 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Entity Typing with High-Multiplicity Assignments
Apr 25, 2017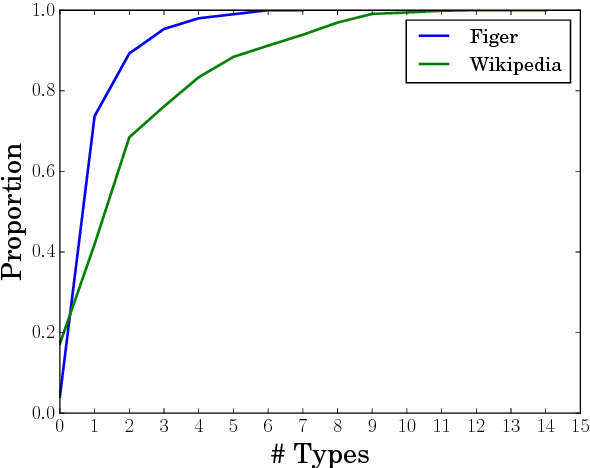


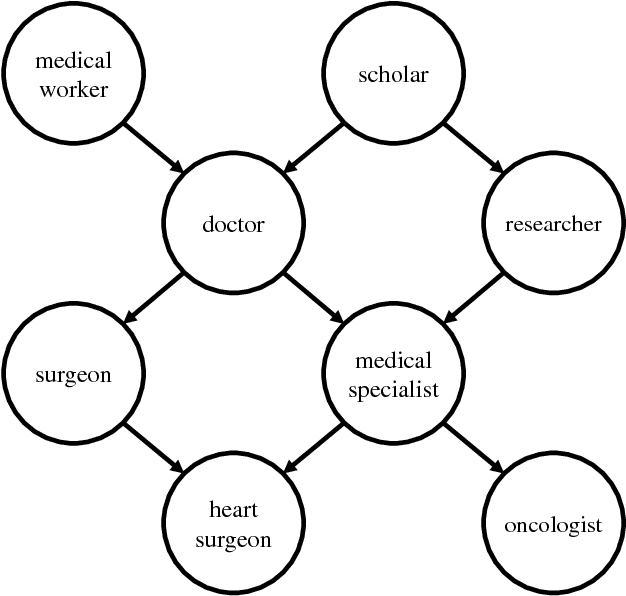
As entity type systems become richer and more fine-grained, we expect the number of types assigned to a given entity to increase. However, most fine-grained typing work has focused on datasets that exhibit a low degree of type multiplicity. In this paper, we consider the high-multiplicity regime inherent in data sources such as Wikipedia that have semi-open type systems. We introduce a set-prediction approach to this problem and show that our model outperforms unstructured baselines on a new Wikipedia-based fine-grained typing corpus.
Abstract Syntax Networks for Code Generation and Semantic Parsing
Apr 25, 2017
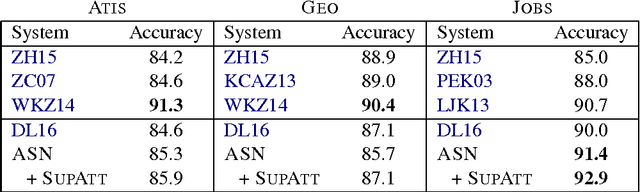

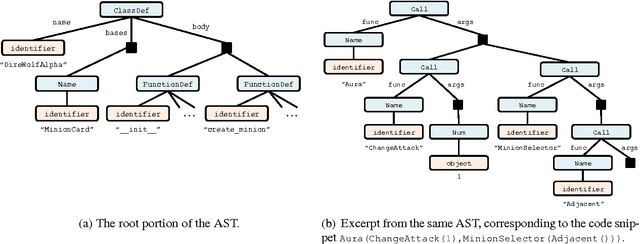
Tasks like code generation and semantic parsing require mapping unstructured (or partially structured) inputs to well-formed, executable outputs. We introduce abstract syntax networks, a modeling framework for these problems. The outputs are represented as abstract syntax trees (ASTs) and constructed by a decoder with a dynamically-determined modular structure paralleling the structure of the output tree. On the benchmark Hearthstone dataset for code generation, our model obtains 79.2 BLEU and 22.7% exact match accuracy, compared to previous state-of-the-art values of 67.1 and 6.1%. Furthermore, we perform competitively on the Atis, Jobs, and Geo semantic parsing datasets with no task-specific engineering.
Function-Specific Mixing Times and Concentration Away from Equilibrium
Sep 30, 2016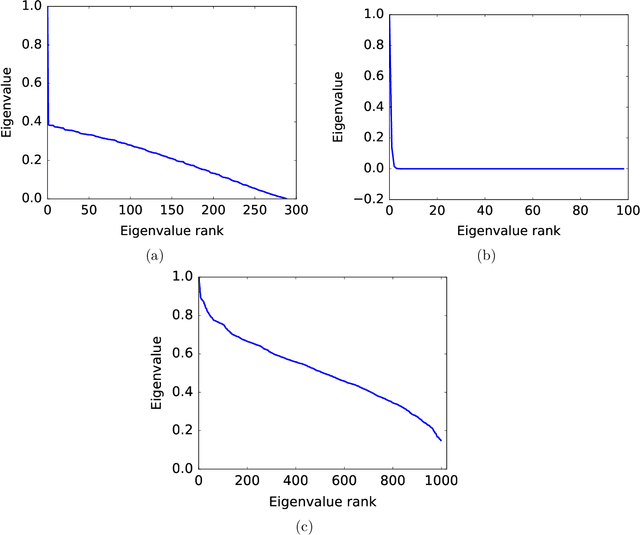
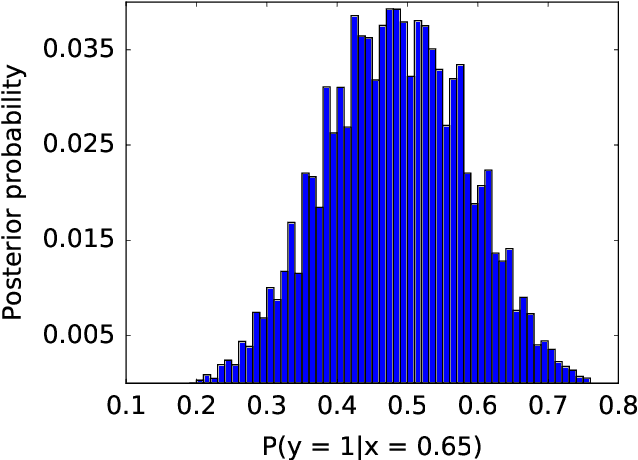
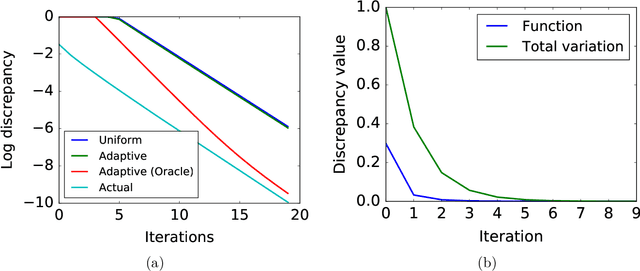
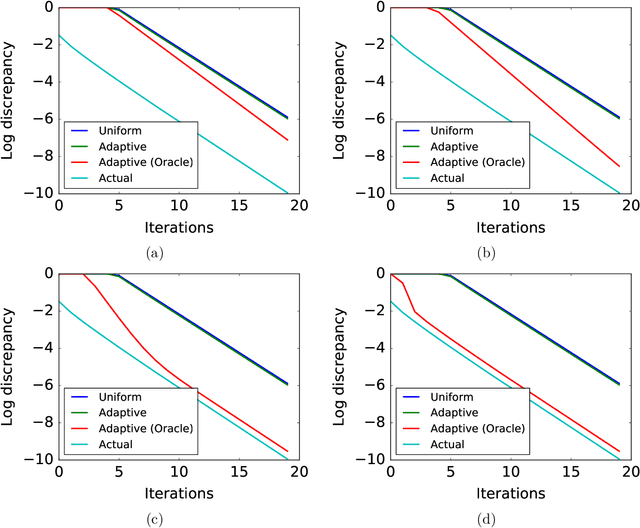
Slow mixing is the central hurdle when working with Markov chains, especially those used for Monte Carlo approximations (MCMC). In many applications, it is only of interest to estimate the stationary expectations of a small set of functions, and so the usual definition of mixing based on total variation convergence may be too conservative. Accordingly, we introduce function-specific analogs of mixing times and spectral gaps, and use them to prove Hoeffding-like function-specific concentration inequalities. These results show that it is possible for empirical expectations of functions to concentrate long before the underlying chain has mixed in the classical sense, and we show that the concentration rates we achieve are optimal up to constants. We use our techniques to derive confidence intervals that are sharper than those implied by both classical Markov chain Hoeffding bounds and Berry-Esseen-corrected CLT bounds. For applications that require testing, rather than point estimation, we show similar improvements over recent sequential testing results for MCMC. We conclude by applying our framework to real data examples of MCMC, providing evidence that our theory is both accurate and relevant to practice.
On the accuracy of self-normalized log-linear models
Jun 18, 2015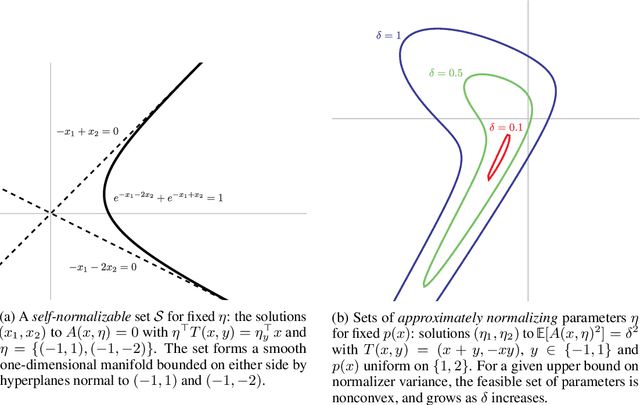
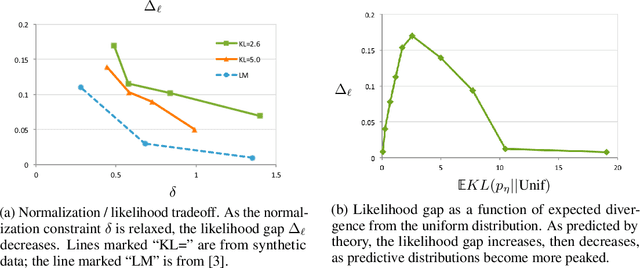
Calculation of the log-normalizer is a major computational obstacle in applications of log-linear models with large output spaces. The problem of fast normalizer computation has therefore attracted significant attention in the theoretical and applied machine learning literature. In this paper, we analyze a recently proposed technique known as "self-normalization", which introduces a regularization term in training to penalize log normalizers for deviating from zero. This makes it possible to use unnormalized model scores as approximate probabilities. Empirical evidence suggests that self-normalization is extremely effective, but a theoretical understanding of why it should work, and how generally it can be applied, is largely lacking. We prove generalization bounds on the estimated variance of normalizers and upper bounds on the loss in accuracy due to self-normalization, describe classes of input distributions that self-normalize easily, and construct explicit examples of high-variance input distributions. Our theoretical results make predictions about the difficulty of fitting self-normalized models to several classes of distributions, and we conclude with empirical validation of these predictions.
Variational consensus Monte Carlo
Jun 09, 2015


Practitioners of Bayesian statistics have long depended on Markov chain Monte Carlo (MCMC) to obtain samples from intractable posterior distributions. Unfortunately, MCMC algorithms are typically serial, and do not scale to the large datasets typical of modern machine learning. The recently proposed consensus Monte Carlo algorithm removes this limitation by partitioning the data and drawing samples conditional on each partition in parallel (Scott et al, 2013). A fixed aggregation function then combines these samples, yielding approximate posterior samples. We introduce variational consensus Monte Carlo (VCMC), a variational Bayes algorithm that optimizes over aggregation functions to obtain samples from a distribution that better approximates the target. The resulting objective contains an intractable entropy term; we therefore derive a relaxation of the objective and show that the relaxed problem is blockwise concave under mild conditions. We illustrate the advantages of our algorithm on three inference tasks from the literature, demonstrating both the superior quality of the posterior approximation and the moderate overhead of the optimization step. Our algorithm achieves a relative error reduction (measured against serial MCMC) of up to 39% compared to consensus Monte Carlo on the task of estimating 300-dimensional probit regression parameter expectations; similarly, it achieves an error reduction of 92% on the task of estimating cluster comembership probabilities in a Gaussian mixture model with 8 components in 8 dimensions. Furthermore, these gains come at moderate cost compared to the runtime of serial MCMC, achieving near-ideal speedup in some instances.
Online Inference for Relation Extraction with a Reduced Feature Set
Apr 18, 2015

Access to web-scale corpora is gradually bringing robust automatic knowledge base creation and extension within reach. To exploit these large unannotated---and extremely difficult to annotate---corpora, unsupervised machine learning methods are required. Probabilistic models of text have recently found some success as such a tool, but scalability remains an obstacle in their application, with standard approaches relying on sampling schemes that are known to be difficult to scale. In this report, we therefore present an empirical assessment of the sublinear time sparse stochastic variational inference (SSVI) scheme applied to RelLDA. We demonstrate that online inference leads to relatively strong qualitative results but also identify some of its pathologies---and those of the model---which will need to be overcome if SSVI is to be used for large-scale relation extraction.