 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChitroJera: A Regionally Relevant Visual Question Answering Dataset for Bangla
Oct 19, 2024Visual Question Answer (VQA) poses the problem of answering a natural language question about a visual context. Bangla, despite being a widely spoken language, is considered low-resource in the realm of VQA due to the lack of a proper benchmark dataset. The absence of such datasets challenges models that are known to be performant in other languages. Furthermore, existing Bangla VQA datasets offer little cultural relevance and are largely adapted from their foreign counterparts. To address these challenges, we introduce a large-scale Bangla VQA dataset titled ChitroJera, totaling over 15k samples where diverse and locally relevant data sources are used. We assess the performance of text encoders, image encoders, multimodal models, and our novel dual-encoder models. The experiments reveal that the pre-trained dual-encoders outperform other models of its scale. We also evaluate the performance of large language models (LLMs) using prompt-based techniques, with LLMs achieving the best performance. Given the underdeveloped state of existing datasets, we envision ChitroJera expanding the scope of Vision-Language tasks in Bangla.
BANTH: A Multi-label Hate Speech Detection Dataset for Transliterated Bangla
Oct 17, 2024
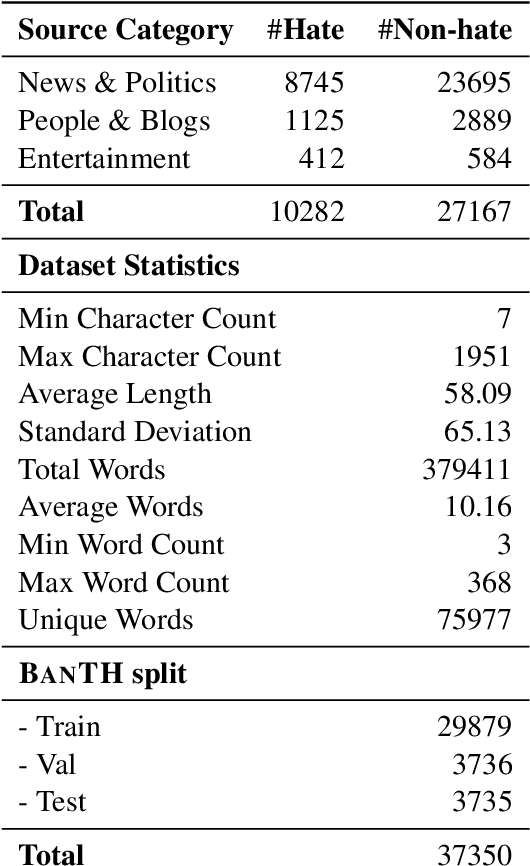

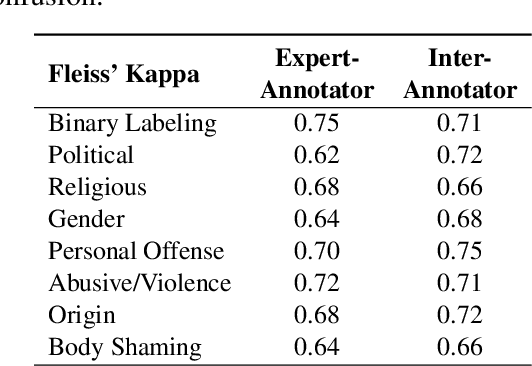
The proliferation of transliterated texts in digital spaces has emphasized the need for detecting and classifying hate speech in languages beyond English, particularly in low-resource languages. As online discourse can perpetuate discrimination based on target groups, e.g. gender, religion, and origin, multi-label classification of hateful content can help in comprehending hate motivation and enhance content moderation. While previous efforts have focused on monolingual or binary hate classification tasks, no work has yet addressed the challenge of multi-label hate speech classification in transliterated Bangla. We introduce BanTH, the first multi-label transliterated Bangla hate speech dataset comprising 37.3k samples. The samples are sourced from YouTube comments, where each instance is labeled with one or more target groups, reflecting the regional demographic. We establish novel transformer encoder-based baselines by further pre-training on transliterated Bangla corpus. We also propose a novel translation-based LLM prompting strategy for transliterated text. Experiments reveal that our further pre-trained encoders are achieving state-of-the-art performance on the BanTH dataset, while our translation-based prompting outperforms other strategies in the zero-shot setting. The introduction of BanTH not only fills a critical gap in hate speech research for Bangla but also sets the stage for future exploration into code-mixed and multi-label classification challenges in underrepresented languages.