 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2-LoRA: A Synergistic Approach to Differential and Directional Low-Rank Adaptation
Feb 16, 2026We systematically investigate the parameter-efficient fine-tuning design space under practical data and compute constraints, and propose D2-LoRA. D2-LoRA achieves 76.4 percent average accuracy across eight question answering and reading comprehension benchmarks using only 5k training samples per task and two epochs, while preserving algebraic mergeability at inference with near-exact numerical equivalence. The method combines signed low-rank residual updates with additive and subtractive components, together with a train-time column-wise projection that keeps each column close to its original norm. After training, the adapter is merged into a single weight matrix, adding zero inference latency. Compared with LoRA, D2-LoRA improves average accuracy by 2.2 percentage points; at matched parameter counts (LoRA rank 2r versus D2-LoRA rank r), the improvement is 1.6 points, indicating gains from architectural design rather than increased parameterization. Compared with DoRA, it matches or exceeds performance on most tasks. Beyond QA and reading comprehension, D2-LoRA improves generative tasks (plus 1.2 ROUGE-L and plus 1.1 percent win rate) and shows 36 percent lower training volatility. The merge preserves numerical fidelity (mean gap about 0.03 percentage points) and recovers about 1.91x evaluation throughput. Training overhead is 19 percent, comparable to DoRA, and decreases with longer input sequences. We provide a geometric analysis explaining how the projection stabilizes training, together with ablation studies isolating the contribution of each design component.
Quantum Reinforcement Learning with Dynamic-Circuit Qubit Reuse and Grover-Based Trajectory Optimization
Sep 19, 2025



A fully quantum reinforcement learning framework is developed that integrates a quantum Markov decision process, dynamic circuit-based qubit reuse, and Grover's algorithm for trajectory optimization. The framework encodes states, actions, rewards, and transitions entirely within the quantum domain, enabling parallel exploration of state-action sequences through superposition and eliminating classical subroutines. Dynamic circuit operations, including mid-circuit measurement and reset, allow reuse of the same physical qubits across multiple agent-environment interactions, reducing qubit requirements from 7*T to 7 for T time steps while preserving logical continuity. Quantum arithmetic computes trajectory returns, and Grover's search is applied to the superposition of these evaluated trajectories to amplify the probability of measuring those with the highest return, thereby accelerating the identification of the optimal policy. Simulations demonstrate that the dynamic-circuit-based implementation preserves trajectory fidelity while reducing qubit usage by 66 percent relative to the static design. Experimental deployment on IBM Heron-class quantum hardware confirms that the framework operates within the constraints of current quantum processors and validates the feasibility of fully quantum multi-step reinforcement learning under noisy intermediate-scale quantum conditions. This framework advances the scalability and practical application of quantum reinforcement learning for large-scale sequential decision-making tasks.
Quantum framework for Reinforcement Learning: integrating Markov Decision Process, quantum arithmetic, and trajectory search
Dec 24, 2024This paper introduces a quantum framework for addressing reinforcement learning (RL) tasks, grounded in the quantum principles and leveraging a fully quantum model of the classical Markov Decision Process (MDP). By employing quantum concepts and a quantum search algorithm, this work presents the implementation and optimization of the agent-environment interactions entirely within the quantum domain, eliminating reliance on classical computations. Key contributions include the quantum-based state transitions, return calculation, and trajectory search mechanism that utilize quantum principles to demonstrate the realization of RL processes through quantum phenomena. The implementation emphasizes the fundamental role of quantum superposition in enhancing computational efficiency for RL tasks. Experimental results demonstrate the capacity of a quantum model to achieve quantum advantage in RL, highlighting the potential of fully quantum implementations in decision-making tasks. This work not only underscores the applicability of quantum computing in machine learning but also contributes the field of quantum reinforcement learning (QRL) by offering a robust framework for understanding and exploiting quantum computing in RL systems.
Skip2-LoRA: A Lightweight On-device DNN Fine-tuning Method for Low-cost Edge Devices
Oct 28, 2024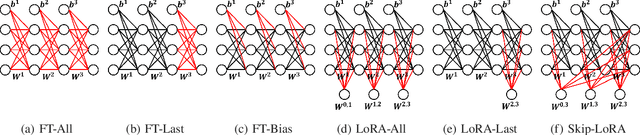

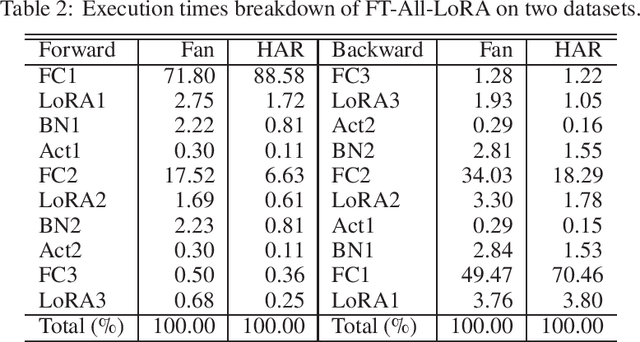

This paper proposes Skip2-LoRA as a lightweight fine-tuning method for deep neural networks to address the gap between pre-trained and deployed models. In our approach, trainable LoRA (low-rank adaptation) adapters are inserted between the last layer and every other layer to enhance the network expressive power while keeping the backward computation cost low. This architecture is well-suited to cache intermediate computation results of the forward pass and then can skip the forward computation of seen samples as training epochs progress. We implemented the combination of the proposed architecture and cache, denoted as Skip2-LoRA, and tested it on a $15 single board computer. Our results show that Skip2-LoRA reduces the fine-tuning time by 90.0% on average compared to the counterpart that has the same number of trainable parameters while preserving the accuracy, while taking only a few seconds on the microcontroller board.
DAISM: Digital Approximate In-SRAM Multiplier-based Accelerator for DNN Training and Inference
May 12, 2023



DNNs are one of the most widely used Deep Learning models. The matrix multiplication operations for DNNs incur significant computational costs and are bottlenecked by data movement between the memory and the processing elements. Many specialized accelerators have been proposed to optimize matrix multiplication operations. One popular idea is to use Processing-in-Memory where computations are performed by the memory storage element, thereby reducing the overhead of data movement between processor and memory. However, most PIM solutions rely either on novel memory technologies that have yet to mature or bit-serial computations which have significant performance overhead and scalability issues. In this work, an in-SRAM digital multiplier is proposed to take the best of both worlds, i.e. performing GEMM in memory but using only conventional SRAMs without the drawbacks of bit-serial computations. This allows the user to design systems with significant performance gains using existing technologies with little to no modifications. We first design a novel approximate bit-parallel multiplier that approximates multiplications with bitwise OR operations by leveraging multiple wordlines activation in the SRAM. We then propose DAISM - Digital Approximate In-SRAM Multiplier architecture, an accelerator for convolutional neural networks, based on our novel multiplier. This is followed by a comprehensive analysis of trade-offs in area, accuracy, and performance. We show that under similar design constraints, DAISM reduces energy consumption by 25\% and the number of cycles by 43\% compared to state-of-the-art baselines.
Quantum Circuit Fidelity Improvement with Long Short-Term Memory Networks
Mar 30, 2023



Quantum computing has entered the Noisy Intermediate-Scale Quantum (NISQ) era. Currently, the quantum processors we have are sensitive to environmental variables like radiation and temperature, thus producing noisy outputs. Although many proposed algorithms and applications exist for NISQ processors, we still face uncertainties when interpreting their noisy results. Specifically, how much confidence do we have in the quantum states we are picking as the output? This confidence is important since a NISQ computer will output a probability distribution of its qubit measurements, and it is sometimes hard to distinguish whether the distribution represents meaningful computation or just random noise. This paper presents a novel approach to attack this problem by framing quantum circuit fidelity prediction as a Time Series Forecasting problem, therefore making it possible to utilize the power of Long Short-Term Memory (LSTM) neural networks. A complete workflow to build the training circuit dataset and LSTM architecture is introduced, including an intuitive method of calculating the quantum circuit fidelity. The trained LSTM system, Q-fid, can predict the output fidelity of a quantum circuit running on a specific processor, without the need for any separate input of hardware calibration data or gate error rates. Evaluated on the QASMbench NISQ benchmark suite, Q-fid's prediction achieves an average RMSE of 0.0515, up to 24.7x more accurate than the default Qiskit transpile tool mapomatic. When used to find the high-fidelity circuit layouts from the available circuit transpilations, Q-fid predicts the fidelity for the top 10% layouts with an average RMSE of 0.0252, up to 32.8x more accurate than mapomatic.
On-Device Learning: A Neural Network Based Field-Trainable Edge AI
Mar 02, 2022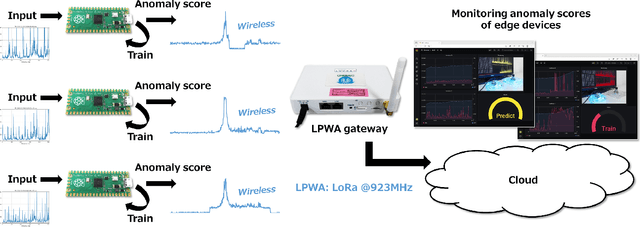
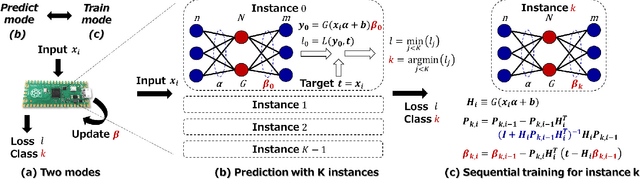
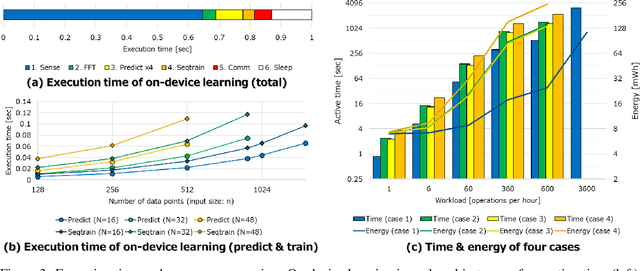
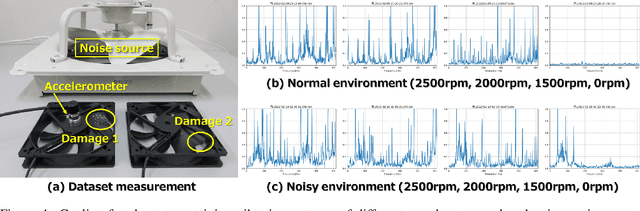
In real-world edge AI applications, their accuracy is often affected by various environmental factors, such as noises, location/calibration of sensors, and time-related changes. This article introduces a neural network based on-device learning approach to address this issue without going deep. Our approach is quite different from de facto backpropagation based training but tailored for low-end edge devices. This article introduces its algorithm and implementation on a wireless sensor node consisting of Raspberry Pi Pico and low-power wireless module. Experiments using vibration patterns of rotating machines demonstrate that retraining by the on-device learning significantly improves an anomaly detection accuracy at a noisy environment while saving computation and communication costs for low power.
A Neural Network Based On-device Learning Anomaly Detector for Edge Devices
Aug 28, 2019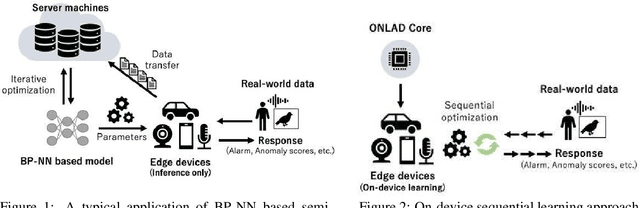
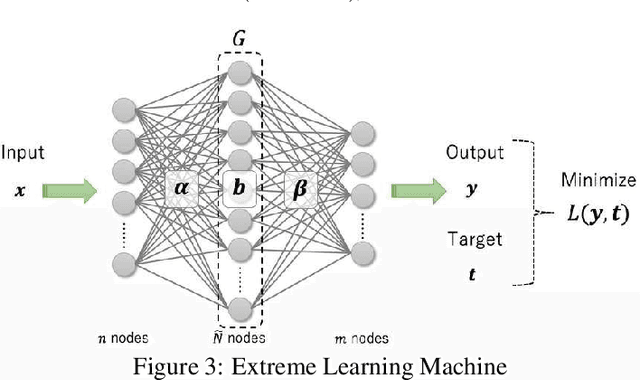

Semi-supervised anomaly detection is referred as an approach to identify rare data instances (i.e, anomalies) on the assumption that all the available training data belong to the majority (i.e., the normal class). A typical strategy is to model the distribution of normal data, then identify data samples far from the distribution as anomalies. Nowadays, backpropagation based neural networks (i.e., BP-NNs) have been drawing attention as well as in the field of semi-supervised anomaly detection because of their high generalization capability for real-world high dimensional data. As a typical application, such BP-NN based models are iteratively optimized in server machines with accumulated data gathered from edge devices. However, there are two issues in this framework: (1) BP-NNs' iterative optimization approach often takes too long time to follow changes of the distribution of normal data (i.e., concept drift), and (2) data transfers between servers and edge devices have a potential risk to cause data breaches. To address these underlying issues, we propose an ON-device sequential Learning semi-supervised Anomaly Detector called ONLAD. The aim of this work is to propose the algorithm, and also to implement it as an IP core called ONLAD Core so that various kinds of edge devices can adopt our approach at low power consumption. Experimental results using open datasets show that ONLAD has favorable anomaly detection capability especially in a testbed which simulates concept drift. Experimental results on hardware performance of the FPGA based ONLAD Core show that its training latency and prediction latency are x1.95 - x4.51 and x2.29 - x4.73 faster than those of BP-NN based software implementations. It is also confirmed that our on-board implementation of ONLAD Core actually works at x6.7 - x27.1 lower power consumption than the other software implementations at a high workload.
Generation High resolution 3D model from natural language by Generative Adversarial Network
Jan 22, 2019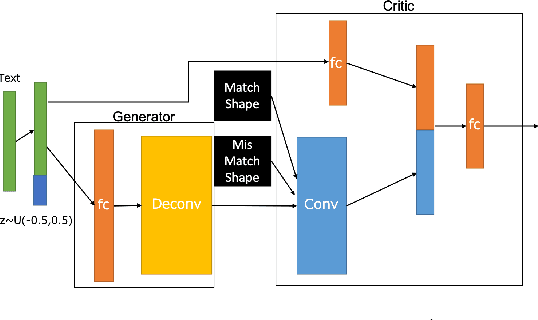
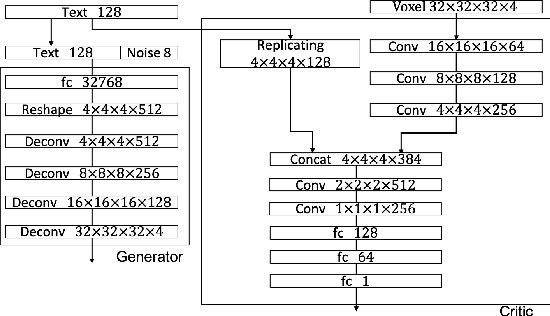
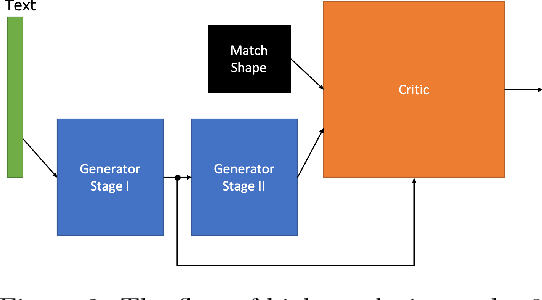
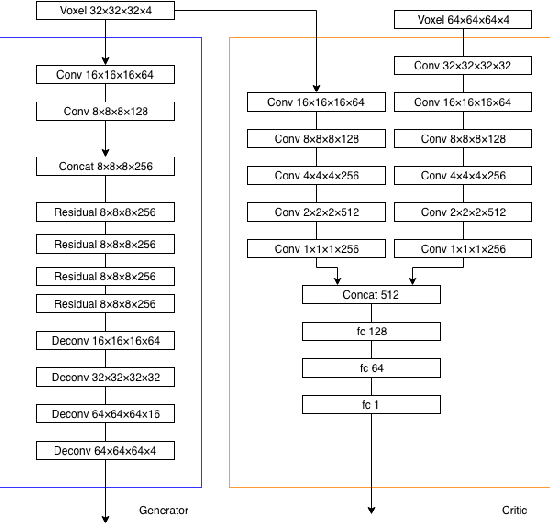
We present a method of generating high resolution 3D shapes from natural language descriptions. To achieve this goal, we propose two steps that generating low resolution shapes which roughly reflect texts and generating high resolution shapes which reflect the detail of texts. In a previous paper, the authors have shown a method of generating low resolution shapes. We improve it to generate 3D shapes more faithful to natural language and test the effectiveness of the method. To generate high resolution 3D shapes, we use the framework of Conditional Wasserstein GAN. We propose two roles of Critic separately, which calculate the Wasserstein distance between two probability distribution, so that we achieve generating high quality shapes or acceleration of learning speed of model. To evaluate our approach, we performed quantitive evaluation with several numerical metrics for Critic models. Our method is first to realize the generation of high quality model by propagating text embedding information to high resolution task when generating 3D model.