 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Local LLMs on Resource-Constrained Edge Devices via Distributed Prompt Caching
Feb 26, 2026Since local LLM inference on resource-constrained edge devices imposes a severe performance bottleneck, this paper proposes distributed prompt caching to enhance inference performance by cooperatively sharing intermediate processing states across multiple low-end edge devices. To fully utilize prompt similarity, our distributed caching mechanism also supports partial matching. As this approach introduces communication overhead associated with state sharing over a wireless network, we introduce a Bloom-filter-based data structure, referred to as a catalog, to determine whether a remote server possesses the desired internal states, thereby suppressing unnecessary communication. Experiments using the Gemma-3 270M model and the MMLU dataset on the Raspberry Pi Zero 2W platform demonstrate that the proposed approach reduces TTFT (Time to First Token) and TTLT (Time to Last Token) by 93.12% and 50.07% on average, respectively.
InstantFT: An FPGA-Based Runtime Subsecond Fine-tuning of CNN Models
Jun 06, 2025Training deep neural networks (DNNs) requires significantly more computation and memory than inference, making runtime adaptation of DNNs challenging on resource-limited IoT platforms. We propose InstantFT, an FPGA-based method for ultra-fast CNN fine-tuning on IoT devices, by optimizing the forward and backward computations in parameter-efficient fine-tuning (PEFT). Experiments on datasets with concept drift demonstrate that InstantFT fine-tunes a pre-trained CNN 17.4x faster than existing Low-Rank Adaptation (LoRA)-based approaches, while achieving comparable accuracy. Our FPGA-based InstantFT reduces the fine-tuning time to just 0.36s and improves energy-efficiency by 16.3x, enabling on-the-fly adaptation of CNNs to non-stationary data distributions.
ElasticZO: A Memory-Efficient On-Device Learning with Combined Zeroth- and First-Order Optimization
Jan 08, 2025Zeroth-order (ZO) optimization is being recognized as a simple yet powerful alternative to standard backpropagation (BP)-based training. Notably, ZO optimization allows for training with only forward passes and (almost) the same memory as inference, making it well-suited for edge devices with limited computing and memory resources. In this paper, we propose ZO-based on-device learning (ODL) methods for full-precision and 8-bit quantized deep neural networks (DNNs), namely ElasticZO and ElasticZO-INT8. ElasticZO lies in the middle between pure ZO- and pure BP-based approaches, and is based on the idea to employ BP for the last few layers and ZO for the remaining layers. ElasticZO-INT8 achieves integer arithmetic-only ZO-based training for the first time, by incorporating a novel method for computing quantized ZO gradients from integer cross-entropy loss values. Experimental results on the classification datasets show that ElasticZO effectively addresses the slow convergence of vanilla ZO and shrinks the accuracy gap to BP-based training. Compared to vanilla ZO, ElasticZO achieves 5.2-9.5% higher accuracy with only 0.072-1.7% memory overhead, and can handle fine-tuning tasks as well as full training. ElasticZO-INT8 further reduces the memory usage and training time by 1.46-1.60x and 1.38-1.42x without compromising the accuracy. These results demonstrate a better tradeoff between accuracy and training cost compared to pure ZO- and BP-based approaches, and also highlight the potential of ZO optimization in on-device learning.
Skip2-LoRA: A Lightweight On-device DNN Fine-tuning Method for Low-cost Edge Devices
Oct 28, 2024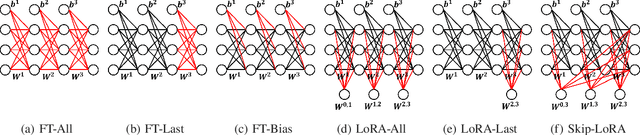

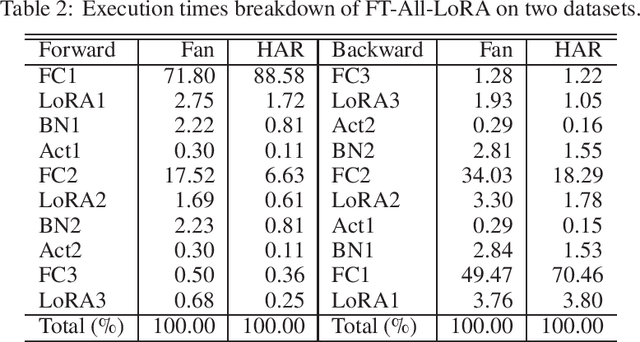

This paper proposes Skip2-LoRA as a lightweight fine-tuning method for deep neural networks to address the gap between pre-trained and deployed models. In our approach, trainable LoRA (low-rank adaptation) adapters are inserted between the last layer and every other layer to enhance the network expressive power while keeping the backward computation cost low. This architecture is well-suited to cache intermediate computation results of the forward pass and then can skip the forward computation of seen samples as training epochs progress. We implemented the combination of the proposed architecture and cache, denoted as Skip2-LoRA, and tested it on a $15 single board computer. Our results show that Skip2-LoRA reduces the fine-tuning time by 90.0% on average compared to the counterpart that has the same number of trainable parameters while preserving the accuracy, while taking only a few seconds on the microcontroller board.
A Tiny Supervised ODL Core with Auto Data Pruning for Human Activity Recognition
Aug 02, 2024



In this paper, we introduce a low-cost and low-power tiny supervised on-device learning (ODL) core that can address the distributional shift of input data for human activity recognition. Although ODL for resource-limited edge devices has been studied recently, how exactly to provide the training labels to these devices at runtime remains an open-issue. To address this problem, we propose to combine an automatic data pruning with supervised ODL to reduce the number queries needed to acquire predicted labels from a nearby teacher device and thus save power consumption during model retraining. The data pruning threshold is automatically tuned, eliminating a manual threshold tuning. As a tinyML solution at a few mW for the human activity recognition, we design a supervised ODL core that supports our automatic data pruning using a 45nm CMOS process technology. We show that the required memory size for the core is smaller than the same-shaped multilayer perceptron (MLP) and the power consumption is only 3.39mW. Experiments using a human activity recognition dataset show that the proposed automatic data pruning reduces the communication volume by 55.7% and power consumption accordingly with only 0.9% accuracy loss.
FPGA-Accelerated Correspondence-free Point Cloud Registration with PointNet Features
Apr 01, 2024



Point cloud registration serves as a basis for vision and robotic applications including 3D reconstruction and mapping. Despite significant improvements on the quality of results, recent deep learning approaches are computationally expensive and power-hungry, making them difficult to deploy on resource-constrained edge devices. To tackle this problem, in this paper, we propose a fast, accurate, and robust registration for low-cost embedded FPGAs. Based on a parallel and pipelined PointNet feature extractor, we develop custom accelerator cores namely PointLKCore and ReAgentCore, for two different learning-based methods. They are both correspondence-free and computationally efficient as they avoid the costly feature matching step involving nearest-neighbor search. The proposed cores are implemented on the Xilinx ZCU104 board and evaluated using both synthetic and real-world datasets, showing the substantial improvements in the trade-offs between runtime and registration quality. They run 44.08-45.75x faster than ARM Cortex-A53 CPU and offer 1.98-11.13x speedups over Intel Xeon CPU and Nvidia Jetson boards, while consuming less than 1W and achieving 163.11-213.58x energy-efficiency compared to Nvidia GeForce GPU. The proposed cores are more robust to noise and large initial misalignments than the classical methods and quickly find reasonable solutions in less than 15ms, demonstrating the real-time performance.
A Cost-Efficient FPGA Implementation of Tiny Transformer Model using Neural ODE
Jan 05, 2024Transformer is an emerging neural network model with attention mechanism. It has been adopted to various tasks and achieved a favorable accuracy compared to CNNs and RNNs. While the attention mechanism is recognized as a general-purpose component, many of the Transformer models require a significant number of parameters compared to the CNN-based ones. To mitigate the computational complexity, recently, a hybrid approach has been proposed, which uses ResNet as a backbone architecture and replaces a part of its convolution layers with an MHSA (Multi-Head Self-Attention) mechanism. In this paper, we significantly reduce the parameter size of such models by using Neural ODE (Ordinary Differential Equation) as a backbone architecture instead of ResNet. The proposed hybrid model reduces the parameter size by 94.6% compared to the CNN-based ones without degrading the accuracy. We then deploy the proposed model on a modest-sized FPGA device for edge computing. To further reduce FPGA resource utilization, we quantize the model following QAT (Quantization Aware Training) scheme instead of PTQ (Post Training Quantization) to suppress the accuracy loss. As a result, an extremely lightweight Transformer-based model can be implemented on resource-limited FPGAs. The weights of the feature extraction network are stored on-chip to minimize the memory transfer overhead, allowing faster inference. By eliminating the overhead of memory transfers, inference can be executed seamlessly, leading to accelerated inference. The proposed FPGA implementation achieves 12.8x speedup and 9.21x energy efficiency compared to ARM Cortex-A53 CPU.
An FPGA-Based Accelerator for Graph Embedding using Sequential Training Algorithm
Dec 23, 2023A graph embedding is an emerging approach that can represent a graph structure with a fixed-length low-dimensional vector. node2vec is a well-known algorithm to obtain such a graph embedding by sampling neighboring nodes on a given graph with a random walk technique. However, the original node2vec algorithm typically relies on a batch training of graph structures; thus, it is not suited for applications in which the graph structure changes after the deployment. In this paper, we focus on node2vec applications for IoT (Internet of Things) environments. To handle the changes of graph structures after the IoT devices have been deployed in edge environments, in this paper we propose to combine an online sequential training algorithm with node2vec. The proposed sequentially-trainable model is implemented on a resource-limited FPGA (Field-Programmable Gate Array) device to demonstrate the benefits of our approach. The proposed FPGA implementation achieves up to 205.25 times speedup compared to the original model on CPU. Evaluation results using dynamic graphs show that although the original model decreases the accuracy, the proposed sequential model can obtain better graph embedding that can increase the accuracy even when the graph structure is changed.
An Integrated FPGA Accelerator for Deep Learning-based 2D/3D Path Planning
Jun 30, 2023



Path planning is a crucial component for realizing the autonomy of mobile robots. However, due to limited computational resources on mobile robots, it remains challenging to deploy state-of-the-art methods and achieve real-time performance. To address this, we propose P3Net (PointNet-based Path Planning Networks), a lightweight deep-learning-based method for 2D/3D path planning, and design an IP core (P3NetCore) targeting FPGA SoCs (Xilinx ZCU104). P3Net improves the algorithm and model architecture of the recently-proposed MPNet. P3Net employs an encoder with a PointNet backbone and a lightweight planning network in order to extract robust point cloud features and sample path points from a promising region. P3NetCore is comprised of the fully-pipelined point cloud encoder, batched bidirectional path planner, and parallel collision checker, to cover most part of the algorithm. On the 2D (3D) datasets, P3Net with the IP core runs 24.54-149.57x and 6.19-115.25x (10.03-59.47x and 3.38-28.76x) faster than ARM Cortex CPU and Nvidia Jetson while only consuming 0.255W (0.809W), and is up to 1049.42x (133.84x) power-efficient than the workstation. P3Net improves the success rate by up to 28.2% and plans a near-optimal path, leading to a significantly better tradeoff between computation and solution quality than MPNet and the state-of-the-art sampling-based methods.
A Sequential Concept Drift Detection Method for On-Device Learning on Low-End Edge Devices
Dec 19, 2022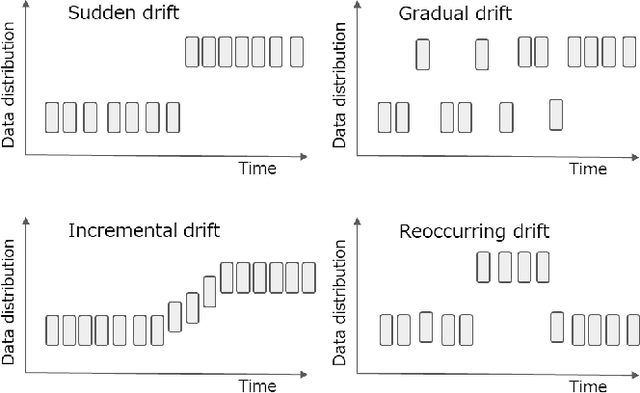

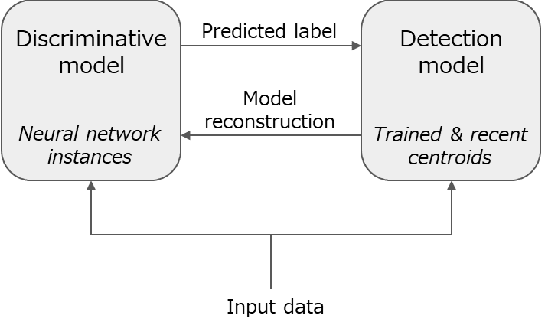
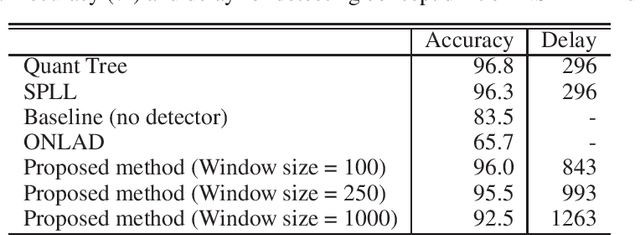
A practical issue of edge AI systems is that data distributions of trained dataset and deployed environment may differ due to noise and environmental changes over time. Such a phenomenon is known as a concept drift, and this gap degrades the performance of edge AI systems and may introduce system failures. To address this gap, a retraining of neural network models triggered by concept drift detection is a practical approach. However, since available compute resources are strictly limited in edge devices, in this paper we propose a lightweight concept drift detection method in cooperation with a recently proposed on-device learning technique of neural networks. In this case, both the neural network retraining and the proposed concept drift detection are done by sequential computation only to reduce computation cost and memory utilization. Evaluation results of the proposed approach shows that while the accuracy is decreased by 3.8%-4.3% compared to existing batch-based detection methods, it decreases the memory size by 88.9%-96.4% and the execution time by 1.3%-83.8%. As a result, the combination of the neural network retraining and the proposed concept drift detection method is demonstrated on Raspberry Pi Pico that has 264kB memory.