 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMS_ADRN at SemEval-2022 Task 5: A Suitable Image-text Multimodal Joint Modeling Method for Multi-task Misogyny Identification
Feb 18, 2022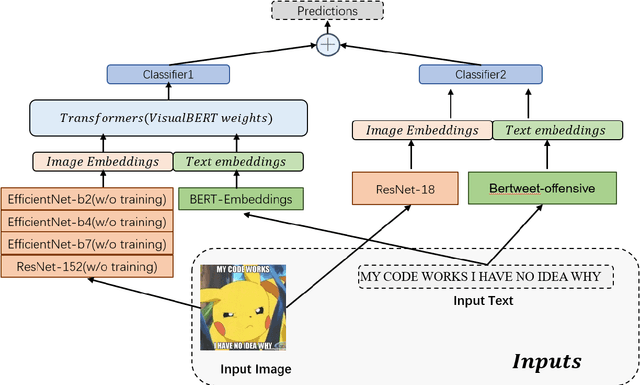

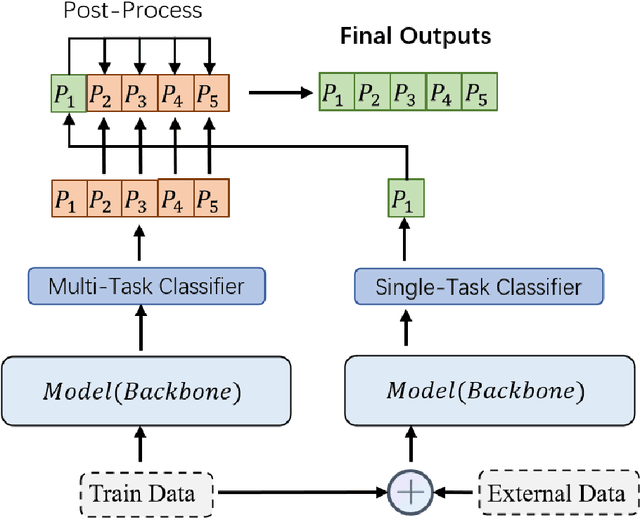
Women are influential online, especially in image-based social media such as Twitter and Instagram. However, many in the network environment contain gender discrimination and aggressive information, which magnify gender stereotypes and gender inequality. Therefore, the filtering of illegal content such as gender discrimination is essential to maintain a healthy social network environment. In this paper, we describe the system developed by our team for SemEval-2022 Task 5: Multimedia Automatic Misogyny Identification. More specifically, we introduce two novel system to analyze these posts: a multimodal multi-task learning architecture that combines Bertweet for text encoding with ResNet-18 for image representation, and a single-flow transformer structure which combines text embeddings from BERT-Embeddings and image embeddings from several different modules such as EfficientNet and ResNet. In this manner, we show that the information behind them can be properly revealed. Our approach achieves good performance on each of the two subtasks of the current competition, ranking 15th for Subtask A (0.746 macro F1-score), 11th for Subtask B (0.706 macro F1-score) while exceeding the official baseline results by high margins.
LP-BERT: Multi-task Pre-training Knowledge Graph BERT for Link Prediction
Jan 13, 2022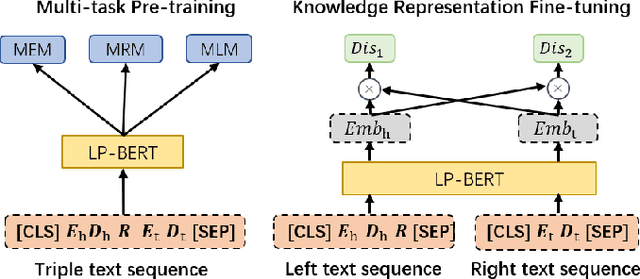
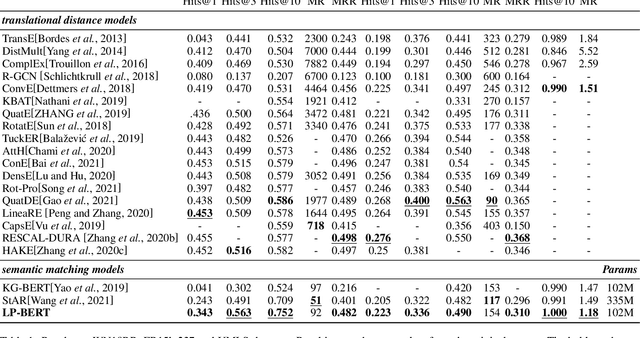
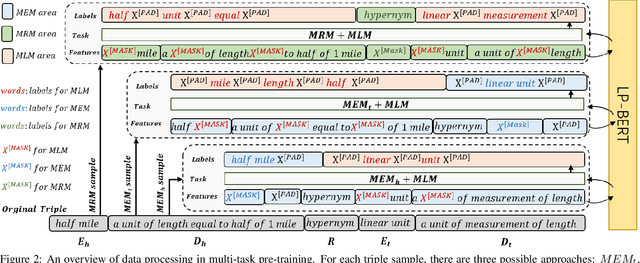
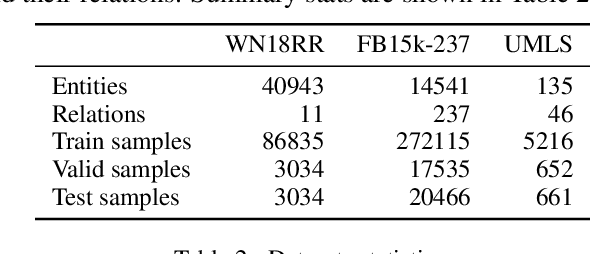
Link prediction plays an significant role in knowledge graph, which is an important resource for many artificial intelligence tasks, but it is often limited by incompleteness. In this paper, we propose knowledge graph BERT for link prediction, named LP-BERT, which contains two training stages: multi-task pre-training and knowledge graph fine-tuning. The pre-training strategy not only uses Mask Language Model (MLM) to learn the knowledge of context corpus, but also introduces Mask Entity Model (MEM) and Mask Relation Model (MRM), which can learn the relationship information from triples by predicting semantic based entity and relation elements. Structured triple relation information can be transformed into unstructured semantic information, which can be integrated into the pre-training model together with context corpus information. In the fine-tuning phase, inspired by contrastive learning, we carry out a triple-style negative sampling in sample batch, which greatly increased the proportion of negative sampling while keeping the training time almost unchanged. Furthermore, we propose a data augmentation method based on the inverse relationship of triples to further increase the sample diversity. We achieve state-of-the-art results on WN18RR and UMLS datasets, especially the Hits@10 indicator improved by 5\% from the previous state-of-the-art result on WN18RR dataset.