 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Size Reduction of Federated Learning based on Neural ODE Model
Aug 19, 2022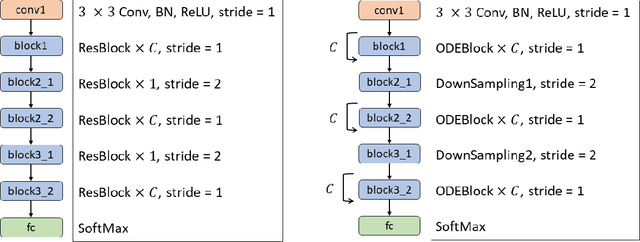
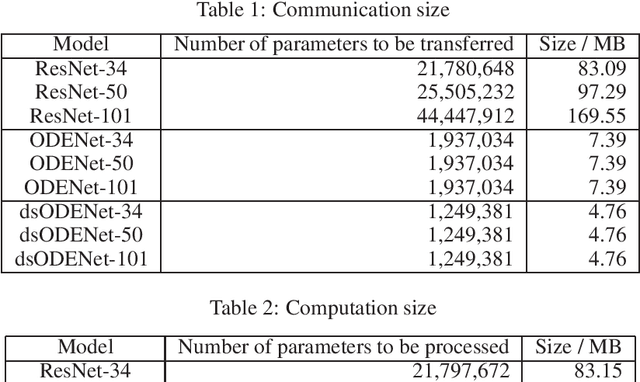
Federated learning is a machine learning method in which data is not aggregated on a server, but is distributed to the edges, in consideration of security and privacy. ResNet is a classic but representative neural network that succeeds in deepening the neural network by learning a residual function that adds the inputs and outputs together. In federated learning, communication is performed between the server and edge devices to exchange weight parameters, but ResNet has deep layers and a large number of parameters, so communication size becomes large. In this paper, we use Neural ODE as a lightweight model of ResNet to reduce communication size in federated learning. In addition, we newly introduce a flexible federated learning using Neural ODE models with different number of iterations, which correspond to ResNet with different depths. The CIFAR-10 dataset is used in the evaluation, and the use of Neural ODE reduces communication size by approximately 90% compared to ResNet. We also show that the proposed flexible federated learning can merge models with different iteration counts.
A Low-Cost Neural ODE with Depthwise Separable Convolution for Edge Domain Adaptation on FPGAs
Jul 27, 2021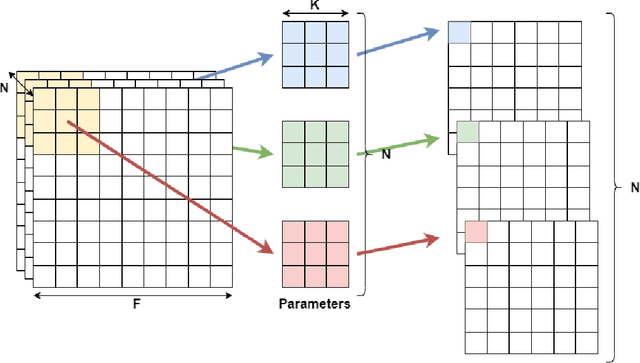

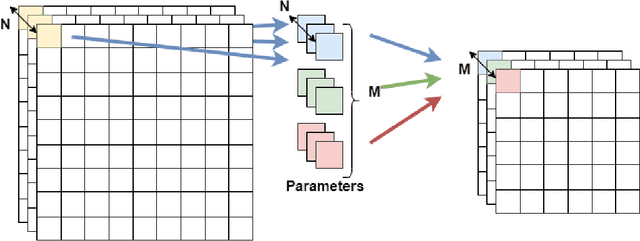
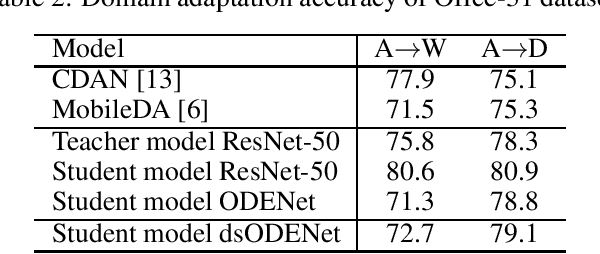
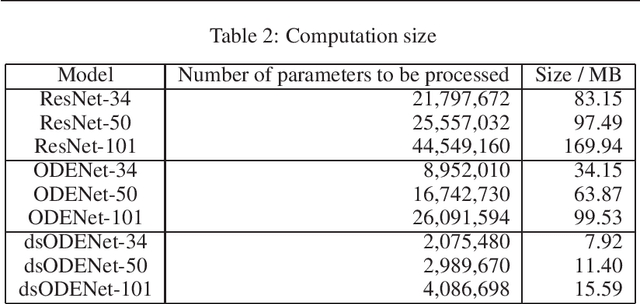
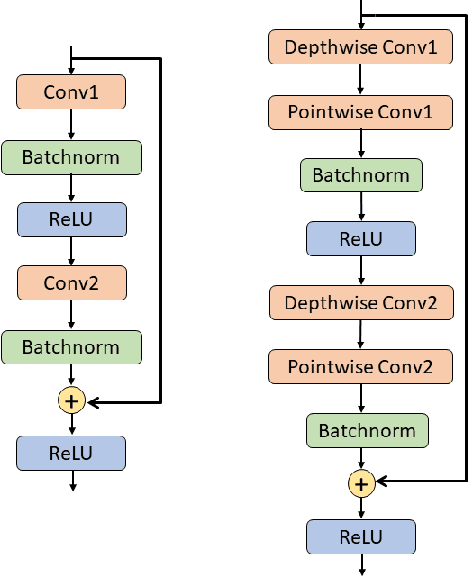
Although high-performance deep neural networks are in high demand in edge environments, computation resources are strictly limited in edge devices, and light-weight neural network techniques, such as Depthwise Separable Convolution (DSC), have been developed. ResNet is one of conventional deep neural network models that stack a lot of layers and parameters for a higher accuracy. To reduce the parameter size of ResNet, by utilizing a similarity to ODE (Ordinary Differential Equation), Neural ODE repeatedly uses most of weight parameters instead of having a lot of different parameters. Thus, Neural ODE becomes significantly small compared to that of ResNet so that it can be implemented in resource-limited edge devices. In this paper, a combination of Neural ODE and DSC, called dsODENet, is designed and implemented for FPGAs (Field-Programmable Gate Arrays). dsODENet is then applied to edge domain adaptation as a practical use case and evaluated with image classification datasets. It is implemented on Xilinx ZCU104 board and evaluated in terms of domain adaptation accuracy, training speed, FPGA resource utilization, and speedup rate compared to a software execution. The results demonstrate that dsODENet is comparable to or slightly better than our baseline Neural ODE implementation in terms of domain adaptation accuracy, while the total parameter size without pre- and post-processing layers is reduced by 54.2% to 79.8%. The FPGA implementation accelerates the prediction tasks by 27.9 times faster than a software implementation.