 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASHEW: Stabilizing Multimodal Reasoning via Iterative Trajectory Aggregation
Jan 12, 2026Vision-language models achieve strong performance across a wide range of multimodal understanding and reasoning tasks, yet their multi-step reasoning remains unstable. Repeated sampling over the same input often produces divergent reasoning trajectories and inconsistent final predictions. To address this, we introduce two complementary approaches inspired by test-time scaling: (1) CASHEW, an inference-time framework that stabilizes reasoning by iteratively aggregating multiple candidate trajectories into higher-quality reasoning traces, with explicit visual verification filtering hallucinated steps and grounding reasoning in visual evidence, and (2) CASHEW-RL, a learned variant that internalizes this aggregation behavior within a single model. CASHEW-RL is trained using Group Sequence Policy Optimization (GSPO) with a composite reward that encourages correct answers grounded in minimal yet sufficient visual evidence, while adaptively allocating reasoning effort based on task difficulty. This training objective enables robust self-aggregation at inference. Extensive experiments on 13 image understanding, video understanding, and video reasoning benchmarks show significant performance improvements, including gains of up to +23.6 percentage points on ScienceQA and +8.1 percentage points on EgoSchema.
ChitroJera: A Regionally Relevant Visual Question Answering Dataset for Bangla
Oct 19, 2024Visual Question Answer (VQA) poses the problem of answering a natural language question about a visual context. Bangla, despite being a widely spoken language, is considered low-resource in the realm of VQA due to the lack of a proper benchmark dataset. The absence of such datasets challenges models that are known to be performant in other languages. Furthermore, existing Bangla VQA datasets offer little cultural relevance and are largely adapted from their foreign counterparts. To address these challenges, we introduce a large-scale Bangla VQA dataset titled ChitroJera, totaling over 15k samples where diverse and locally relevant data sources are used. We assess the performance of text encoders, image encoders, multimodal models, and our novel dual-encoder models. The experiments reveal that the pre-trained dual-encoders outperform other models of its scale. We also evaluate the performance of large language models (LLMs) using prompt-based techniques, with LLMs achieving the best performance. Given the underdeveloped state of existing datasets, we envision ChitroJera expanding the scope of Vision-Language tasks in Bangla.
BANTH: A Multi-label Hate Speech Detection Dataset for Transliterated Bangla
Oct 17, 2024
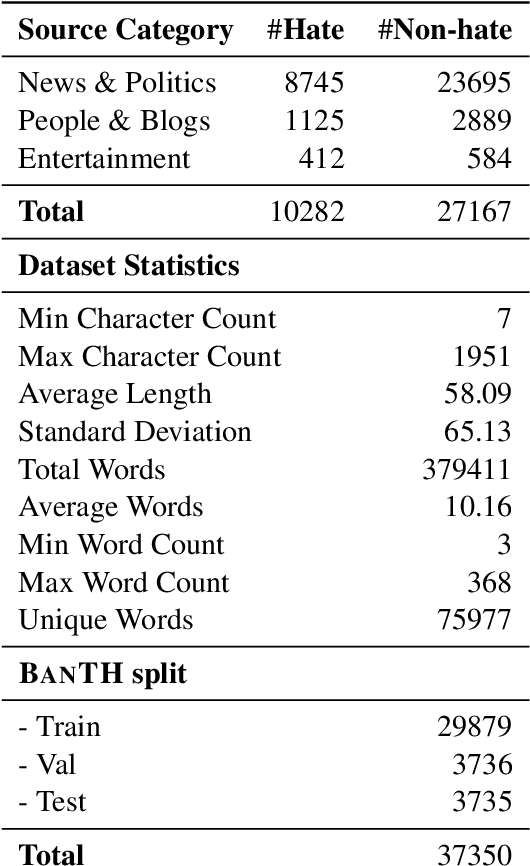

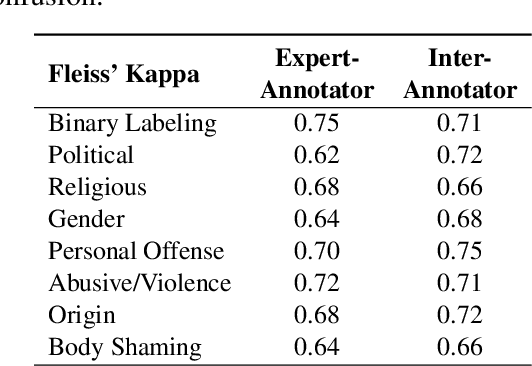
The proliferation of transliterated texts in digital spaces has emphasized the need for detecting and classifying hate speech in languages beyond English, particularly in low-resource languages. As online discourse can perpetuate discrimination based on target groups, e.g. gender, religion, and origin, multi-label classification of hateful content can help in comprehending hate motivation and enhance content moderation. While previous efforts have focused on monolingual or binary hate classification tasks, no work has yet addressed the challenge of multi-label hate speech classification in transliterated Bangla. We introduce BanTH, the first multi-label transliterated Bangla hate speech dataset comprising 37.3k samples. The samples are sourced from YouTube comments, where each instance is labeled with one or more target groups, reflecting the regional demographic. We establish novel transformer encoder-based baselines by further pre-training on transliterated Bangla corpus. We also propose a novel translation-based LLM prompting strategy for transliterated text. Experiments reveal that our further pre-trained encoders are achieving state-of-the-art performance on the BanTH dataset, while our translation-based prompting outperforms other strategies in the zero-shot setting. The introduction of BanTH not only fills a critical gap in hate speech research for Bangla but also sets the stage for future exploration into code-mixed and multi-label classification challenges in underrepresented languages.
Decentralized Cooperation in Heterogeneous Multi-Agent Reinforcement Learning via Graph Neural Network-Based Intrinsic Motivation
Aug 12, 2024



Multi-agent Reinforcement Learning (MARL) is emerging as a key framework for various sequential decision-making and control tasks. Unlike their single-agent counterparts, multi-agent systems necessitate successful cooperation among the agents. The deployment of these systems in real-world scenarios often requires decentralized training, a diverse set of agents, and learning from infrequent environmental reward signals. These challenges become more pronounced under partial observability and the lack of prior knowledge about agent heterogeneity. While notable studies use intrinsic motivation (IM) to address reward sparsity or cooperation in decentralized settings, those dealing with heterogeneity typically assume centralized training, parameter sharing, and agent indexing. To overcome these limitations, we propose the CoHet algorithm, which utilizes a novel Graph Neural Network (GNN) based intrinsic motivation to facilitate the learning of heterogeneous agent policies in decentralized settings, under the challenges of partial observability and reward sparsity. Evaluation of CoHet in the Multi-agent Particle Environment (MPE) and Vectorized Multi-Agent Simulator (VMAS) benchmarks demonstrates superior performance compared to the state-of-the-art in a range of cooperative multi-agent scenarios. Our research is supplemented by an analysis of the impact of the agent dynamics model on the intrinsic motivation module, insights into the performance of different CoHet variants, and its robustness to an increasing number of heterogeneous agents.