 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnability and Robustness of Shallow Neural Networks Learned With a Performance-Driven BP and a Variant PSO For Edge Decision-Making
Aug 13, 2020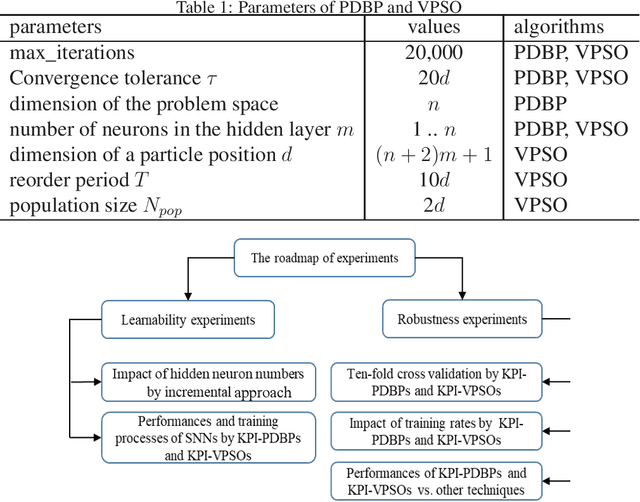
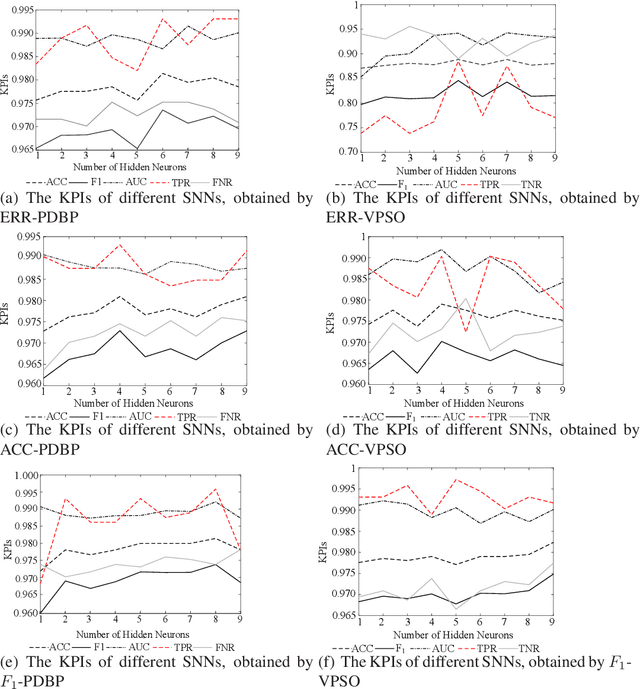
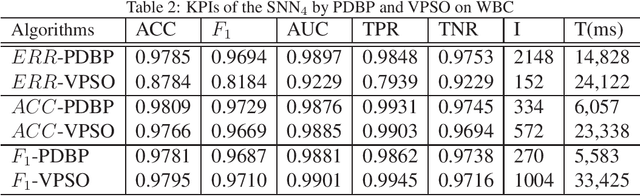
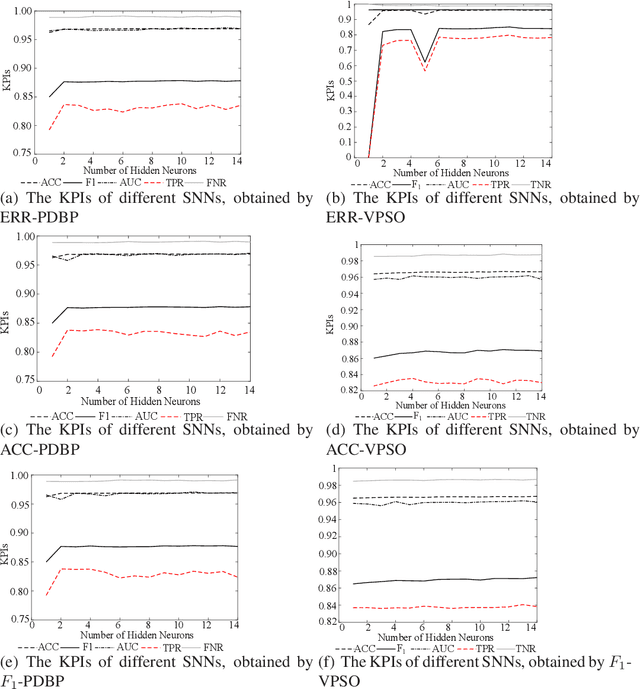
In many cases, the computing resources are limited without the benefit from GPU, especially in the edge devices of IoT enabled systems. It may not be easy to implement complex AI models in edge devices. The Universal Approximation Theorem states that a shallow neural network (SNN) can represent any nonlinear function. However, how fat is an SNN enough to solve a nonlinear decision-making problem in edge devices? In this paper, we focus on the learnability and robustness of SNNs, obtained by a greedy tight force heuristic algorithm (performance driven BP) and a loose force meta-heuristic algorithm (a variant of PSO). Two groups of experiments are conducted to examine the learnability and the robustness of SNNs with Sigmoid activation, learned/optimised by KPI-PDBPs and KPI-VPSOs, where, KPIs (key performance indicators: error (ERR), accuracy (ACC) and $F_1$ score) are the objectives, driving the searching process. An incremental approach is applied to examine the impact of hidden neuron numbers on the performance of SNNs, learned/optimised by KPI-PDBPs and KPI-VPSOs. From the engineering prospective, all sensors are well justified for a specific task. Hence, all sensor readings should be strongly correlated to the target. Therefore, the structure of an SNN should depend on the dimensions of a problem space. The experimental results show that the number of hidden neurons up to the dimension number of a problem space is enough; the learnability of SNNs, produced by KPI-PDBP, is better than that of SNNs, optimized by KPI-VPSO, regarding the performance and learning time on the training data sets; the robustness of SNNs learned by KPI-PDBPs and KPI-VPSOs depends on the data sets; and comparing with other classic machine learning models, ACC-PDBPs win for almost all tested data sets.
A Heuristically Self-Organised Linguistic Attribute Deep Learning in Edge Computing For IoT Intelligence
Jun 08, 2020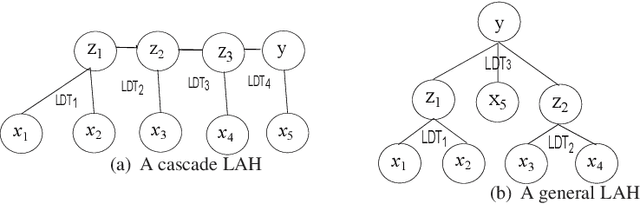


With the development of Internet of Things (IoT), IoT intelligence becomes emerging technology. "Curse of Dimensionality" is the barrier of data fusion in edge devices for the success of IoT intelligence. A Linguistic Attribute Hierarchy (LAH), embedded with Linguistic Decision Trees (LDTs), can represent a new attribute deep learning. In contrast to the conventional deep learning, an LAH could overcome the shortcoming of missing interpretation by providing transparent information propagation through the rules, produced by LDTs in the LAH. Similar to the conventional deep learning, the computing complexity of optimising LAHs blocks the applications of LAHs. In this paper, we propose a heuristic approach to constructing an LAH, embedded with LDTs for decision making or classification by utilising the distance correlations between attributes and between attributes and the goal variable. The set of attributes is divided to some attribute clusters, and then they are heuristically organised to form a linguistic attribute hierarchy. The proposed approach was validated with some benchmark decision making or classification problems from the UCI machine learning repository. The experimental results show that the proposed self-organisation algorithm can construct an effective and efficient linguistic attribute hierarchy. Such a self-organised linguistic attribute hierarchy embedded with LDTs can not only efficiently tackle "curse of dimensionality" in a single LDT for data fusion with massive attributes, but also achieve better or comparable performance on decision making or classification, compared to the single LDT for the problem to be solved. The self-organisation algorithm is much efficient than the Genetic Algorithm in Wrapper for the optimisation of LAHs. This makes it feasible to embed the self-organisation algorithm in edge devices for IoT intelligence.