 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Low-Cost Neural ODE with Depthwise Separable Convolution for Edge Domain Adaptation on FPGAs
Jul 27, 2021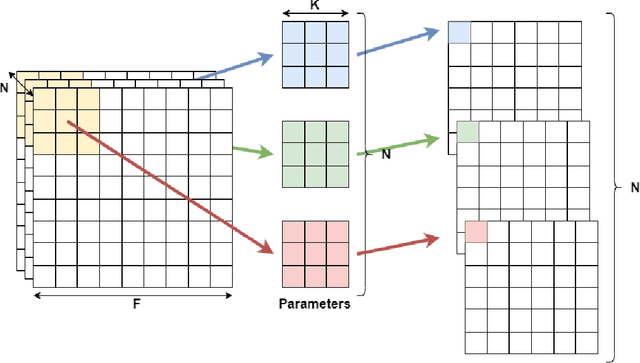

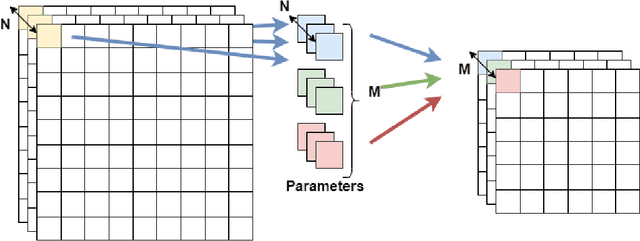
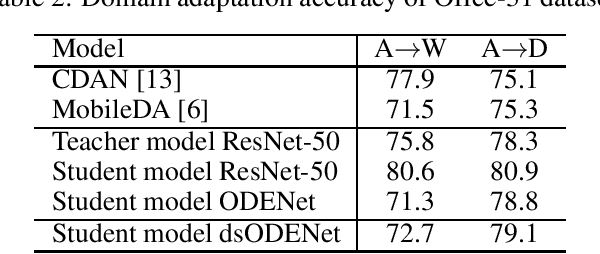
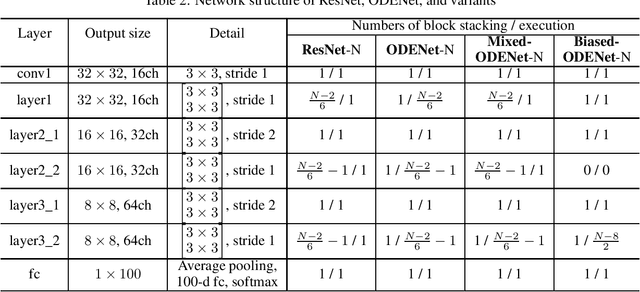
Although high-performance deep neural networks are in high demand in edge environments, computation resources are strictly limited in edge devices, and light-weight neural network techniques, such as Depthwise Separable Convolution (DSC), have been developed. ResNet is one of conventional deep neural network models that stack a lot of layers and parameters for a higher accuracy. To reduce the parameter size of ResNet, by utilizing a similarity to ODE (Ordinary Differential Equation), Neural ODE repeatedly uses most of weight parameters instead of having a lot of different parameters. Thus, Neural ODE becomes significantly small compared to that of ResNet so that it can be implemented in resource-limited edge devices. In this paper, a combination of Neural ODE and DSC, called dsODENet, is designed and implemented for FPGAs (Field-Programmable Gate Arrays). dsODENet is then applied to edge domain adaptation as a practical use case and evaluated with image classification datasets. It is implemented on Xilinx ZCU104 board and evaluated in terms of domain adaptation accuracy, training speed, FPGA resource utilization, and speedup rate compared to a software execution. The results demonstrate that dsODENet is comparable to or slightly better than our baseline Neural ODE implementation in terms of domain adaptation accuracy, while the total parameter size without pre- and post-processing layers is reduced by 54.2% to 79.8%. The FPGA implementation accelerates the prediction tasks by 27.9 times faster than a software implementation.
Accelerating ODE-Based Neural Networks on Low-Cost FPGAs
Jan 03, 2021

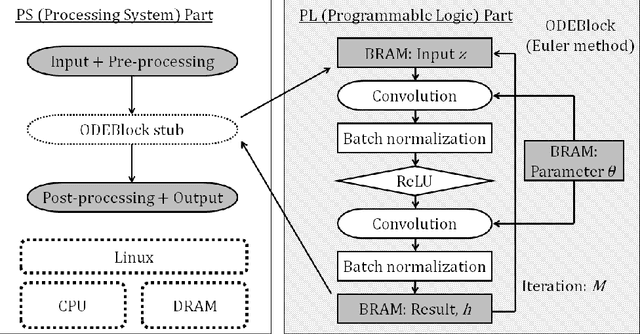
ODENet is a deep neural network architecture in which a stacking structure of ResNet is implemented with an ordinary differential equation (ODE) solver. It can reduce the number of parameters and strike a balance between accuracy and performance by selecting a proper solver. It is also possible to improve the accuracy while keeping the same number of parameters on resource-limited edge devices. In this paper, using Euler method as an ODE solver, a part of ODENet is implemented as a dedicated logic on a low-cost FPGA (Field-Programmable Gate Array) board, such as PYNQ-Z2 board. Two variants, one for high accuracy and the other for performance, are proposed and implemented on the FPGA board as well. They are evaluated in terms of parameter size, accuracy, execution time, and resource utilization on the FPGA. The results show that an overall execution time of ODENet and its variants is improved by up to 2.50 times compared to a pure software execution when a part of convolution layers is executed by the programmable logic.
An FPGA-Based On-Device Reinforcement Learning Approach using Online Sequential Learning
May 10, 2020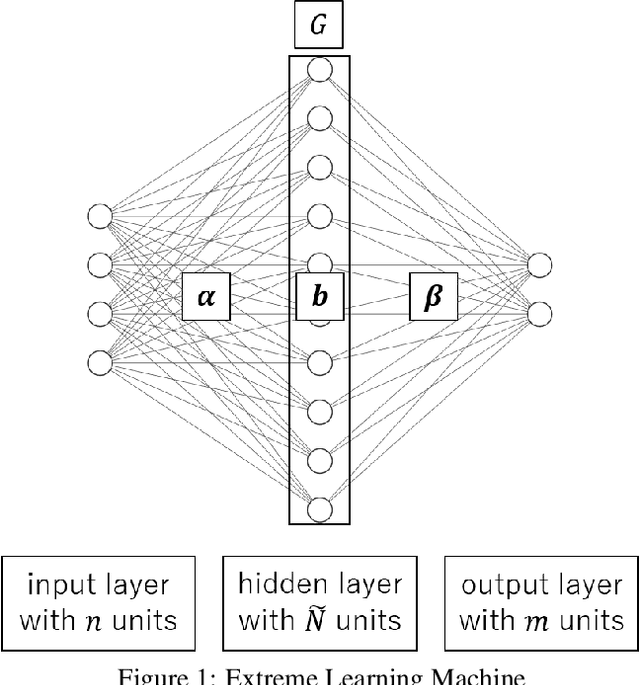

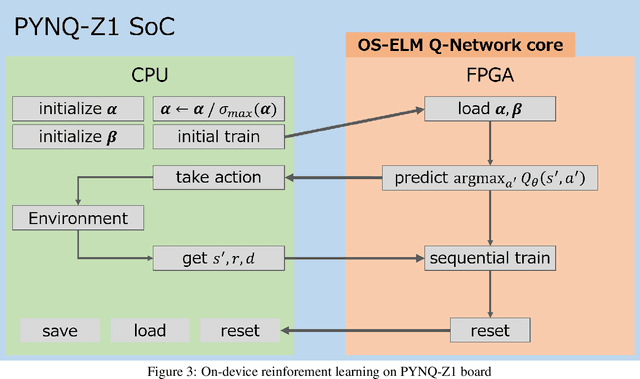
DQN (Deep Q-Network) is a method to perform Q-learning for reinforcement learning using deep neural networks. DQNs require large buffers for experience reply and rely on backpropagation based iterative optimization, making them difficult to be implemented on resource-limited edge devices. In this paper, we propose a lightweight on-device reinforcement learning approach for low-cost FPGA devices. It exploits a recently proposed neural-network based on-device learning approach that does not rely on the backpropagation method but uses ELM (Extreme Learning Machine) and OS-ELM (Online Sequential ELM) based training algorithms. In addition, we propose a combination of L2 regularization and spectral normalization for the on-device reinforcement learning, so that output values of the neural networks can be fit into a certain range and the reinforcement learning becomes stable. The proposed reinforcement learning approach is designed for Xilinx PYNQ-Z1 board as a low-cost FPGA platform. The experiment results using OpenAI Gym demonstrate that the proposed algorithm and its FPGA implementation complete a CartPole-v0 task 29.76x and 126.06x faster than a conventional DQN-based approach when the number of hidden-layer nodes is 64.