 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeWarp: Evaluating Web Agents by Revisiting the Past
Mar 05, 2026The improvement of web agents on current benchmarks raises the question: Do today's agents perform just as well when the web changes? We introduce TimeWarp, a benchmark that emulates the evolving web using containerized environments that vary in UI, design, and layout. TimeWarp consists of three web environments, each with six UI versions spanning different eras of the internet, paired with a set of complex, realistic tasks requiring different forms of web navigation. Our experiments reveal web agents' vulnerability to changes and the limitations of behavior cloning (BC) on single-version trajectories. To address this, we propose TimeTraj, a simple yet effective algorithm that uses plan distillation to collect trajectories across multiple versions. By training agents on teacher rollouts using our BC-variant, we achieve substantial performance gains: $20.4\%\rightarrow37.7\%$ for Qwen-3 4B and $0\%\rightarrow27.0\%$ for Llama-3.1 8B models. We hope our work helps researchers study generalization across web designs and unlock a new paradigm for collecting plans rather than trajectories, thereby improving the robustness of web agents.
ChitroJera: A Regionally Relevant Visual Question Answering Dataset for Bangla
Oct 19, 2024Visual Question Answer (VQA) poses the problem of answering a natural language question about a visual context. Bangla, despite being a widely spoken language, is considered low-resource in the realm of VQA due to the lack of a proper benchmark dataset. The absence of such datasets challenges models that are known to be performant in other languages. Furthermore, existing Bangla VQA datasets offer little cultural relevance and are largely adapted from their foreign counterparts. To address these challenges, we introduce a large-scale Bangla VQA dataset titled ChitroJera, totaling over 15k samples where diverse and locally relevant data sources are used. We assess the performance of text encoders, image encoders, multimodal models, and our novel dual-encoder models. The experiments reveal that the pre-trained dual-encoders outperform other models of its scale. We also evaluate the performance of large language models (LLMs) using prompt-based techniques, with LLMs achieving the best performance. Given the underdeveloped state of existing datasets, we envision ChitroJera expanding the scope of Vision-Language tasks in Bangla.
BANTH: A Multi-label Hate Speech Detection Dataset for Transliterated Bangla
Oct 17, 2024
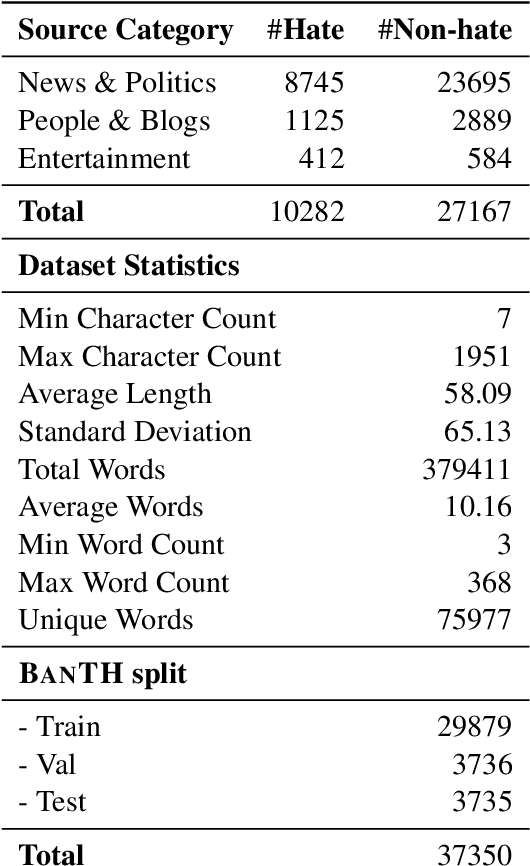

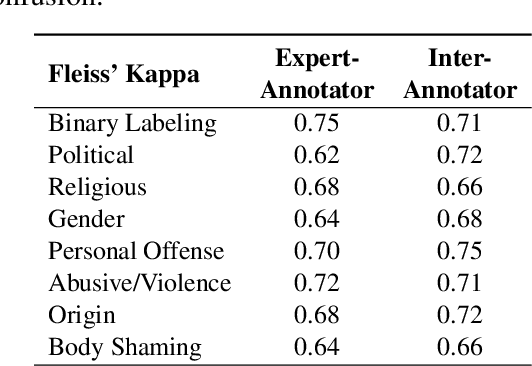
The proliferation of transliterated texts in digital spaces has emphasized the need for detecting and classifying hate speech in languages beyond English, particularly in low-resource languages. As online discourse can perpetuate discrimination based on target groups, e.g. gender, religion, and origin, multi-label classification of hateful content can help in comprehending hate motivation and enhance content moderation. While previous efforts have focused on monolingual or binary hate classification tasks, no work has yet addressed the challenge of multi-label hate speech classification in transliterated Bangla. We introduce BanTH, the first multi-label transliterated Bangla hate speech dataset comprising 37.3k samples. The samples are sourced from YouTube comments, where each instance is labeled with one or more target groups, reflecting the regional demographic. We establish novel transformer encoder-based baselines by further pre-training on transliterated Bangla corpus. We also propose a novel translation-based LLM prompting strategy for transliterated text. Experiments reveal that our further pre-trained encoders are achieving state-of-the-art performance on the BanTH dataset, while our translation-based prompting outperforms other strategies in the zero-shot setting. The introduction of BanTH not only fills a critical gap in hate speech research for Bangla but also sets the stage for future exploration into code-mixed and multi-label classification challenges in underrepresented languages.
Contextual Breach: Assessing the Robustness of Transformer-based QA Models
Sep 18, 2024Contextual question-answering models are susceptible to adversarial perturbations to input context, commonly observed in real-world scenarios. These adversarial noises are designed to degrade the performance of the model by distorting the textual input. We introduce a unique dataset that incorporates seven distinct types of adversarial noise into the context, each applied at five different intensity levels on the SQuAD dataset. To quantify the robustness, we utilize robustness metrics providing a standardized measure for assessing model performance across varying noise types and levels. Experiments on transformer-based question-answering models reveal robustness vulnerabilities and important insights into the model's performance in realistic textual input.
BnSentMix: A Diverse Bengali-English Code-Mixed Dataset for Sentiment Analysis
Aug 16, 2024The widespread availability of code-mixed data can provide valuable insights into low-resource languages like Bengali, which have limited datasets. Sentiment analysis has been a fundamental text classification task across several languages for code-mixed data. However, there has yet to be a large-scale and diverse sentiment analysis dataset on code-mixed Bengali. We address this limitation by introducing BnSentMix, a sentiment analysis dataset on code-mixed Bengali consisting of 20,000 samples with $4$ sentiment labels from Facebook, YouTube, and e-commerce sites. We ensure diversity in data sources to replicate realistic code-mixed scenarios. Additionally, we propose $14$ baseline methods including novel transformer encoders further pre-trained on code-mixed Bengali-English, achieving an overall accuracy of $69.8\%$ and an F1 score of $69.1\%$ on sentiment classification tasks. Detailed analyses reveal variations in performance across different sentiment labels and text types, highlighting areas for future improvement.
Leveraging FourierKAN Classification Head for Pre-Trained Transformer-based Text Classification
Aug 16, 2024For many years, transformer-based pre-trained models with Multi-layer Perceptron (MLP) heads have been the standard for text classification tasks. However, the fixed non-linear functions employed by MLPs often fall short of capturing the intricacies of the contextualized embeddings produced by pre-trained encoders. Furthermore, MLPs usually require a significant number of training parameters, which can be computationally expensive. In this work, we introduce FourierKAN (FR-KAN), a variant of the promising MLP alternative called Kolmogorov-Arnold Networks (KANs), as classification heads for transformer-based encoders. Our studies reveal an average increase of 10% in accuracy and 11% in F1-score when incorporating FR-KAN heads instead of traditional MLP heads for several transformer-based pre-trained models across multiple text classification tasks. Beyond improving model accuracy, FR-KAN heads train faster and require fewer parameters. Our research opens new grounds for broader applications of KAN across several Natural Language Processing (NLP) tasks.
Visual Robustness Benchmark for Visual Question Answering (VQA)
Jul 03, 2024Can Visual Question Answering (VQA) systems perform just as well when deployed in the real world? Or are they susceptible to realistic corruption effects e.g. image blur, which can be detrimental in sensitive applications, such as medical VQA? While linguistic or textual robustness has been thoroughly explored in the VQA literature, there has yet to be any significant work on the visual robustness of VQA models. We propose the first large-scale benchmark comprising 213,000 augmented images, challenging the visual robustness of multiple VQA models and assessing the strength of realistic visual corruptions. Additionally, we have designed several robustness evaluation metrics that can be aggregated into a unified metric and tailored to fit a variety of use cases. Our experiments reveal several insights into the relationships between model size, performance, and robustness with the visual corruptions. Our benchmark highlights the need for a balanced approach in model development that considers model performance without compromising the robustness.
From Image to Language: A Critical Analysis of Visual Question Answering Approaches, Challenges, and Opportunities
Nov 01, 2023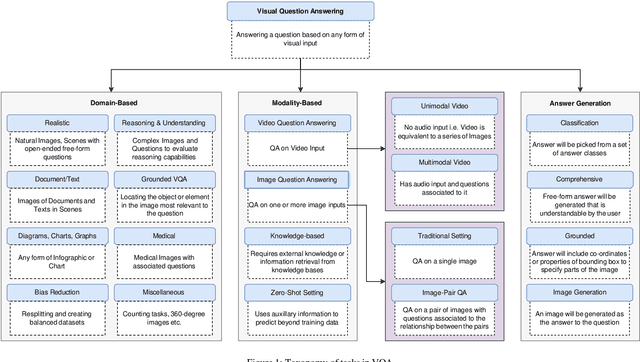
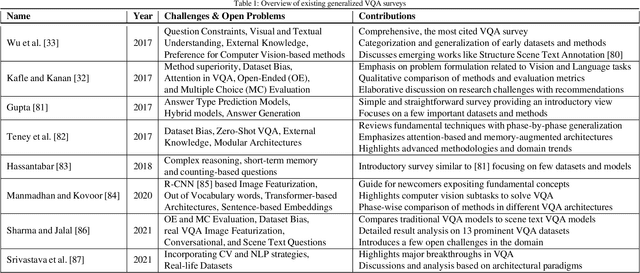
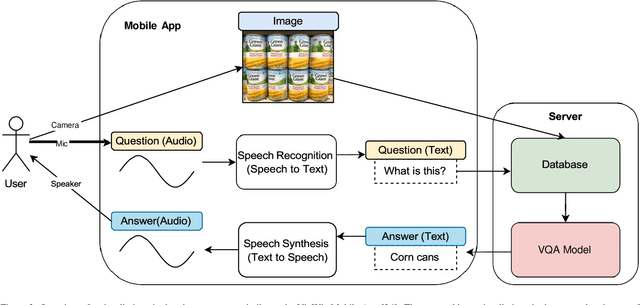
The multimodal task of Visual Question Answering (VQA) encompassing elements of Computer Vision (CV) and Natural Language Processing (NLP), aims to generate answers to questions on any visual input. Over time, the scope of VQA has expanded from datasets focusing on an extensive collection of natural images to datasets featuring synthetic images, video, 3D environments, and various other visual inputs. The emergence of large pre-trained networks has shifted the early VQA approaches relying on feature extraction and fusion schemes to vision language pre-training (VLP) techniques. However, there is a lack of comprehensive surveys that encompass both traditional VQA architectures and contemporary VLP-based methods. Furthermore, the VLP challenges in the lens of VQA haven't been thoroughly explored, leaving room for potential open problems to emerge. Our work presents a survey in the domain of VQA that delves into the intricacies of VQA datasets and methods over the field's history, introduces a detailed taxonomy to categorize the facets of VQA, and highlights the recent trends, challenges, and scopes for improvement. We further generalize VQA to multimodal question answering, explore tasks related to VQA, and present a set of open problems for future investigation. The work aims to navigate both beginners and experts by shedding light on the potential avenues of research and expanding the boundaries of the field.