 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with LoRA Optimized DeiT and Multiscale Patch Embedding for Secure Eye Disease Recognition
May 11, 2025Recent progress in image-based medical disease detection encounters challenges such as limited annotated data sets, inadequate spatial feature analysis, data security issues, and inefficient training frameworks. This study introduces a data-efficient image transformer (DeIT)-based approach that overcomes these challenges by utilizing multiscale patch embedding for better feature extraction and stratified weighted random sampling to address class imbalance. The model also incorporates a LoRA-enhanced transformer encoder, a distillation framework, and federated learning for decentralized training, improving both efficiency and data security. Consequently, it achieves state-of-the-art performance, with the highest AUC, F1 score, precision, minimal loss, and Top-5 accuracy. Additionally, Grad-CAM++ visualizations improve interpretability by highlighting critical pathological regions, enhancing the model's clinical relevance. These results highlight the potential of this approach to advance AI-powered medical imaging and disease detection.
Replay-Based Continual Learning with Dual-Layered Distillation and a Streamlined U-Net for Efficient Text-to-Image Generation
May 11, 2025Recent advancements in text-to-image diffusion models are hindered by high computational demands, limiting accessibility and scalability. This paper introduces KDC-Diff, a novel stable diffusion framework that enhances efficiency while maintaining image quality. KDC-Diff features a streamlined U-Net architecture with nearly half the parameters of the original U-Net (482M), significantly reducing model complexity. We propose a dual-layered distillation strategy to ensure high-fidelity generation, transferring semantic and structural insights from a teacher to a compact student model while minimizing quality degradation. Additionally, replay-based continual learning is integrated to mitigate catastrophic forgetting, allowing the model to retain prior knowledge while adapting to new data. Despite operating under extremely low computational resources, KDC-Diff achieves state-of-the-art performance on the Oxford Flowers and Butterflies & Moths 100 Species datasets, demonstrating competitive metrics such as FID, CLIP, and LPIPS. Moreover, it significantly reduces inference time compared to existing models. These results establish KDC-Diff as a highly efficient and adaptable solution for text-to-image generation, particularly in computationally constrained environments.
TRABSA: Interpretable Sentiment Analysis of Tweets using Attention-based BiLSTM and Twitter-RoBERTa
Mar 30, 2024Sentiment analysis is crucial for understanding public opinion and consumer behavior. Existing models face challenges with linguistic diversity, generalizability, and explainability. We propose TRABSA, a hybrid framework integrating transformer-based architectures, attention mechanisms, and BiLSTM networks to address this. Leveraging RoBERTa-trained on 124M tweets, we bridge gaps in sentiment analysis benchmarks, ensuring state-of-the-art accuracy. Augmenting datasets with tweets from 32 countries and US states, we compare six word-embedding techniques and three lexicon-based labeling techniques, selecting the best for optimal sentiment analysis. TRABSA outperforms traditional ML and deep learning models with 94% accuracy and significant precision, recall, and F1-score gains. Evaluation across diverse datasets demonstrates consistent superiority and generalizability. SHAP and LIME analyses enhance interpretability, improving confidence in predictions. Our study facilitates pandemic resource management, aiding resource planning, policy formation, and vaccination tactics.
From Image to Language: A Critical Analysis of Visual Question Answering Approaches, Challenges, and Opportunities
Nov 01, 2023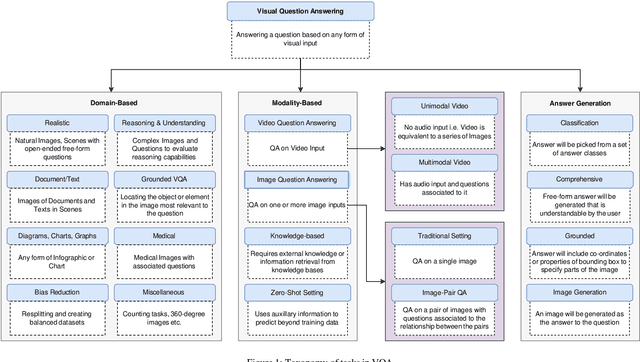
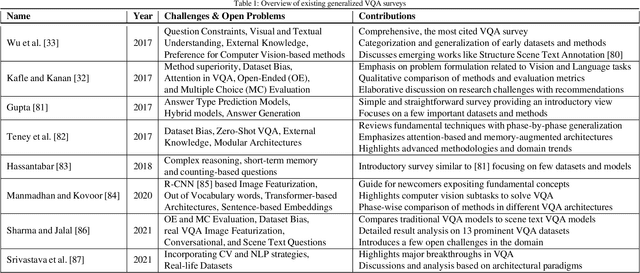
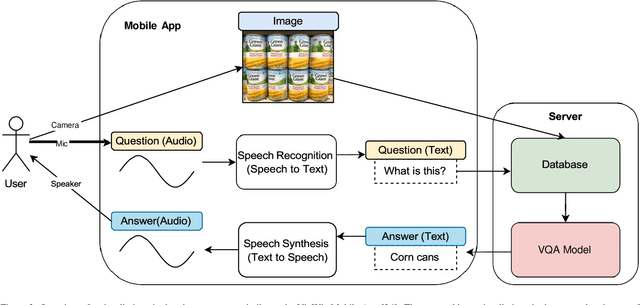
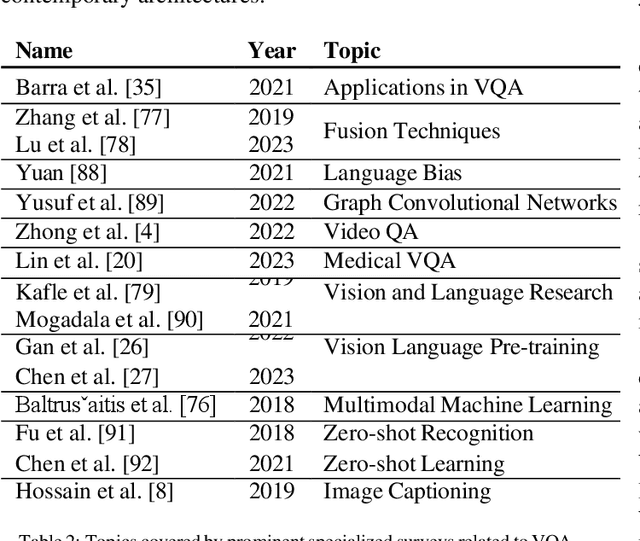
The multimodal task of Visual Question Answering (VQA) encompassing elements of Computer Vision (CV) and Natural Language Processing (NLP), aims to generate answers to questions on any visual input. Over time, the scope of VQA has expanded from datasets focusing on an extensive collection of natural images to datasets featuring synthetic images, video, 3D environments, and various other visual inputs. The emergence of large pre-trained networks has shifted the early VQA approaches relying on feature extraction and fusion schemes to vision language pre-training (VLP) techniques. However, there is a lack of comprehensive surveys that encompass both traditional VQA architectures and contemporary VLP-based methods. Furthermore, the VLP challenges in the lens of VQA haven't been thoroughly explored, leaving room for potential open problems to emerge. Our work presents a survey in the domain of VQA that delves into the intricacies of VQA datasets and methods over the field's history, introduces a detailed taxonomy to categorize the facets of VQA, and highlights the recent trends, challenges, and scopes for improvement. We further generalize VQA to multimodal question answering, explore tasks related to VQA, and present a set of open problems for future investigation. The work aims to navigate both beginners and experts by shedding light on the potential avenues of research and expanding the boundaries of the field.
A Comprehensive Review of AI-enabled Unmanned Aerial Vehicle: Trends, Vision , and Challenges
Oct 25, 2023



In recent years, the combination of artificial intelligence (AI) and unmanned aerial vehicles (UAVs) has brought about advancements in various areas. This comprehensive analysis explores the changing landscape of AI-powered UAVs and friendly computing in their applications. It covers emerging trends, futuristic visions, and the inherent challenges that come with this relationship. The study examines how AI plays a role in enabling navigation, detecting and tracking objects, monitoring wildlife, enhancing precision agriculture, facilitating rescue operations, conducting surveillance activities, and establishing communication among UAVs using environmentally conscious computing techniques. By delving into the interaction between AI and UAVs, this analysis highlights the potential for these technologies to revolutionise industries such as agriculture, surveillance practices, disaster management strategies, and more. While envisioning possibilities, it also takes a look at ethical considerations, safety concerns, regulatory frameworks to be established, and the responsible deployment of AI-enhanced UAV systems. By consolidating insights from research endeavours in this field, this review provides an understanding of the evolving landscape of AI-powered UAVs while setting the stage for further exploration in this transformative domain.
BaitBuster-Bangla: A Comprehensive Dataset for Clickbait Detection in Bangla with Multi-Feature and Multi-Modal Analysis
Oct 13, 2023This study presents a large multi-modal Bangla YouTube clickbait dataset consisting of 253,070 data points collected through an automated process using the YouTube API and Python web automation frameworks. The dataset contains 18 diverse features categorized into metadata, primary content, engagement statistics, and labels for individual videos from 58 Bangla YouTube channels. A rigorous preprocessing step has been applied to denoise, deduplicate, and remove bias from the features, ensuring unbiased and reliable analysis. As the largest and most robust clickbait corpus in Bangla to date, this dataset provides significant value for natural language processing and data science researchers seeking to advance modeling of clickbait phenomena in low-resource languages. Its multi-modal nature allows for comprehensive analyses of clickbait across content, user interactions, and linguistic dimensions to develop more sophisticated detection methods with cross-linguistic applications.
Addressing Uncertainty in Imbalanced Histopathology Image Classification of HER2 Breast Cancer: An interpretable Ensemble Approach with Threshold Filtered Single Instance Evaluation (SIE)
Aug 01, 2023



Breast Cancer (BC) is among women's most lethal health concerns. Early diagnosis can alleviate the mortality rate by helping patients make efficient treatment decisions. Human Epidermal Growth Factor Receptor (HER2) has become one the most lethal subtype of BC. According to the College of American Pathologists/American Society of Clinical Oncology (CAP/ASCO), the severity level of HER2 expression can be classified between 0 and 3+ range. HER2 can be detected effectively from immunohistochemical (IHC) and, hematoxylin \& eosin (HE) images of different classes such as 0, 1+, 2+, and 3+. An ensemble approach integrated with threshold filtered single instance evaluation (SIE) technique has been proposed in this study to diagnose BC from the multi-categorical expression of HER2 subtypes. Initially, DenseNet201 and Xception have been ensembled into a single classifier as feature extractors with an effective combination of global average pooling, dropout layer, dense layer with a swish activation function, and l2 regularizer, batch normalization, etc. After that, extracted features has been processed through single instance evaluation (SIE) to determine different confidence levels and adjust decision boundary among the imbalanced classes. This study has been conducted on the BC immunohistochemical (BCI) dataset, which is classified by pathologists into four stages of HER2 BC. This proposed approach known as DenseNet201-Xception-SIE with a threshold value of 0.7 surpassed all other existing state-of-art models with an accuracy of 97.12\%, precision of 97.15\%, and recall of 97.68\% on H\&E data and, accuracy of 97.56\%, precision of 97.57\%, and recall of 98.00\% on IHC data respectively, maintaining momentous improvement. Finally, Grad-CAM and Guided Grad-CAM have been employed in this study to interpret, how TL-based model works on the histopathology dataset and make decisions from the data.
QAmplifyNet: Pushing the Boundaries of Supply Chain Backorder Prediction Using Interpretable Hybrid Quantum - Classical Neural Network
Jul 24, 2023Supply chain management relies on accurate backorder prediction for optimizing inventory control, reducing costs, and enhancing customer satisfaction. However, traditional machine-learning models struggle with large-scale datasets and complex relationships, hindering real-world data collection. This research introduces a novel methodological framework for supply chain backorder prediction, addressing the challenge of handling large datasets. Our proposed model, QAmplifyNet, employs quantum-inspired techniques within a quantum-classical neural network to predict backorders effectively on short and imbalanced datasets. Experimental evaluations on a benchmark dataset demonstrate QAmplifyNet's superiority over classical models, quantum ensembles, quantum neural networks, and deep reinforcement learning. Its proficiency in handling short, imbalanced datasets makes it an ideal solution for supply chain management. To enhance model interpretability, we use Explainable Artificial Intelligence techniques. Practical implications include improved inventory control, reduced backorders, and enhanced operational efficiency. QAmplifyNet seamlessly integrates into real-world supply chain management systems, enabling proactive decision-making and efficient resource allocation. Future work involves exploring additional quantum-inspired techniques, expanding the dataset, and investigating other supply chain applications. This research unlocks the potential of quantum computing in supply chain optimization and paves the way for further exploration of quantum-inspired machine learning models in supply chain management. Our framework and QAmplifyNet model offer a breakthrough approach to supply chain backorder prediction, providing superior performance and opening new avenues for leveraging quantum-inspired techniques in supply chain management.
Big Data - Supply Chain Management Framework for Forecasting: Data Preprocessing and Machine Learning Techniques
Jul 24, 2023



This article intends to systematically identify and comparatively analyze state-of-the-art supply chain (SC) forecasting strategies and technologies. A novel framework has been proposed incorporating Big Data Analytics in SC Management (problem identification, data sources, exploratory data analysis, machine-learning model training, hyperparameter tuning, performance evaluation, and optimization), forecasting effects on human-workforce, inventory, and overall SC. Initially, the need to collect data according to SC strategy and how to collect them has been discussed. The article discusses the need for different types of forecasting according to the period or SC objective. The SC KPIs and the error-measurement systems have been recommended to optimize the top-performing model. The adverse effects of phantom inventory on forecasting and the dependence of managerial decisions on the SC KPIs for determining model performance parameters and improving operations management, transparency, and planning efficiency have been illustrated. The cyclic connection within the framework introduces preprocessing optimization based on the post-process KPIs, optimizing the overall control process (inventory management, workforce determination, cost, production and capacity planning). The contribution of this research lies in the standard SC process framework proposal, recommended forecasting data analysis, forecasting effects on SC performance, machine learning algorithms optimization followed, and in shedding light on future research.
convoHER2: A Deep Neural Network for Multi-Stage Classification of HER2 Breast Cancer
Nov 19, 2022



Generally, human epidermal growth factor 2 (HER2) breast cancer is more aggressive than other kinds of breast cancer. Currently, HER2 breast cancer is detected using expensive medical tests are most expensive. Therefore, the aim of this study was to develop a computational model named convoHER2 for detecting HER2 breast cancer with image data using convolution neural network (CNN). Hematoxylin and eosin (H&E) and immunohistochemical (IHC) stained images has been used as raw data from the Bayesian information criterion (BIC) benchmark dataset. This dataset consists of 4873 images of H&E and IHC. Among all images of the dataset, 3896 and 977 images are applied to train and test the convoHER2 model, respectively. As all the images are in high resolution, we resize them so that we can feed them in our convoHER2 model. The cancerous samples images are classified into four classes based on the stage of the cancer (0+, 1+, 2+, 3+). The convoHER2 model is able to detect HER2 cancer and its grade with accuracy 85% and 88% using H&E images and IHC images, respectively. The outcomes of this study determined that the HER2 cancer detecting rates of the convoHER2 model are much enough to provide better diagnosis to the patient for recovering their HER2 breast cancer in future.