 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-based Meta-Reinforcement Learning for Robust Radar Tracking
Oct 26, 2022



Nowadays, Deep Learning (DL) methods often overcome the limitations of traditional signal processing approaches. Nevertheless, DL methods are barely applied in real-life applications. This is mainly due to limited robustness and distributional shift between training and test data. To this end, recent work has proposed uncertainty mechanisms to increase their reliability. Besides, meta-learning aims at improving the generalization capability of DL models. By taking advantage of that, this paper proposes an uncertainty-based Meta-Reinforcement Learning (Meta-RL) approach with Out-of-Distribution (OOD) detection. The presented method performs a given task in unseen environments and provides information about its complexity. This is done by determining first and second-order statistics on the estimated reward. Using information about its complexity, the proposed algorithm is able to point out when tracking is reliable. To evaluate the proposed method, we benchmark it on a radar-tracking dataset. There, we show that our method outperforms related Meta-RL approaches on unseen tracking scenarios in peak performance by 16% and the baseline by 35% while detecting OOD data with an F1-Score of 72%. This shows that our method is robust to environmental changes and reliably detects OOD scenarios.
MEET: A Monte Carlo Exploration-Exploitation Trade-off for Buffer Sampling
Oct 24, 2022Data selection is essential for any data-based optimization technique, such as Reinforcement Learning. State-of-the-art sampling strategies for the experience replay buffer improve the performance of the Reinforcement Learning agent. However, they do not incorporate uncertainty in the Q-Value estimation. Consequently, they cannot adapt the sampling strategies, including exploration and exploitation of transitions, to the complexity of the task. To address this, this paper proposes a new sampling strategy that leverages the exploration-exploitation trade-off. This is enabled by the uncertainty estimation of the Q-Value function, which guides the sampling to explore more significant transitions and, thus, learn a more efficient policy. Experiments on classical control environments demonstrate stable results across various environments. They show that the proposed method outperforms state-of-the-art sampling strategies for dense rewards w.r.t. convergence and peak performance by 26% on average.
Light-weight Gesture Sensing Using FMCW Radar Time Series Data
Nov 22, 2021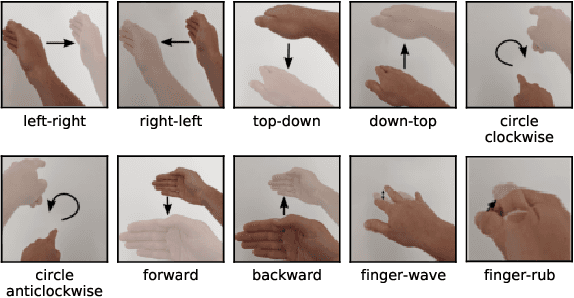
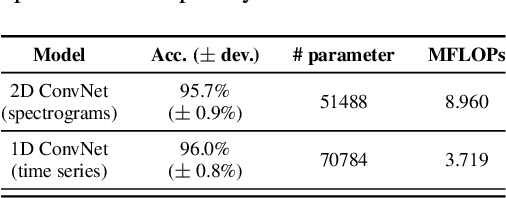

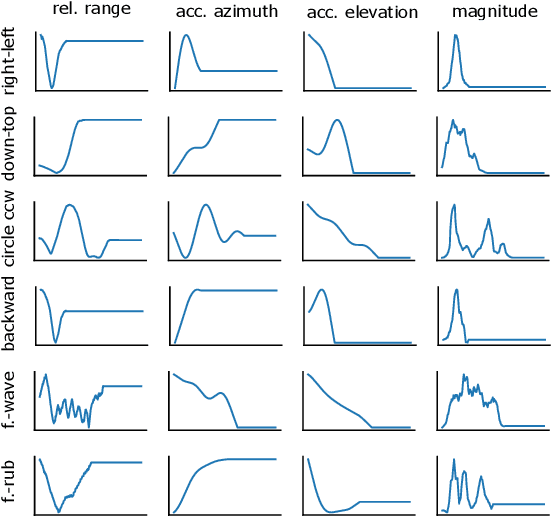
The paper proposes a novel feature extraction approach for FMCW radar systems in the field of short-range gesture sensing. A light-weight processing is proposed which reduces a series of 3D radar data cubes to four 1D time signals containing information about range, azimuth angle, elevation angle and magnitude. The processing is entirely performed in the time domain without using any Fourier transformation and enables the training of a deep neural network directly on the raw time domain data. It is shown experimentally on real world data, that the proposed processing retains the same expressive power as conventional radar processing to range-, Doppler- and angle-spectrograms. Further, the computational complexity is significantly reduced which makes it perfectly suitable for embedded devices. The system is able to recognize ten different gestures with an accuracy of about 95% and is running in real time on a Raspberry Pi 3 B. The delay between end of gesture and prediction is only 150 ms.
Label-Aware Ranked Loss for robust People Counting using Automotive in-cabin Radar
Oct 12, 2021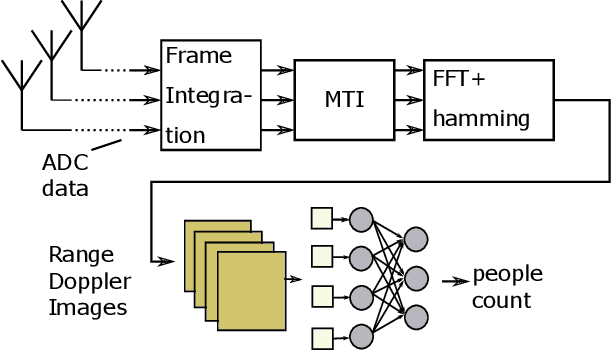
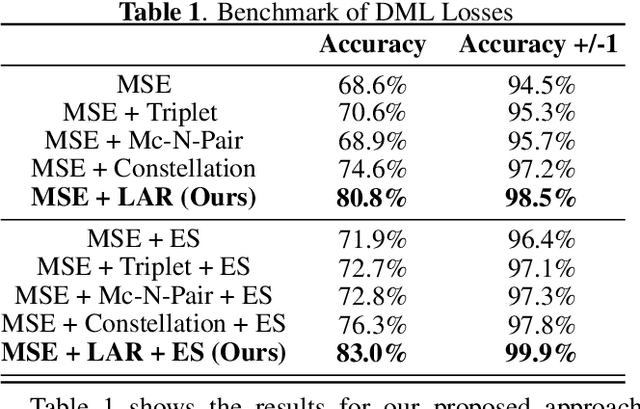
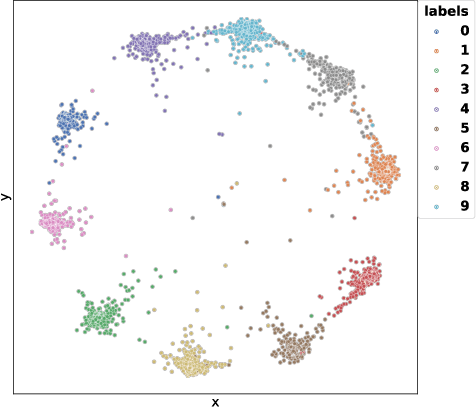
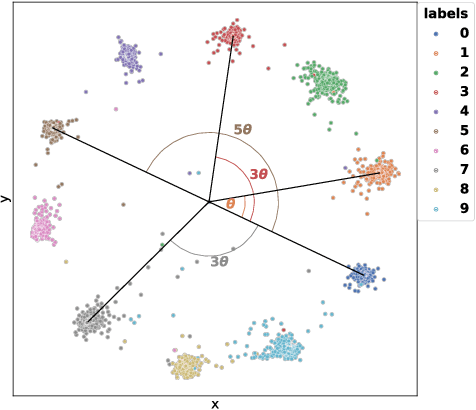
In this paper, we introduce the Label-Aware Ranked loss, a novel metric loss function. Compared to the state-of-the-art Deep Metric Learning losses, this function takes advantage of the ranked ordering of the labels in regression problems. To this end, we first show that the loss minimises when datapoints of different labels are ranked and laid at uniform angles between each other in the embedding space. Then, to measure its performance, we apply the proposed loss on a regression task of people counting with a short-range radar in a challenging scenario, namely a vehicle cabin. The introduced approach improves the accuracy as well as the neighboring labels accuracy up to 83.0% and 99.9%: An increase of 6.7%and 2.1% on state-of-the-art methods, respectively.