 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
Dec 03, 2024We introduce GLM-4-Voice, an intelligent and human-like end-to-end spoken chatbot. It supports both Chinese and English, engages in real-time voice conversations, and varies vocal nuances such as emotion, intonation, speech rate, and dialect according to user instructions. GLM-4-Voice uses an ultra-low bitrate (175bps), single-codebook speech tokenizer with 12.5Hz frame rate derived from an automatic speech recognition (ASR) model by incorporating a vector-quantized bottleneck into the encoder. To efficiently transfer knowledge from text to speech modalities, we synthesize speech-text interleaved data from existing text pre-training corpora using a text-to-token model. We continue pre-training from the pre-trained text language model GLM-4-9B with a combination of unsupervised speech data, interleaved speech-text data, and supervised speech-text data, scaling up to 1 trillion tokens, achieving state-of-the-art performance in both speech language modeling and spoken question answering. We then fine-tune the pre-trained model with high-quality conversational speech data, achieving superior performance compared to existing baselines in both conversational ability and speech quality. The open models can be accessed through https://github.com/THUDM/GLM-4-Voice and https://huggingface.co/THUDM/glm-4-voice-9b.
Scaling Speech-Text Pre-training with Synthetic Interleaved Data
Nov 26, 2024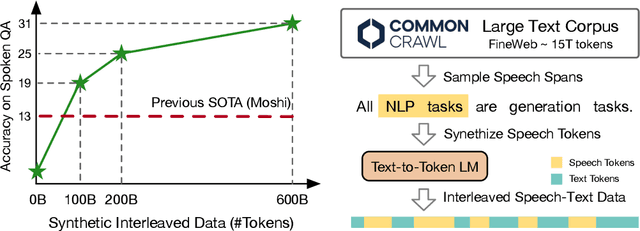

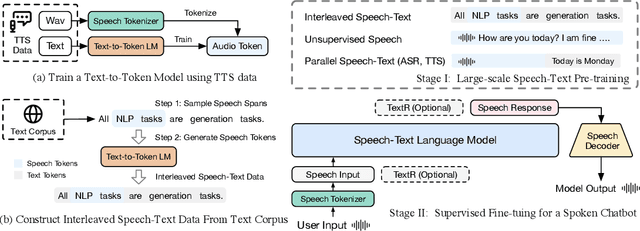
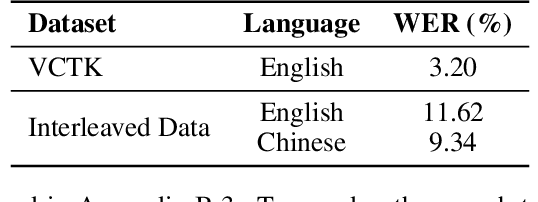
Speech language models (SpeechLMs) accept speech input and produce speech output, allowing for more natural human-computer interaction compared to text-based large language models (LLMs). Traditional approaches for developing SpeechLMs are constrained by the limited availability of unsupervised speech data and parallel speech-text data, which are significantly less abundant than text pre-training data, thereby limiting their scalability as LLMs. We propose a novel approach to scaling speech-text pre-training by leveraging large-scale synthetic interleaved data derived from text corpora, eliminating the need for parallel speech-text datasets. Our method efficiently constructs speech-text interleaved data by sampling text spans from existing text corpora and synthesizing corresponding speech spans using a text-to-token model, bypassing the need to generate actual speech. We also employ a supervised speech tokenizer derived from an automatic speech recognition (ASR) model by incorporating a vector-quantized bottleneck into the encoder. This supervised training approach results in discrete speech tokens with strong semantic preservation even at lower sampling rates (e.g. 12.5Hz), while still maintaining speech reconstruction quality. Starting from a pre-trained language model and scaling our pre-training to 1 trillion tokens (with 600B synthetic interleaved speech-text data), we achieve state-of-the-art performance in speech language modeling and spoken question answering, improving performance on spoken questions tasks from the previous SOTA of 13% (Moshi) to 31%. We further demonstrate that by fine-tuning the pre-trained model with speech dialogue data, we can develop an end-to-end spoken chatbot that achieves competitive performance comparable to existing baselines in both conversational abilities and speech quality, even operating exclusively in the speech domain.
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024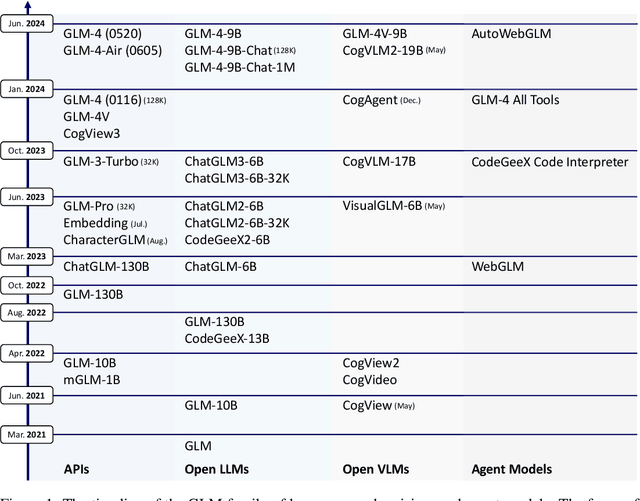
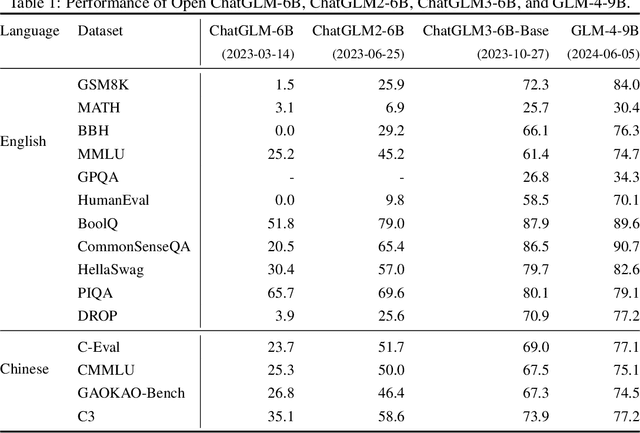
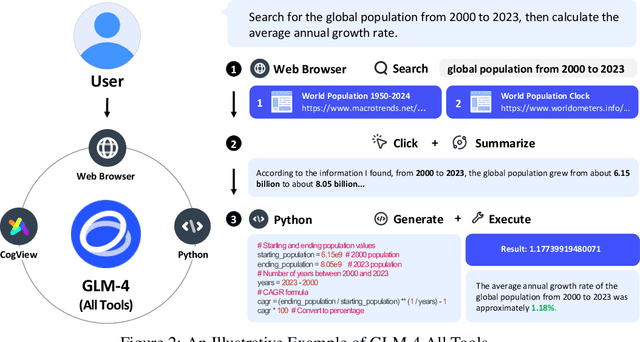
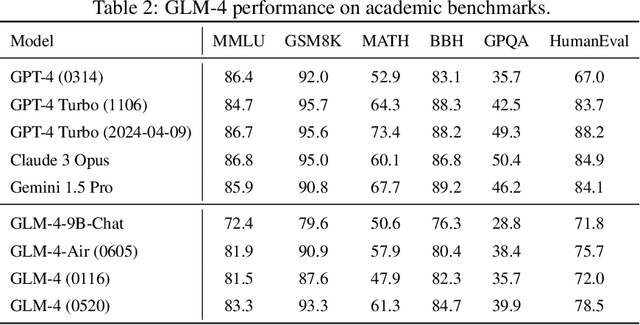
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
APAR: LLMs Can Do Auto-Parallel Auto-Regressive Decoding
Jan 12, 2024



The massive adoption of large language models (LLMs) demands efficient deployment strategies. However, the auto-regressive decoding process, which is fundamental to how most LLMs generate text, poses challenges to achieve efficient serving. In this work, we introduce a parallel auto-regressive generation method. By instruct-tuning on general domain data that contains hierarchical structures, we enable LLMs to independently plan their generation process and perform auto-parallel auto-regressive (APAR) generation, significantly reducing the number of generation steps. APAR alone can achieve up to 2x speed-up, and when combined with speculative decoding, the speed-up can reach up to 4x. In addition, APAR reduces the key-value cache consumption and attention computation during generation. This leads to a throughput increase of 20-70% and a latency reduce of 20-35% in high-throughput scenarios, compared to state-of-the-art serving frameworks.
AgentTuning: Enabling Generalized Agent Abilities for LLMs
Oct 22, 2023Open large language models (LLMs) with great performance in various tasks have significantly advanced the development of LLMs. However, they are far inferior to commercial models such as ChatGPT and GPT-4 when acting as agents to tackle complex tasks in the real world. These agent tasks employ LLMs as the central controller responsible for planning, memorization, and tool utilization, necessitating both fine-grained prompting methods and robust LLMs to achieve satisfactory performance. Though many prompting methods have been proposed to complete particular agent tasks, there is lack of research focusing on improving the agent capabilities of LLMs themselves without compromising their general abilities. In this work, we present AgentTuning, a simple and general method to enhance the agent abilities of LLMs while maintaining their general LLM capabilities. We construct AgentInstruct, a lightweight instruction-tuning dataset containing high-quality interaction trajectories. We employ a hybrid instruction-tuning strategy by combining AgentInstruct with open-source instructions from general domains. AgentTuning is used to instruction-tune the Llama 2 series, resulting in AgentLM. Our evaluations show that AgentTuning enables LLMs' agent capabilities without compromising general abilities. The AgentLM-70B is comparable to GPT-3.5-turbo on unseen agent tasks, demonstrating generalized agent capabilities. We open source the AgentInstruct and AgentLM-7B, 13B, and 70B models at https://github.com/THUDM/AgentTuning, serving open and powerful alternatives to commercial LLMs for agent tasks.