 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Temporal Contrastive Learning for Weakly-supervised Temporal Action Localization
Paper and Code
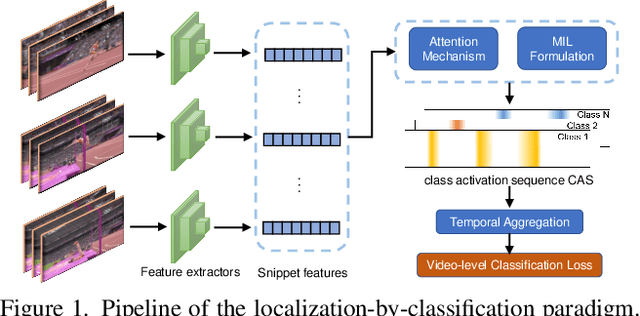
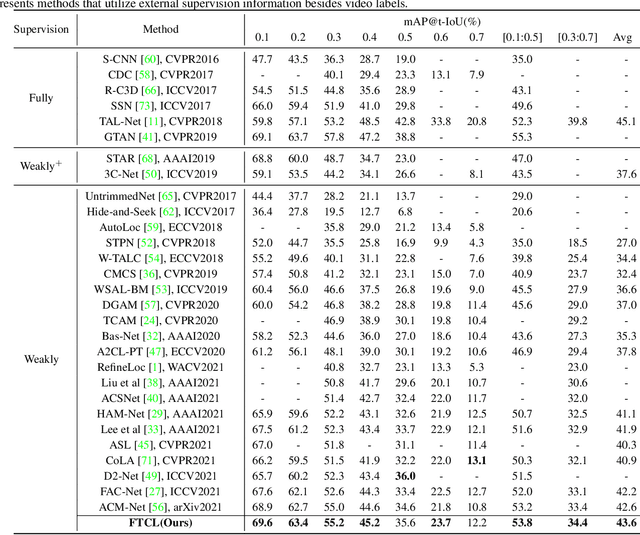


We target at the task of weakly-supervised action localization (WSAL), where only video-level action labels are available during model training. Despite the recent progress, existing methods mainly embrace a localization-by-classification paradigm and overlook the fruitful fine-grained temporal distinctions between video sequences, thus suffering from severe ambiguity in classification learning and classification-to-localization adaption. This paper argues that learning by contextually comparing sequence-to-sequence distinctions offers an essential inductive bias in WSAL and helps identify coherent action instances. Specifically, under a differentiable dynamic programming formulation, two complementary contrastive objectives are designed, including Fine-grained Sequence Distance (FSD) contrasting and Longest Common Subsequence (LCS) contrasting, where the first one considers the relations of various action/background proposals by using match, insert, and delete operators and the second one mines the longest common subsequences between two videos. Both contrasting modules can enhance each other and jointly enjoy the merits of discriminative action-background separation and alleviated task gap between classification and localization. Extensive experiments show that our method achieves state-of-the-art performance on two popular benchmarks. Our code is available at https://github.com/MengyuanChen21/CVPR2022-FTCL.