 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Few-Shot LLM Framework for Extreme Day Classification in Electricity Markets
Feb 17, 2026This paper proposes a few-shot classification framework based on Large Language Models (LLMs) to predict whether the next day will have spikes in real-time electricity prices. The approach aggregates system state information, including electricity demand, renewable generation, weather forecasts, and recent electricity prices, into a set of statistical features that are formatted as natural-language prompts and fed to an LLM along with general instructions. The model then determines the likelihood that the next day would be a spike day and reports a confidence score. Using historical data from the Texas electricity market, we demonstrate that this few-shot approach achieves performance comparable to supervised machine learning models, such as Support Vector Machines and XGBoost, and outperforms the latter two when limited historical data are available. These findings highlight the potential of LLMs as a data-efficient tool for classifying electricity price spikes in settings with scarce data.
Conformal Uncertainty Quantification of Electricity Price Predictions for Risk-Averse Storage Arbitrage
Dec 10, 2024



This paper proposes a risk-averse approach to energy storage price arbitrage, leveraging conformal uncertainty quantification for electricity price predictions. The method addresses the significant challenges posed by the inherent volatility and uncertainty of real-time electricity prices, which create substantial risks of financial losses for energy storage participants relying on future price forecasts to plan their operations. The framework comprises a two-layer prediction model to quantify real-time price uncertainty confidence intervals with high coverage. The framework is distribution-free and can work with any underlying point prediction model. We evaluate the quantification effectiveness through storage price arbitrage application by managing the risk of participating in the real-time market. We design a risk-averse policy for profit-maximization of energy storage arbitrage to find the safest storage schedule with very minimal losses. Using historical data from New York State and synthetic price predictions, our evaluations demonstrate that this framework can achieve good profit margins with less than $35\%$ purchases.
Energy Storage Arbitrage in Two-settlement Markets: A Transformer-Based Approach
Apr 26, 2024


This paper presents an integrated model for bidding energy storage in day-ahead and real-time markets to maximize profits. We show that in integrated two-stage bidding, the real-time bids are independent of day-ahead settlements, while the day-ahead bids should be based on predicted real-time prices. We utilize a transformer-based model for real-time price prediction, which captures complex dynamical patterns of real-time prices, and use the result for day-ahead bidding design. For real-time bidding, we utilize a long short-term memory-dynamic programming hybrid real-time bidding model. We train and test our model with historical data from New York State, and our results showed that the integrated system achieved promising results of almost a 20\% increase in profit compared to only bidding in real-time markets, and at the same time reducing the risk in terms of the number of days with negative profits.
Launching a Robust Backdoor Attack under Capability Constrained Scenarios
Apr 21, 2023As deep neural networks continue to be used in critical domains, concerns over their security have emerged. Deep learning models are vulnerable to backdoor attacks due to the lack of transparency. A poisoned backdoor model may perform normally in routine environments, but exhibit malicious behavior when the input contains a trigger. Current research on backdoor attacks focuses on improving the stealthiness of triggers, and most approaches require strong attacker capabilities, such as knowledge of the model structure or control over the training process. These attacks are impractical since in most cases the attacker's capabilities are limited. Additionally, the issue of model robustness has not received adequate attention. For instance, model distillation is commonly used to streamline model size as the number of parameters grows exponentially, and most of previous backdoor attacks failed after model distillation; the image augmentation operations can destroy the trigger and thus disable the backdoor. This study explores the implementation of black-box backdoor attacks within capability constraints. An attacker can carry out such attacks by acting as either an image annotator or an image provider, without involvement in the training process or knowledge of the target model's structure. Through the design of a backdoor trigger, our attack remains effective after model distillation and image augmentation, making it more threatening and practical. Our experimental results demonstrate that our method achieves a high attack success rate in black-box scenarios and evades state-of-the-art backdoor defenses.
Recent Results of Energy Disaggregation with Behind-the-Meter Solar Generation
Jul 07, 2022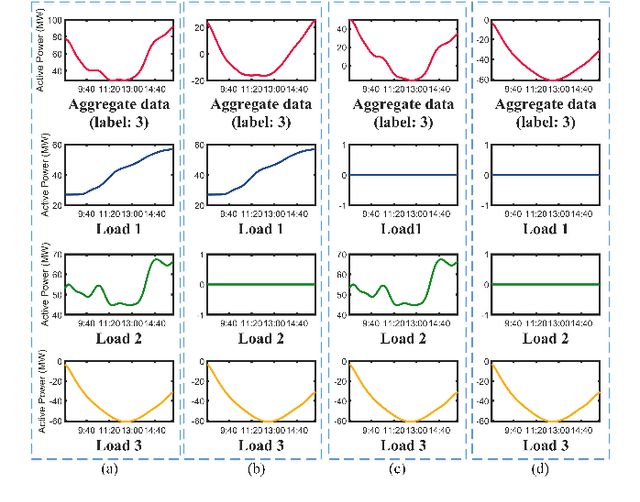
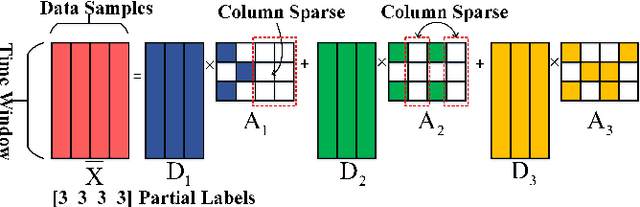
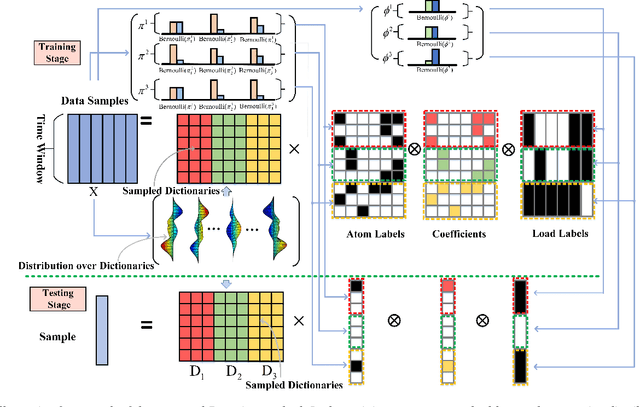
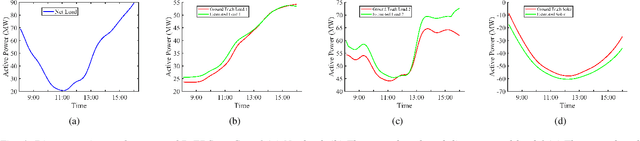
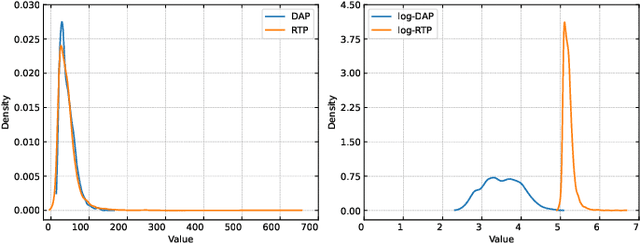
The rapid deployment of renewable generations such as photovoltaic (PV) generations brings great challenges to the resiliency of existing power systems. Because PV generations are volatile and typically invisible to the power system operator, estimating the generation and characterizing the uncertainty are in urgent need for operators to make insightful decisions. This paper summarizes our recent results on energy disaggregation at the substation level with Behind-the-Meter solar generation. We formulate the so-called ``partial label'' problem for energy disaggregation at substations, where the aggregate measurements contain the total consumption of multiple loads, and the existence of some loads is unknown. We develop two model-free disaggregation approaches based on deterministic dictionary learning and Bayesian dictionary learning, respectively. Unlike conventional methods which require fully annotated training data of individual loads, our approaches can extract load patterns given partially labeled aggregate data. Therefore, our partial label formulation is more applicable in the real world. Compared with deterministic dictionary learning, the Bayesian dictionary learning-based approach provides the uncertainty measure for the disaggregation results, at the cost of increased computational complexity. All the methods are validated by numerical experiments.
AMS_ADRN at SemEval-2022 Task 5: A Suitable Image-text Multimodal Joint Modeling Method for Multi-task Misogyny Identification
Feb 18, 2022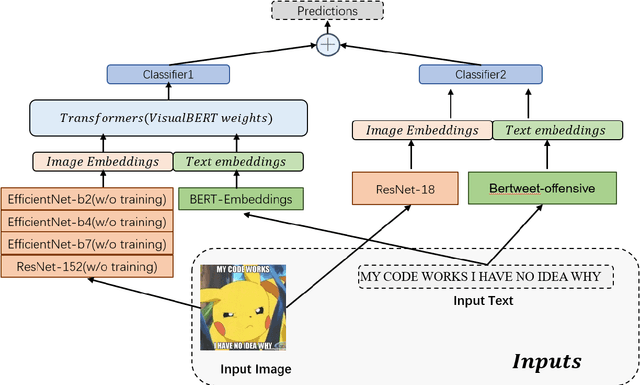

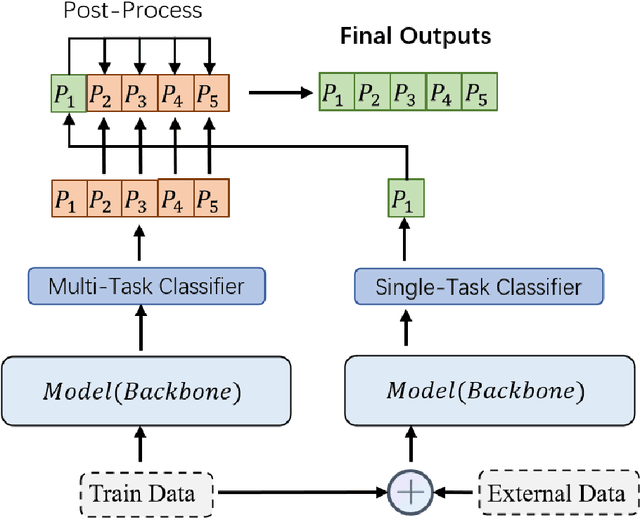
Women are influential online, especially in image-based social media such as Twitter and Instagram. However, many in the network environment contain gender discrimination and aggressive information, which magnify gender stereotypes and gender inequality. Therefore, the filtering of illegal content such as gender discrimination is essential to maintain a healthy social network environment. In this paper, we describe the system developed by our team for SemEval-2022 Task 5: Multimedia Automatic Misogyny Identification. More specifically, we introduce two novel system to analyze these posts: a multimodal multi-task learning architecture that combines Bertweet for text encoding with ResNet-18 for image representation, and a single-flow transformer structure which combines text embeddings from BERT-Embeddings and image embeddings from several different modules such as EfficientNet and ResNet. In this manner, we show that the information behind them can be properly revealed. Our approach achieves good performance on each of the two subtasks of the current competition, ranking 15th for Subtask A (0.746 macro F1-score), 11th for Subtask B (0.706 macro F1-score) while exceeding the official baseline results by high margins.
LP-BERT: Multi-task Pre-training Knowledge Graph BERT for Link Prediction
Jan 13, 2022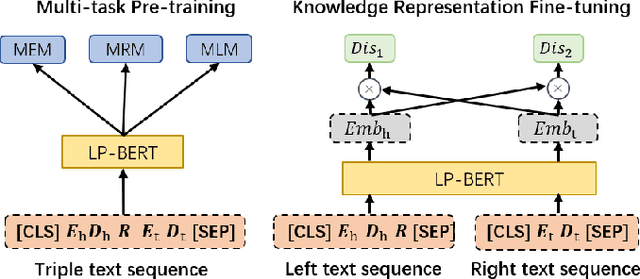
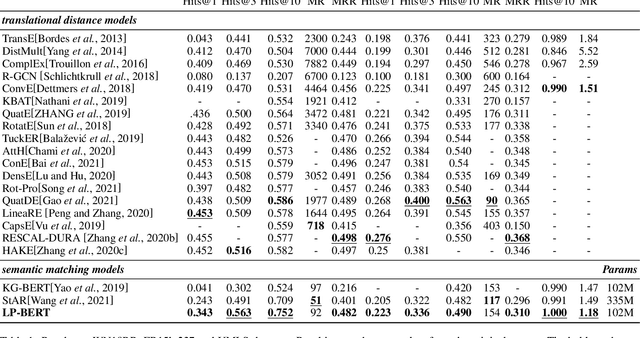
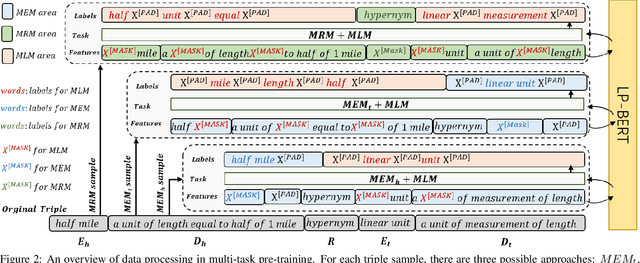
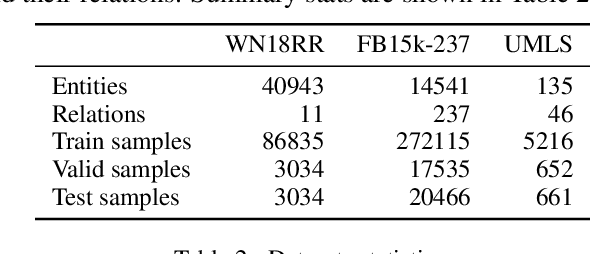
Link prediction plays an significant role in knowledge graph, which is an important resource for many artificial intelligence tasks, but it is often limited by incompleteness. In this paper, we propose knowledge graph BERT for link prediction, named LP-BERT, which contains two training stages: multi-task pre-training and knowledge graph fine-tuning. The pre-training strategy not only uses Mask Language Model (MLM) to learn the knowledge of context corpus, but also introduces Mask Entity Model (MEM) and Mask Relation Model (MRM), which can learn the relationship information from triples by predicting semantic based entity and relation elements. Structured triple relation information can be transformed into unstructured semantic information, which can be integrated into the pre-training model together with context corpus information. In the fine-tuning phase, inspired by contrastive learning, we carry out a triple-style negative sampling in sample batch, which greatly increased the proportion of negative sampling while keeping the training time almost unchanged. Furthermore, we propose a data augmentation method based on the inverse relationship of triples to further increase the sample diversity. We achieve state-of-the-art results on WN18RR and UMLS datasets, especially the Hits@10 indicator improved by 5\% from the previous state-of-the-art result on WN18RR dataset.