 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagnitude Pruning of Large Pretrained Transformer Models with a Mixture Gaussian Prior
Paper and Code
Nov 01, 2024
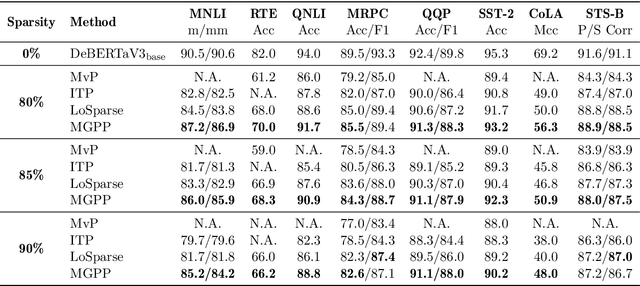


Large pretrained transformer models have revolutionized modern AI applications with their state-of-the-art performance in natural language processing (NLP). However, their substantial parameter count poses challenges for real-world deployment. To address this, researchers often reduce model size by pruning parameters based on their magnitude or sensitivity. Previous research has demonstrated the limitations of magnitude pruning, especially in the context of transfer learning for modern NLP tasks. In this paper, we introduce a new magnitude-based pruning algorithm called mixture Gaussian prior pruning (MGPP), which employs a mixture Gaussian prior for regularization. MGPP prunes non-expressive weights under the guidance of the mixture Gaussian prior, aiming to retain the model's expressive capability. Extensive evaluations across various NLP tasks, including natural language understanding, question answering, and natural language generation, demonstrate the superiority of MGPP over existing pruning methods, particularly in high sparsity settings. Additionally, we provide a theoretical justification for the consistency of the sparse transformer, shedding light on the effectiveness of the proposed pruning method.