 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEET: A Monte Carlo Exploration-Exploitation Trade-off for Buffer Sampling
Oct 24, 2022Data selection is essential for any data-based optimization technique, such as Reinforcement Learning. State-of-the-art sampling strategies for the experience replay buffer improve the performance of the Reinforcement Learning agent. However, they do not incorporate uncertainty in the Q-Value estimation. Consequently, they cannot adapt the sampling strategies, including exploration and exploitation of transitions, to the complexity of the task. To address this, this paper proposes a new sampling strategy that leverages the exploration-exploitation trade-off. This is enabled by the uncertainty estimation of the Q-Value function, which guides the sampling to explore more significant transitions and, thus, learn a more efficient policy. Experiments on classical control environments demonstrate stable results across various environments. They show that the proposed method outperforms state-of-the-art sampling strategies for dense rewards w.r.t. convergence and peak performance by 26% on average.
Utilizing Explainable AI for improving the Performance of Neural Networks
Oct 07, 2022


Nowadays, deep neural networks are widely used in a variety of fields that have a direct impact on society. Although those models typically show outstanding performance, they have been used for a long time as black boxes. To address this, Explainable Artificial Intelligence (XAI) has been developing as a field that aims to improve the transparency of the model and increase their trustworthiness. We propose a retraining pipeline that consistently improves the model predictions starting from XAI and utilizing state-of-the-art techniques. To do that, we use the XAI results, namely SHapley Additive exPlanations (SHAP) values, to give specific training weights to the data samples. This leads to an improved training of the model and, consequently, better performance. In order to benchmark our method, we evaluate it on both real-life and public datasets. First, we perform the method on a radar-based people counting scenario. Afterward, we test it on the CIFAR-10, a public Computer Vision dataset. Experiments using the SHAP-based retraining approach achieve a 4% more accuracy w.r.t. the standard equal weight retraining for people counting tasks. Moreover, on the CIFAR-10, our SHAP-based weighting strategy ends up with a 3% accuracy rate than the training procedure with equal weighted samples.
Cross-modal Learning of Graph Representations using Radar Point Cloud for Long-Range Gesture Recognition
Mar 31, 2022

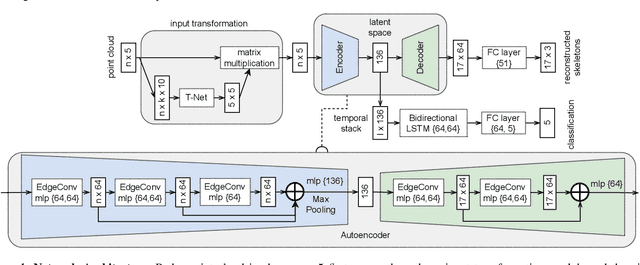
Gesture recognition is one of the most intuitive ways of interaction and has gathered particular attention for human computer interaction. Radar sensors possess multiple intrinsic properties, such as their ability to work in low illumination, harsh weather conditions, and being low-cost and compact, making them highly preferable for a gesture recognition solution. However, most literature work focuses on solutions with a limited range that is lower than a meter. We propose a novel architecture for a long-range (1m - 2m) gesture recognition solution that leverages a point cloud-based cross-learning approach from camera point cloud to 60-GHz FMCW radar point cloud, which allows learning better representations while suppressing noise. We use a variant of Dynamic Graph CNN (DGCNN) for the cross-learning, enabling us to model relationships between the points at a local and global level and to model the temporal dynamics a Bi-LSTM network is employed. In the experimental results section, we demonstrate our model's overall accuracy of 98.4% for five gestures and its generalization capability.
Label-Aware Ranked Loss for robust People Counting using Automotive in-cabin Radar
Oct 12, 2021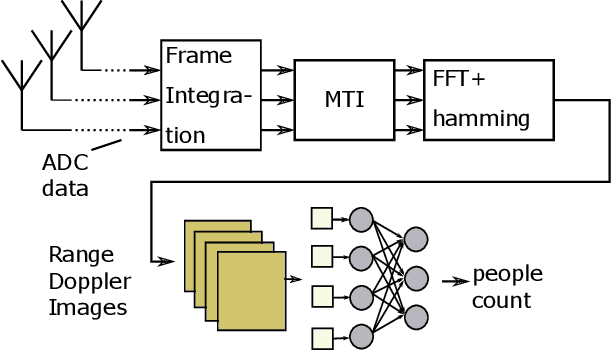
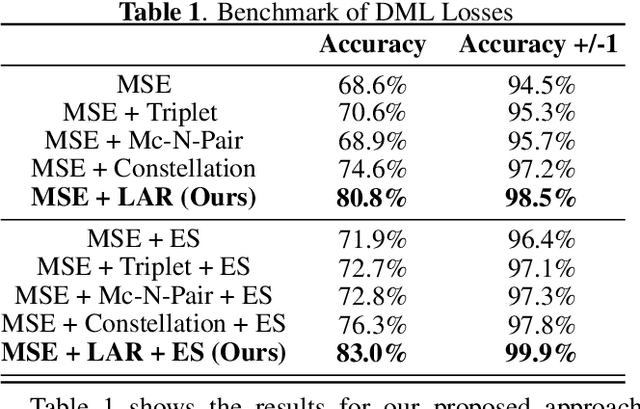
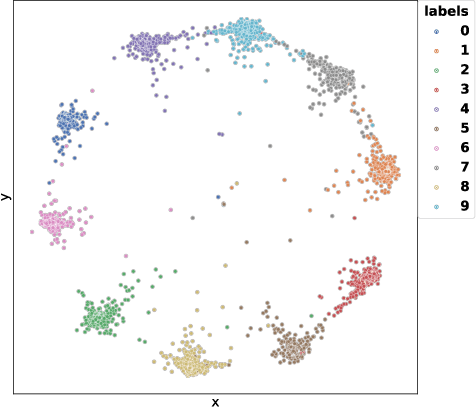
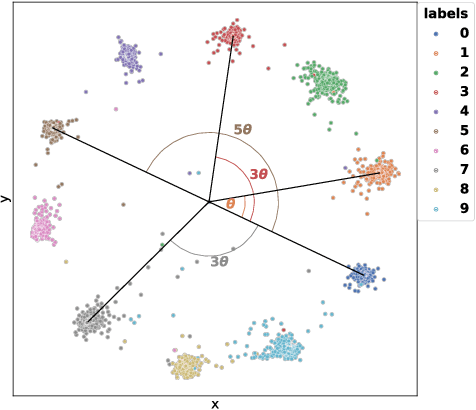
In this paper, we introduce the Label-Aware Ranked loss, a novel metric loss function. Compared to the state-of-the-art Deep Metric Learning losses, this function takes advantage of the ranked ordering of the labels in regression problems. To this end, we first show that the loss minimises when datapoints of different labels are ranked and laid at uniform angles between each other in the embedding space. Then, to measure its performance, we apply the proposed loss on a regression task of people counting with a short-range radar in a challenging scenario, namely a vehicle cabin. The introduced approach improves the accuracy as well as the neighboring labels accuracy up to 83.0% and 99.9%: An increase of 6.7%and 2.1% on state-of-the-art methods, respectively.