 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Image to Language: A Critical Analysis of Visual Question Answering Approaches, Challenges, and Opportunities
Paper and Code
Nov 01, 2023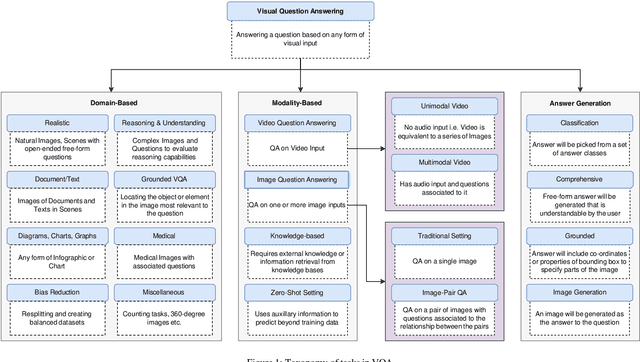
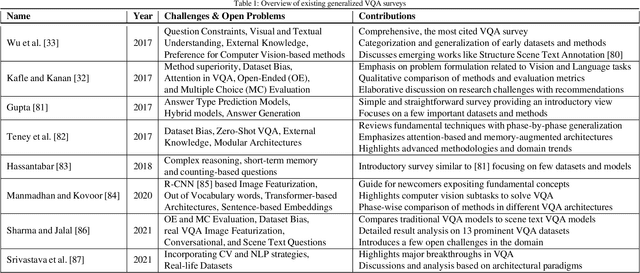
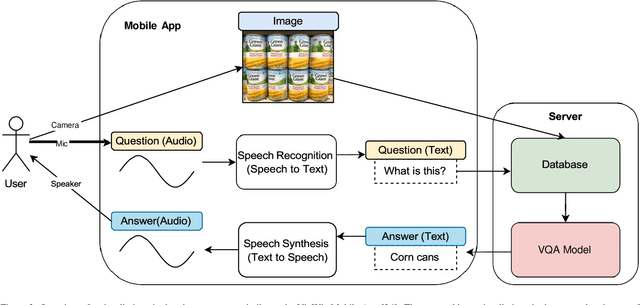
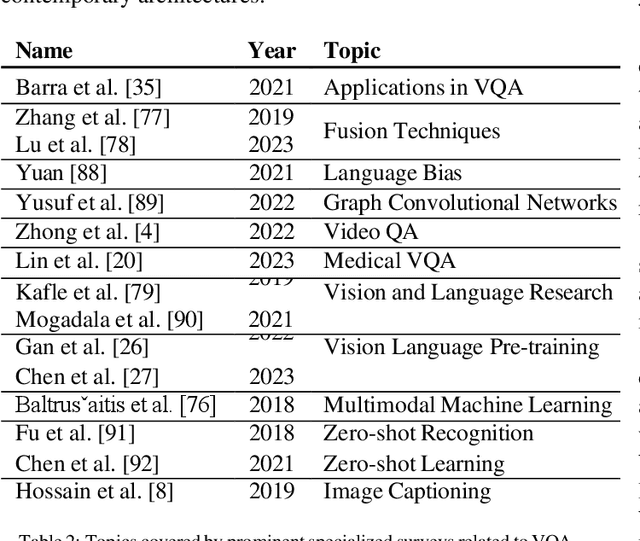
The multimodal task of Visual Question Answering (VQA) encompassing elements of Computer Vision (CV) and Natural Language Processing (NLP), aims to generate answers to questions on any visual input. Over time, the scope of VQA has expanded from datasets focusing on an extensive collection of natural images to datasets featuring synthetic images, video, 3D environments, and various other visual inputs. The emergence of large pre-trained networks has shifted the early VQA approaches relying on feature extraction and fusion schemes to vision language pre-training (VLP) techniques. However, there is a lack of comprehensive surveys that encompass both traditional VQA architectures and contemporary VLP-based methods. Furthermore, the VLP challenges in the lens of VQA haven't been thoroughly explored, leaving room for potential open problems to emerge. Our work presents a survey in the domain of VQA that delves into the intricacies of VQA datasets and methods over the field's history, introduces a detailed taxonomy to categorize the facets of VQA, and highlights the recent trends, challenges, and scopes for improvement. We further generalize VQA to multimodal question answering, explore tasks related to VQA, and present a set of open problems for future investigation. The work aims to navigate both beginners and experts by shedding light on the potential avenues of research and expanding the boundaries of the field.