 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Dictionary Learning and Sparse Representation-A Review
Paper and Code
Feb 20, 2015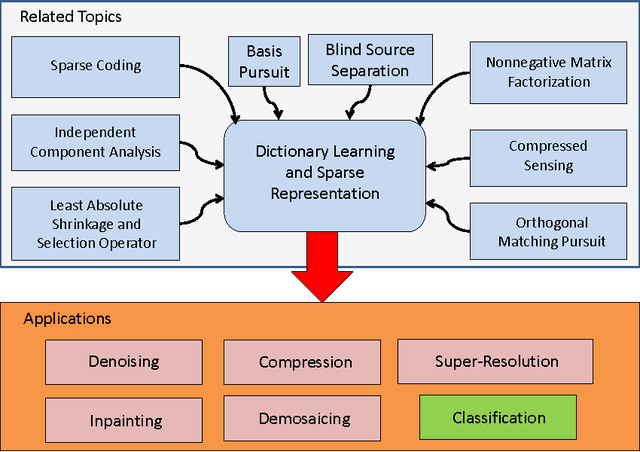
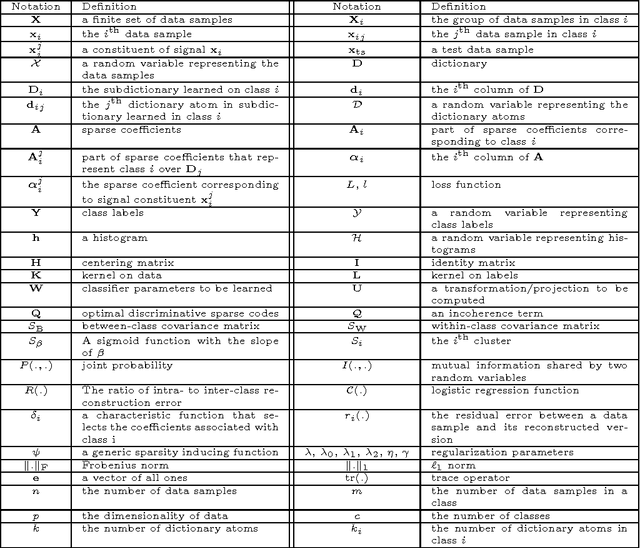
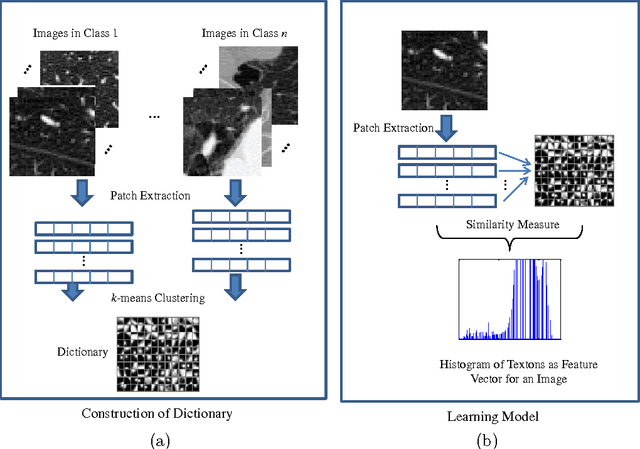
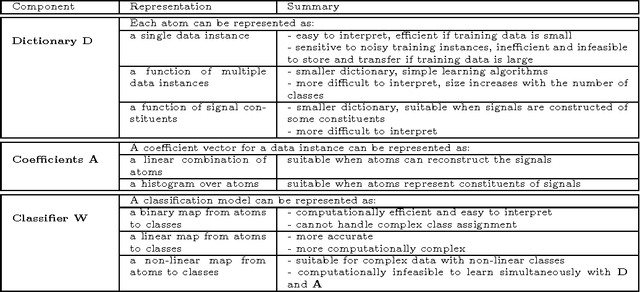
Dictionary learning and sparse representation (DLSR) is a recent and successful mathematical model for data representation that achieves state-of-the-art performance in various fields such as pattern recognition, machine learning, computer vision, and medical imaging. The original formulation for DLSR is based on the minimization of the reconstruction error between the original signal and its sparse representation in the space of the learned dictionary. Although this formulation is optimal for solving problems such as denoising, inpainting, and coding, it may not lead to optimal solution in classification tasks, where the ultimate goal is to make the learned dictionary and corresponding sparse representation as discriminative as possible. This motivated the emergence of a new category of techniques, which is appropriately called supervised dictionary learning and sparse representation (S-DLSR), leading to more optimal dictionary and sparse representation in classification tasks. Despite many research efforts for S-DLSR, the literature lacks a comprehensive view of these techniques, their connections, advantages and shortcomings. In this paper, we address this gap and provide a review of the recently proposed algorithms for S-DLSR. We first present a taxonomy of these algorithms into six categories based on the approach taken to include label information into the learning of the dictionary and/or sparse representation. For each category, we draw connections between the algorithms in this category and present a unified framework for them. We then provide guidelines for applied researchers on how to represent and learn the building blocks of an S-DLSR solution based on the problem at hand. This review provides a broad, yet deep, view of the state-of-the-art methods for S-DLSR and allows for the advancement of research and development in this emerging area of research.