 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTumour Ellipsification in Ultrasound Images for Treatment Prediction in Breast Cancer
Jan 13, 2017
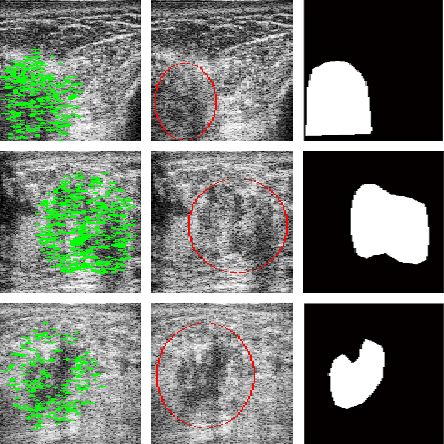
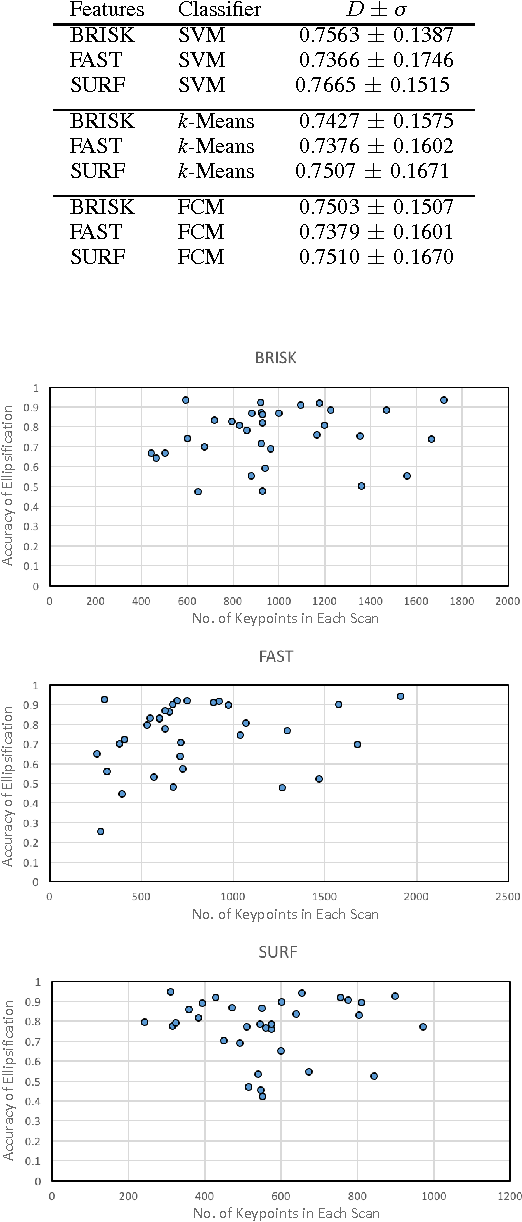
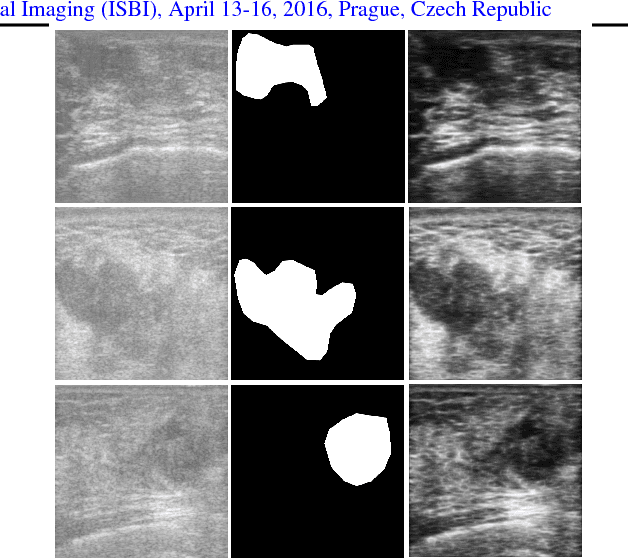
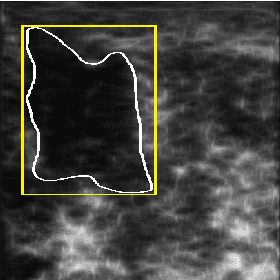
Recent advances in using quantitative ultrasound (QUS) methods have provided a promising framework to non-invasively and inexpensively monitor or predict the effectiveness of therapeutic cancer responses. One of the earliest steps in using QUS methods is contouring a region of interest (ROI) inside the tumour in ultrasound B-mode images. While manual segmentation is a very time-consuming and tedious task for human experts, auto-contouring is also an extremely difficult task for computers due to the poor quality of ultrasound B-mode images. However, for the purpose of cancer response prediction, a rough boundary of the tumour as an ROI is only needed. In this research, a semi-automated tumour localization approach is proposed for ROI estimation in ultrasound B-mode images acquired from patients with locally advanced breast cancer (LABC). The proposed approach comprised several modules, including 1) feature extraction using keypoint descriptors, 2) augmenting the feature descriptors with the distance of the keypoints to the user-input pixel as the centre of the tumour, 3) supervised learning using a support vector machine (SVM) to classify keypoints as "tumour" or "non-tumour", and 4) computation of an ellipse as an outline of the ROI representing the tumour. Experiments with 33 B-mode images from 10 LABC patients yielded promising results with an accuracy of 76.7% based on the Dice coefficient performance measure. The results demonstrated that the proposed method can potentially be used as the first stage in a computer-assisted cancer response prediction system for semi-automated contouring of breast tumours.
Semi-supervised Dictionary Learning Based on Hilbert-Schmidt Independence Criterion
Apr 25, 2016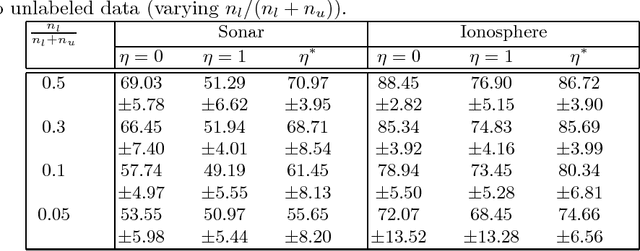
In this paper, a novel semi-supervised dictionary learning and sparse representation (SS-DLSR) is proposed. The proposed method benefits from the supervisory information by learning the dictionary in a space where the dependency between the data and class labels is maximized. This maximization is performed using Hilbert-Schmidt independence criterion (HSIC). On the other hand, the global distribution of the underlying manifolds were learned from the unlabeled data by minimizing the distances between the unlabeled data and the corresponding nearest labeled data in the space of the dictionary learned. The proposed SS-DLSR algorithm has closed-form solutions for both the dictionary and sparse coefficients, and therefore does not have to learn the two iteratively and alternately as is common in the literature of the DLSR. This makes the solution for the proposed algorithm very fast. The experiments confirm the improvement in classification performance on benchmark datasets by including the information from both labeled and unlabeled data, particularly when there are many unlabeled data.
Tumour ROI Estimation in Ultrasound Images via Radon Barcodes in Patients with Locally Advanced Breast Cancer
Feb 08, 2016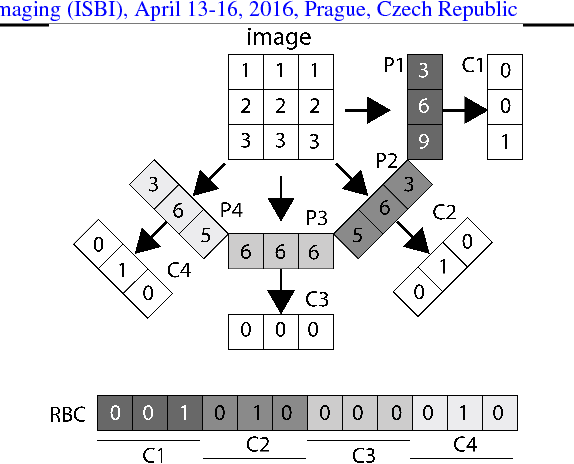
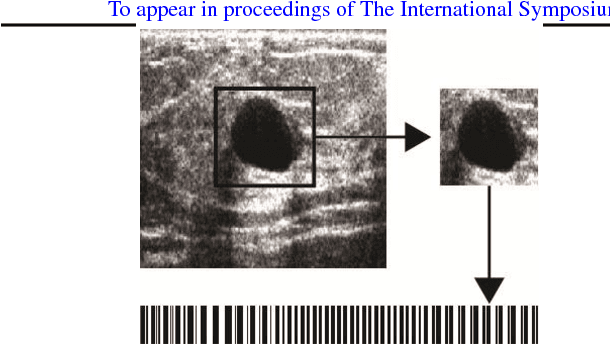
Quantitative ultrasound (QUS) methods provide a promising framework that can non-invasively and inexpensively be used to predict or assess the tumour response to cancer treatment. The first step in using the QUS methods is to select a region of interest (ROI) inside the tumour in ultrasound images. Manual segmentation, however, is very time consuming and tedious. In this paper, a semi-automated approach will be proposed to roughly localize an ROI for a tumour in ultrasound images of patients with locally advanced breast cancer (LABC). Content-based barcodes, a recently introduced binary descriptor based on Radon transform, were used in order to find similar cases and estimate a bounding box surrounding the tumour. Experiments with 33 B-scan images resulted in promising results with an accuracy of $81\%$.
On the Invariance of Dictionary Learning and Sparse Representation to Projecting Data to a Discriminative Space
Jun 11, 2015In this paper, it is proved that dictionary learning and sparse representation is invariant to a linear transformation. It subsumes the special case of transforming/projecting the data into a discriminative space. This is important because recently, supervised dictionary learning algorithms have been proposed, which suggest to include the category information into the learning of dictionary to improve its discriminative power. Among them, there are some approaches that propose to learn the dictionary in a discriminative projected space. To this end, two approaches have been proposed: first, assigning the discriminative basis as the dictionary and second, perform dictionary learning in the projected space. Based on the invariance of dictionary learning to any transformation in general, and to a discriminative space in particular, we advocate the first approach.
Supervised Dictionary Learning and Sparse Representation-A Review
Feb 20, 2015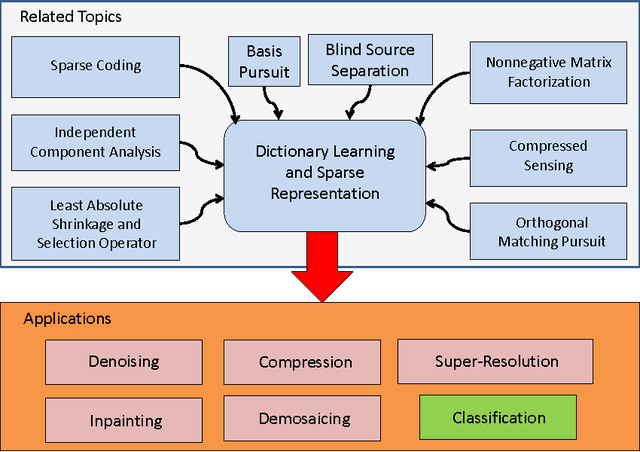
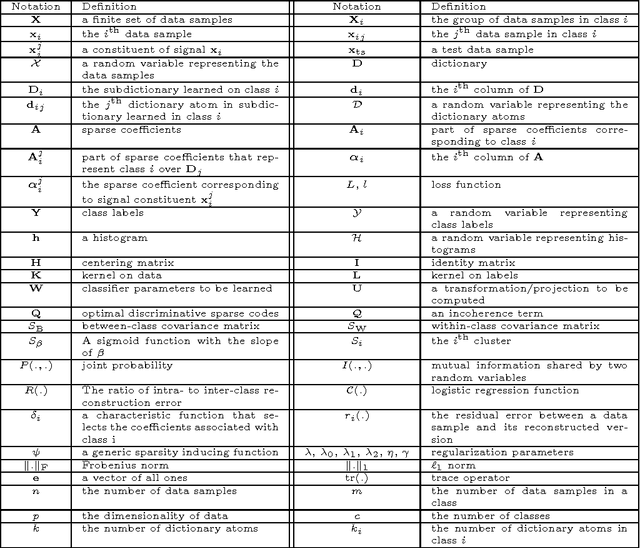
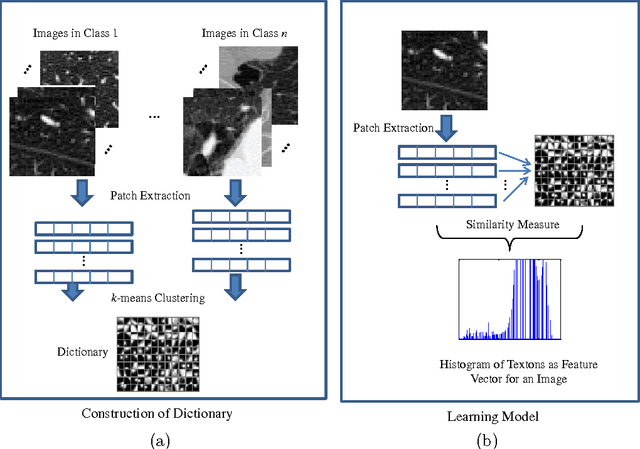
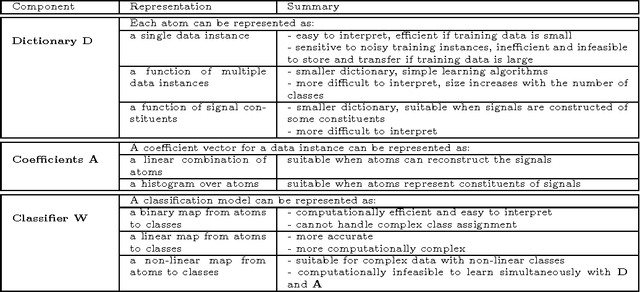
Dictionary learning and sparse representation (DLSR) is a recent and successful mathematical model for data representation that achieves state-of-the-art performance in various fields such as pattern recognition, machine learning, computer vision, and medical imaging. The original formulation for DLSR is based on the minimization of the reconstruction error between the original signal and its sparse representation in the space of the learned dictionary. Although this formulation is optimal for solving problems such as denoising, inpainting, and coding, it may not lead to optimal solution in classification tasks, where the ultimate goal is to make the learned dictionary and corresponding sparse representation as discriminative as possible. This motivated the emergence of a new category of techniques, which is appropriately called supervised dictionary learning and sparse representation (S-DLSR), leading to more optimal dictionary and sparse representation in classification tasks. Despite many research efforts for S-DLSR, the literature lacks a comprehensive view of these techniques, their connections, advantages and shortcomings. In this paper, we address this gap and provide a review of the recently proposed algorithms for S-DLSR. We first present a taxonomy of these algorithms into six categories based on the approach taken to include label information into the learning of the dictionary and/or sparse representation. For each category, we draw connections between the algorithms in this category and present a unified framework for them. We then provide guidelines for applied researchers on how to represent and learn the building blocks of an S-DLSR solution based on the problem at hand. This review provides a broad, yet deep, view of the state-of-the-art methods for S-DLSR and allows for the advancement of research and development in this emerging area of research.
Supervised Texture Classification Using a Novel Compression-Based Similarity Measure
Nov 26, 2013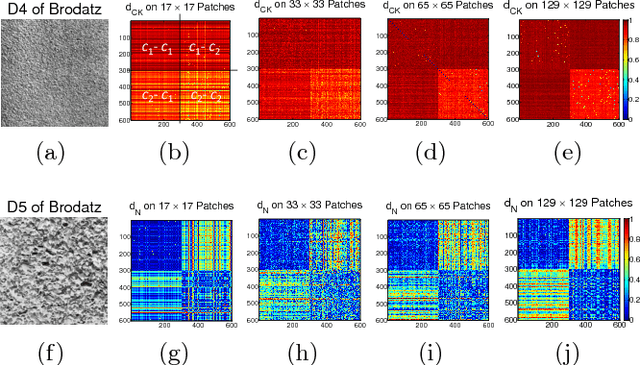
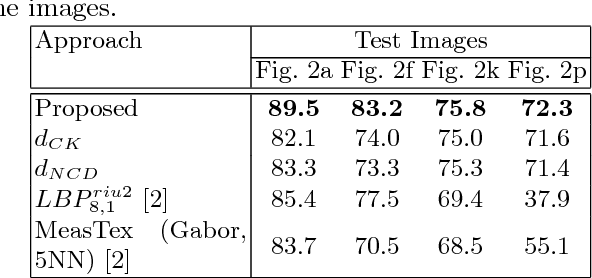

Supervised pixel-based texture classification is usually performed in the feature space. We propose to perform this task in (dis)similarity space by introducing a new compression-based (dis)similarity measure. The proposed measure utilizes two dimensional MPEG-1 encoder, which takes into consideration the spatial locality and connectivity of pixels in the images. The proposed formulation has been carefully designed based on MPEG encoder functionality. To this end, by design, it solely uses P-frame coding to find the (dis)similarity among patches/images. We show that the proposed measure works properly on both small and large patch sizes. Experimental results show that the proposed approach significantly improves the performance of supervised pixel-based texture classification on Brodatz and outdoor images compared to other compression-based dissimilarity measures as well as approaches performed in feature space. It also improves the computation speed by about 40% compared to its rivals.
Kernelized Supervised Dictionary Learning
Nov 26, 2013

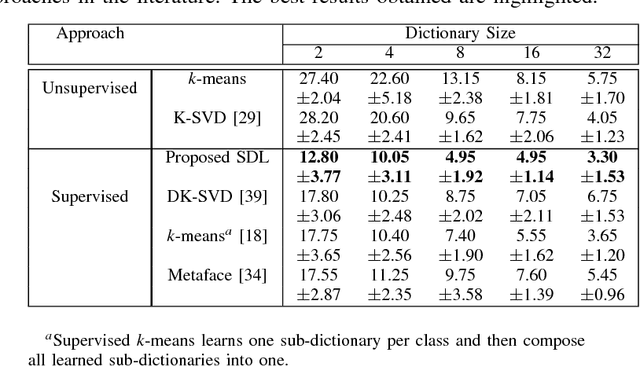
In this paper, we propose supervised dictionary learning (SDL) by incorporating information on class labels into the learning of the dictionary. To this end, we propose to learn the dictionary in a space where the dependency between the signals and their corresponding labels is maximized. To maximize this dependency, the recently introduced Hilbert Schmidt independence criterion (HSIC) is used. One of the main advantages of this novel approach for SDL is that it can be easily kernelized by incorporating a kernel, particularly a data-derived kernel such as normalized compression distance, into the formulation. The learned dictionary is compact and the proposed approach is fast. We show that it outperforms other unsupervised and supervised dictionary learning approaches in the literature, using real-world data.
A Two-Stage Combined Classifier in Scale Space Texture Classification
Jul 17, 2012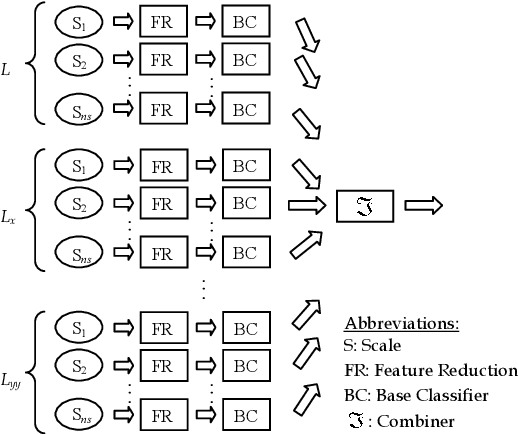



Textures often show multiscale properties and hence multiscale techniques are considered useful for texture analysis. Scale-space theory as a biologically motivated approach may be used to construct multiscale textures. In this paper various ways are studied to combine features on different scales for texture classification of small image patches. We use the N-jet of derivatives up to the second order at different scales to generate distinct pattern representations (DPR) of feature subsets. Each feature subset in the DPR is given to a base classifier (BC) of a two-stage combined classifier. The decisions made by these BCs are combined in two stages over scales and derivatives. Various combining systems and their significances and differences are discussed. The learning curves are used to evaluate the performances. We found for small sample sizes combining classifiers performs significantly better than combining feature spaces (CFS). It is also shown that combining classifiers performs better than the support vector machine on CFS in multiscale texture classification.