 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConjugated Semantic Pool Improves OOD Detection with Pre-trained Vision-Language Models
Oct 11, 2024A straightforward pipeline for zero-shot out-of-distribution (OOD) detection involves selecting potential OOD labels from an extensive semantic pool and then leveraging a pre-trained vision-language model to perform classification on both in-distribution (ID) and OOD labels. In this paper, we theorize that enhancing performance requires expanding the semantic pool, while increasing the expected probability of selected OOD labels being activated by OOD samples, and ensuring low mutual dependence among the activations of these OOD labels. A natural expansion manner is to adopt a larger lexicon; however, the inevitable introduction of numerous synonyms and uncommon words fails to meet the above requirements, indicating that viable expansion manners move beyond merely selecting words from a lexicon. Since OOD detection aims to correctly classify input images into ID/OOD class groups, we can "make up" OOD label candidates which are not standard class names but beneficial for the process. Observing that the original semantic pool is comprised of unmodified specific class names, we correspondingly construct a conjugated semantic pool (CSP) consisting of modified superclass names, each serving as a cluster center for samples sharing similar properties across different categories. Consistent with our established theory, expanding OOD label candidates with the CSP satisfies the requirements and outperforms existing works by 7.89% in FPR95. Codes are available in https://github.com/MengyuanChen21/NeurIPS2024-CSP.
Revisiting Essential and Nonessential Settings of Evidential Deep Learning
Oct 01, 2024



Evidential Deep Learning (EDL) is an emerging method for uncertainty estimation that provides reliable predictive uncertainty in a single forward pass, attracting significant attention. Grounded in subjective logic, EDL derives Dirichlet concentration parameters from neural networks to construct a Dirichlet probability density function (PDF), modeling the distribution of class probabilities. Despite its success, EDL incorporates several nonessential settings: In model construction, (1) a commonly ignored prior weight parameter is fixed to the number of classes, while its value actually impacts the balance between the proportion of evidence and its magnitude in deriving predictive scores. In model optimization, (2) the empirical risk features a variance-minimizing optimization term that biases the PDF towards a Dirac delta function, potentially exacerbating overconfidence. (3) Additionally, the structural risk typically includes a KL-divergence-minimizing regularization, whose optimization direction extends beyond the intended purpose and contradicts common sense, diminishing the information carried by the evidence magnitude. Therefore, we propose Re-EDL, a simplified yet more effective variant of EDL, by relaxing the nonessential settings and retaining the essential one, namely, the adoption of projected probability from subjective logic. Specifically, Re-EDL treats the prior weight as an adjustable hyperparameter rather than a fixed scalar, and directly optimizes the expectation of the Dirichlet PDF provided by deprecating both the variance-minimizing optimization term and the divergence regularization term. Extensive experiments and state-of-the-art performance validate the effectiveness of our method. The source code is available at https://github.com/MengyuanChen21/Re-EDL.
A Comprehensive Survey on Evidential Deep Learning and Its Applications
Sep 07, 2024



Reliable uncertainty estimation has become a crucial requirement for the industrial deployment of deep learning algorithms, particularly in high-risk applications such as autonomous driving and medical diagnosis. However, mainstream uncertainty estimation methods, based on deep ensembling or Bayesian neural networks, generally impose substantial computational overhead. To address this challenge, a novel paradigm called Evidential Deep Learning (EDL) has emerged, providing reliable uncertainty estimation with minimal additional computation in a single forward pass. This survey provides a comprehensive overview of the current research on EDL, designed to offer readers a broad introduction to the field without assuming prior knowledge. Specifically, we first delve into the theoretical foundation of EDL, the subjective logic theory, and discuss its distinctions from other uncertainty estimation frameworks. We further present existing theoretical advancements in EDL from four perspectives: reformulating the evidence collection process, improving uncertainty estimation via OOD samples, delving into various training strategies, and evidential regression networks. Thereafter, we elaborate on its extensive applications across various machine learning paradigms and downstream tasks. In the end, an outlook on future directions for better performances and broader adoption of EDL is provided, highlighting potential research avenues.
Fine-grained Temporal Contrastive Learning for Weakly-supervised Temporal Action Localization
Mar 31, 2022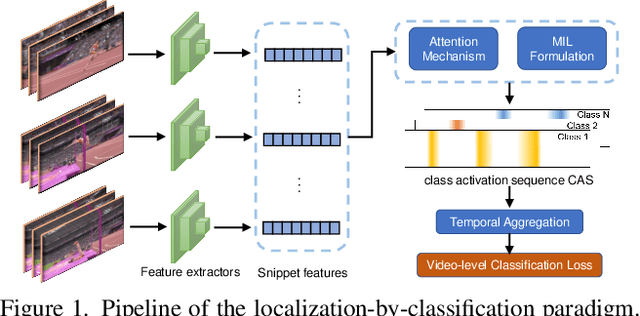
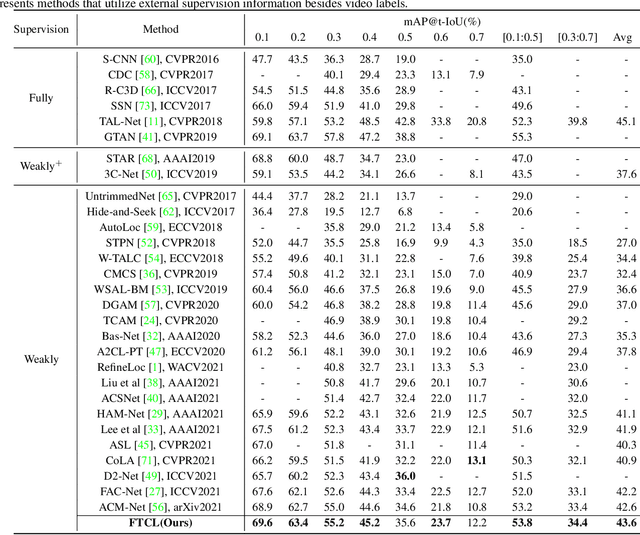


We target at the task of weakly-supervised action localization (WSAL), where only video-level action labels are available during model training. Despite the recent progress, existing methods mainly embrace a localization-by-classification paradigm and overlook the fruitful fine-grained temporal distinctions between video sequences, thus suffering from severe ambiguity in classification learning and classification-to-localization adaption. This paper argues that learning by contextually comparing sequence-to-sequence distinctions offers an essential inductive bias in WSAL and helps identify coherent action instances. Specifically, under a differentiable dynamic programming formulation, two complementary contrastive objectives are designed, including Fine-grained Sequence Distance (FSD) contrasting and Longest Common Subsequence (LCS) contrasting, where the first one considers the relations of various action/background proposals by using match, insert, and delete operators and the second one mines the longest common subsequences between two videos. Both contrasting modules can enhance each other and jointly enjoy the merits of discriminative action-background separation and alleviated task gap between classification and localization. Extensive experiments show that our method achieves state-of-the-art performance on two popular benchmarks. Our code is available at https://github.com/MengyuanChen21/CVPR2022-FTCL.
Learnability and Robustness of Shallow Neural Networks Learned With a Performance-Driven BP and a Variant PSO For Edge Decision-Making
Aug 13, 2020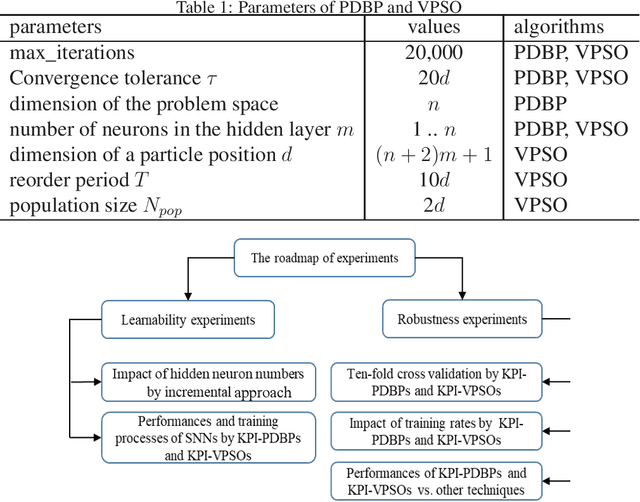
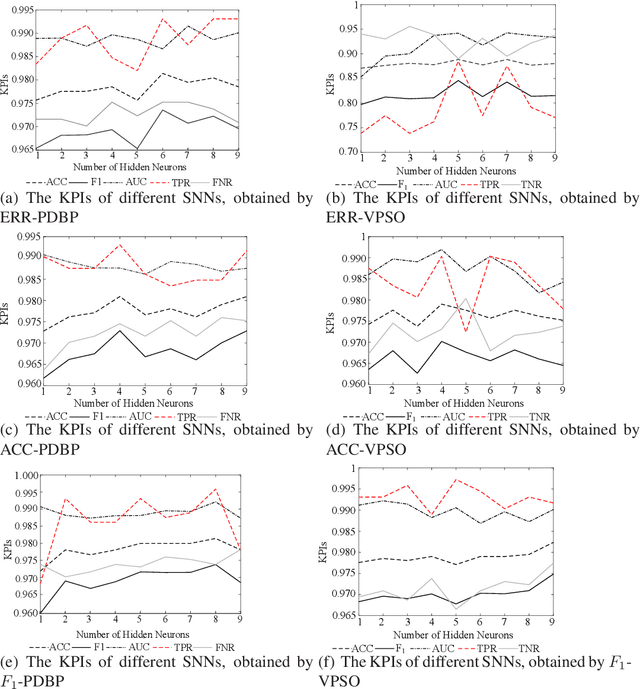
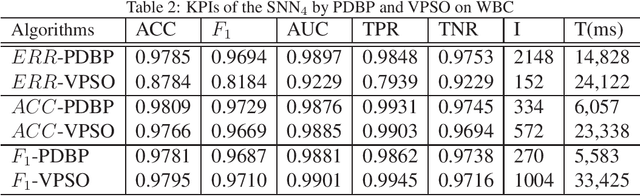
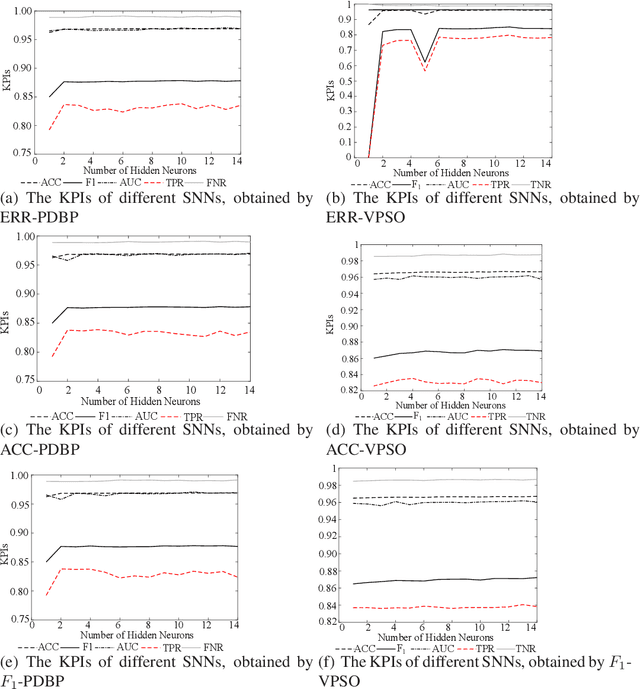
In many cases, the computing resources are limited without the benefit from GPU, especially in the edge devices of IoT enabled systems. It may not be easy to implement complex AI models in edge devices. The Universal Approximation Theorem states that a shallow neural network (SNN) can represent any nonlinear function. However, how fat is an SNN enough to solve a nonlinear decision-making problem in edge devices? In this paper, we focus on the learnability and robustness of SNNs, obtained by a greedy tight force heuristic algorithm (performance driven BP) and a loose force meta-heuristic algorithm (a variant of PSO). Two groups of experiments are conducted to examine the learnability and the robustness of SNNs with Sigmoid activation, learned/optimised by KPI-PDBPs and KPI-VPSOs, where, KPIs (key performance indicators: error (ERR), accuracy (ACC) and $F_1$ score) are the objectives, driving the searching process. An incremental approach is applied to examine the impact of hidden neuron numbers on the performance of SNNs, learned/optimised by KPI-PDBPs and KPI-VPSOs. From the engineering prospective, all sensors are well justified for a specific task. Hence, all sensor readings should be strongly correlated to the target. Therefore, the structure of an SNN should depend on the dimensions of a problem space. The experimental results show that the number of hidden neurons up to the dimension number of a problem space is enough; the learnability of SNNs, produced by KPI-PDBP, is better than that of SNNs, optimized by KPI-VPSO, regarding the performance and learning time on the training data sets; the robustness of SNNs learned by KPI-PDBPs and KPI-VPSOs depends on the data sets; and comparing with other classic machine learning models, ACC-PDBPs win for almost all tested data sets.
Inference for Network Structure and Dynamics from Time Series Data via Graph Neural Network
Jan 18, 2020
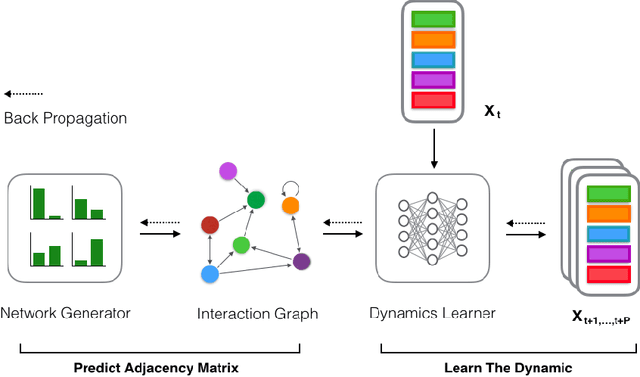
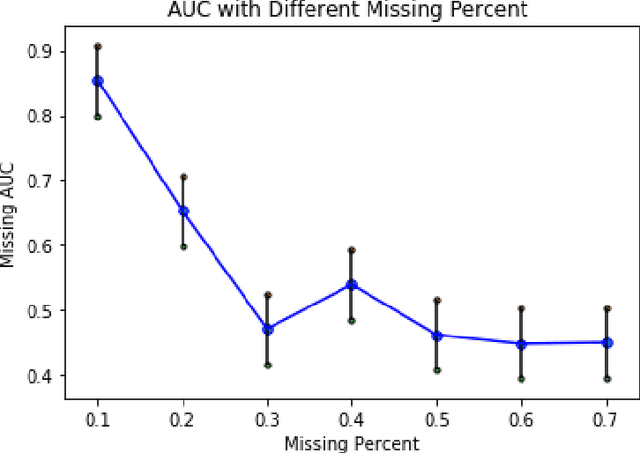
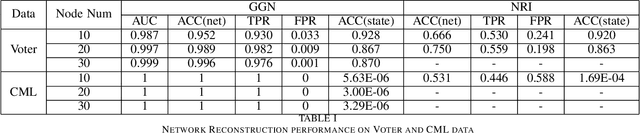
Network structures in various backgrounds play important roles in social, technological, and biological systems. However, the observable network structures in real cases are often incomplete or unavailable due to measurement errors or private protection issues. Therefore, inferring the complete network structure is useful for understanding complex systems. The existing studies have not fully solved the problem of inferring network structure with partial or no information about connections or nodes. In this paper, we tackle the problem by utilizing time series data generated by network dynamics. We regard the network inference problem based on dynamical time series data as a problem of minimizing errors for predicting future states and proposed a novel data-driven deep learning model called Gumbel Graph Network (GGN) to solve the two kinds of network inference problems: Network Reconstruction and Network Completion. For the network reconstruction problem, the GGN framework includes two modules: the dynamics learner and the network generator. For the network completion problem, GGN adds a new module called the States Learner to infer missing parts of the network. We carried out experiments on discrete and continuous time series data. The experiments show that our method can reconstruct up to 100% network structure on the network reconstruction task. While the model can also infer the unknown parts of the structure with up to 90% accuracy when some nodes are missing. And the accuracy decays with the increase of the fractions of missing nodes. Our framework may have wide application areas where the network structure is hard to obtained and the time series data is rich.