly changeable anatomical structure. It motivates us to propose a novel segmentation framework, namely Curriculum Knowledge Switching (CKS) framework, which decomposes detecting pancreas into three phases with different difficulty extent: straightforward, difficult, and challenging. The framework switches from straightforward to challenging phases and thereby gradually learns to detect pancreas. In addition, we adopt the momentum update parameter updating mechanism during switching, ensuring the loss converges gradually when the input dataset changes. Experimental results show that different neural network backbones with the CKS framework achieved state-of-the-art performance on the NIH dataset as measured by the DSC metric.
* ICIP 2023
Graph Federated Learning with Hidden Representation Sharing
Dec 23, 2022Learning on Graphs (LoG) is widely used in multi-client systems when each client has insufficient local data, and multiple clients have to share their raw data to learn a model of good quality. One scenario is to recommend items to clients with limited historical data and sharing similar preferences with other clients in a social network. On the other hand, due to the increasing demands for the protection of clients' data privacy, Federated Learning (FL) has been widely adopted: FL requires models to be trained in a multi-client system and restricts sharing of raw data among clients. The underlying potential data-sharing conflict between LoG and FL is under-explored and how to benefit from both sides is a promising problem. In this work, we first formulate the Graph Federated Learning (GFL) problem that unifies LoG and FL in multi-client systems and then propose sharing hidden representation instead of the raw data of neighbors to protect data privacy as a solution. To overcome the biased gradient problem in GFL, we provide a gradient estimation method and its convergence analysis under the non-convex objective. In experiments, we evaluate our method in classification tasks on graphs. Our experiment shows a good match between our theory and the practice.