 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Update Your Model: Constrained Model-based Reinforcement Learning
Oct 15, 2022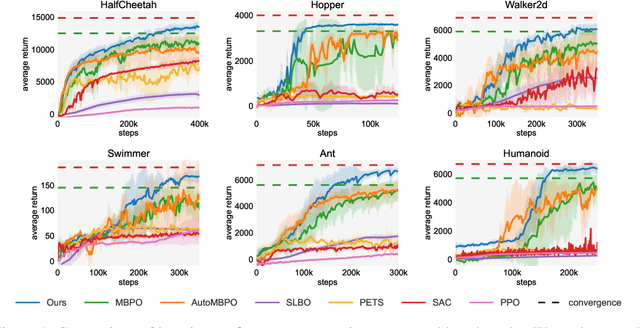


Designing and analyzing model-based RL (MBRL) algorithms with guaranteed monotonic improvement has been challenging, mainly due to the interdependence between policy optimization and model learning. Existing discrepancy bounds generally ignore the impacts of model shifts, and their corresponding algorithms are prone to degrade performance by drastic model updating. In this work, we first propose a novel and general theoretical scheme for a non-decreasing performance guarantee of MBRL. Our follow-up derived bounds reveal the relationship between model shifts and performance improvement. These discoveries encourage us to formulate a constrained lower-bound optimization problem to permit the monotonicity of MBRL. A further example demonstrates that learning models from a dynamically-varying number of explorations benefit the eventual returns. Motivated by these analyses, we design a simple but effective algorithm CMLO (Constrained Model-shift Lower-bound Optimization), by introducing an event-triggered mechanism that flexibly determines when to update the model. Experiments show that CMLO surpasses other state-of-the-art methods and produces a boost when various policy optimization methods are employed.
Adversarial Option-Aware Hierarchical Imitation Learning
Jun 11, 2021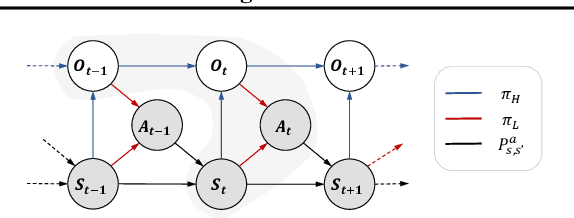
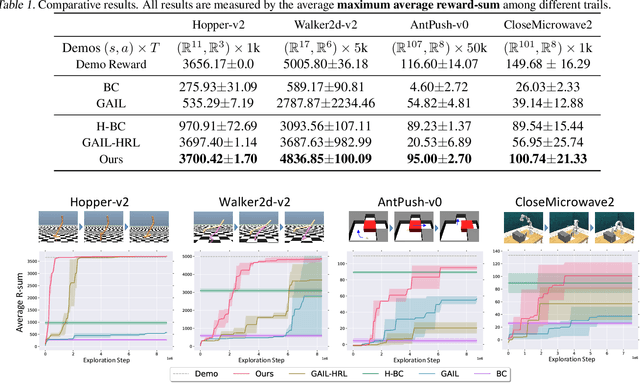
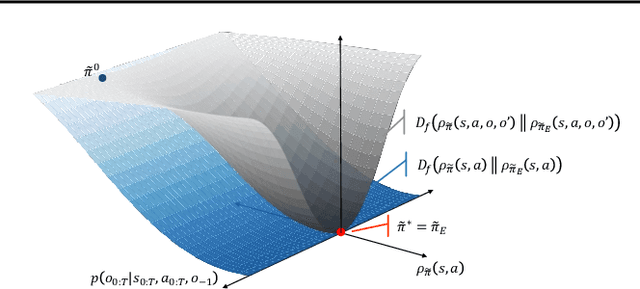
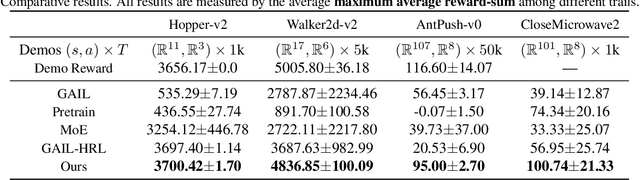
It has been a challenge to learning skills for an agent from long-horizon unannotated demonstrations. Existing approaches like Hierarchical Imitation Learning(HIL) are prone to compounding errors or suboptimal solutions. In this paper, we propose Option-GAIL, a novel method to learn skills at long horizon. The key idea of Option-GAIL is modeling the task hierarchy by options and train the policy via generative adversarial optimization. In particular, we propose an Expectation-Maximization(EM)-style algorithm: an E-step that samples the options of expert conditioned on the current learned policy, and an M-step that updates the low- and high-level policies of agent simultaneously to minimize the newly proposed option-occupancy measurement between the expert and the agent. We theoretically prove the convergence of the proposed algorithm. Experiments show that Option-GAIL outperforms other counterparts consistently across a variety of tasks.
A Robust Tube-Based Smooth-MPC for Robot Manipulator Planning
Mar 17, 2021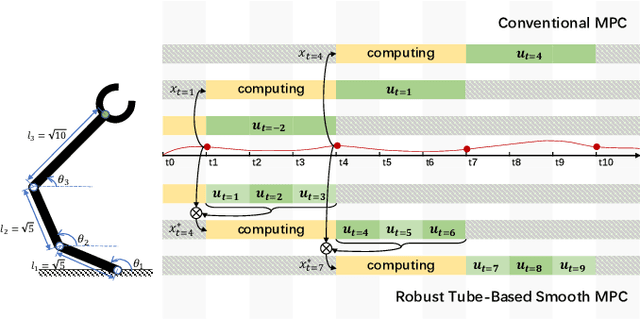
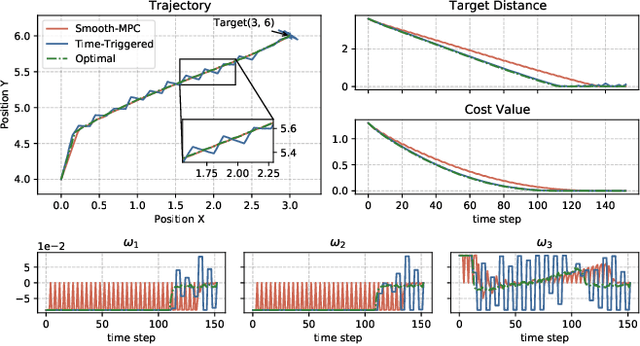
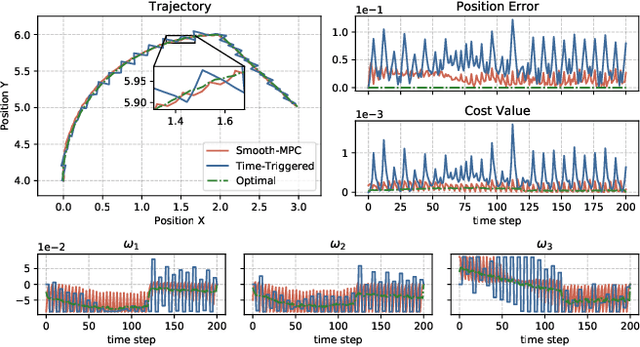
Model Predictive Control (MPC) has shown the great performance of target optimization and constraint satisfaction. However, the heavy computation of the Optimal Control Problem (OCP) at each triggering instant brings the serious delay from state sampling to the control signals, which limits the applications of MPC in resource-limited robot manipulator systems over complicated tasks. In this paper, we propose a novel robust tube-based smooth-MPC strategy for nonlinear robot manipulator planning systems with disturbances and constraints. Based on piecewise linearization and state prediction, our control strategy improves the smoothness and optimizes the delay of the control process. By deducing the deviation of the real system states and the nominal system states, we can predict the next real state set at the current instant. And by using this state set as the initial condition, we can solve the next OCP ahead and store the optimal controls based on the nominal system states, which eliminates the delay. Furthermore, we linearize the nonlinear system with a given upper bound of error, reducing the complexity of the OCP and improving the response speed. Based on the theoretical framework of tube MPC, we prove that the control strategy is recursively feasible and closed-loop stable with the constraints and disturbances. Numerical simulations have verified the efficacy of the designed approach compared with the conventional MPC.
Reinforcement Learning from Imperfect Demonstrations under Soft Expert Guidance
Nov 23, 2019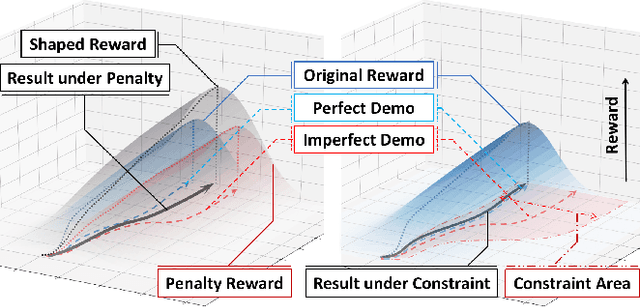
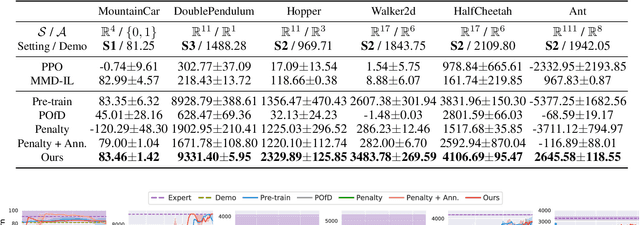
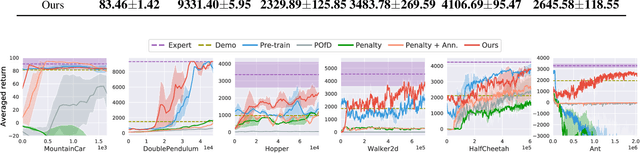
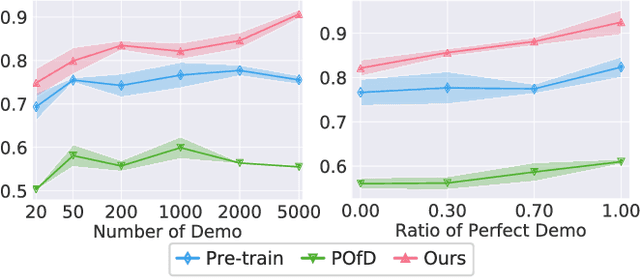
In this paper, we study Reinforcement Learning from Demonstrations (RLfD) that improves the exploration efficiency of Reinforcement Learning (RL) by providing expert demonstrations. Most of existing RLfD methods require demonstrations to be perfect and sufficient, which yet is unrealistic to meet in practice. To work on imperfect demonstrations, we first define an imperfect expert setting for RLfD in a formal way, and then point out that previous methods suffer from two issues in terms of optimality and convergence, respectively. Upon the theoretical findings we have derived, we tackle these two issues by regarding the expert guidance as a soft constraint on regulating the policy exploration of the agent, which eventually leads to a constrained optimization problem. We further demonstrate that such problem is able to be addressed efficiently by performing a local linear search on its dual form. Considerable empirical evaluations on a comprehensive collection of benchmarks indicate our method attains consistent improvement over other RLfD counterparts.
Task Transfer by Preference-Based Cost Learning
Feb 18, 2019
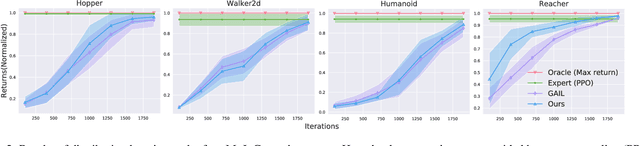
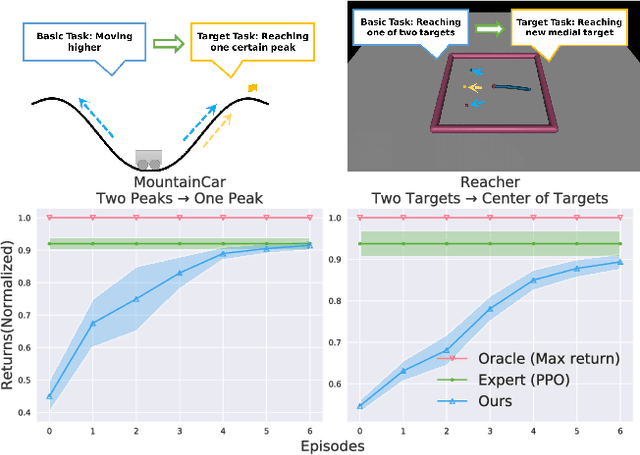
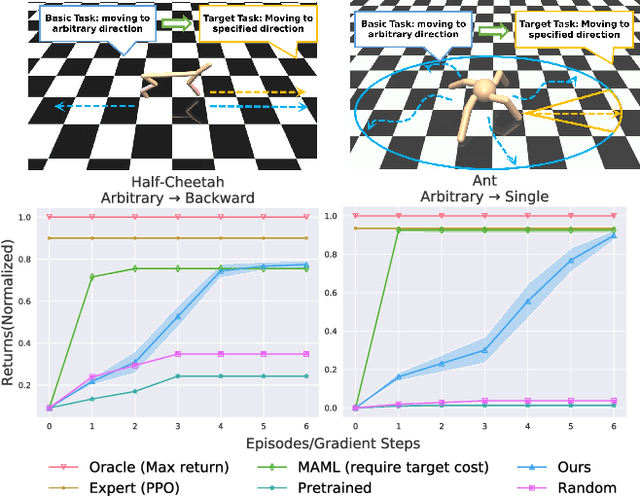
The goal of task transfer in reinforcement learning is migrating the action policy of an agent to the target task from the source task. Given their successes on robotic action planning, current methods mostly rely on two requirements: exactly-relevant expert demonstrations or the explicitly-coded cost function on target task, both of which, however, are inconvenient to obtain in practice. In this paper, we relax these two strong conditions by developing a novel task transfer framework where the expert preference is applied as a guidance. In particular, we alternate the following two steps: Firstly, letting experts apply pre-defined preference rules to select related expert demonstrates for the target task. Secondly, based on the selection result, we learn the target cost function and trajectory distribution simultaneously via enhanced Adversarial MaxEnt IRL and generate more trajectories by the learned target distribution for the next preference selection. The theoretical analysis on the distribution learning and convergence of the proposed algorithm are provided. Extensive simulations on several benchmarks have been conducted for further verifying the effectiveness of the proposed method.
Learning and Inferring Movement with Deep Generative Model
Oct 29, 2018



Learning and inference movement is a very challenging problem due to its high dimensionality and dependency to varied environments or tasks. In this paper, we propose an effective probabilistic method for learning and inference of basic movements. The motion planning problem is formulated as learning on a directed graphic model and deep generative model is used to perform learning and inference from demonstrations. An important characteristic of this method is that it flexibly incorporates the task descriptors and context information for long-term planning and it can be combined with dynamic systems for robot control. The experimental validations on robotic approaching path planning tasks show the advantages over the base methods with limited training data.