 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Learning: A Neural Network Based Field-Trainable Edge AI
Mar 02, 2022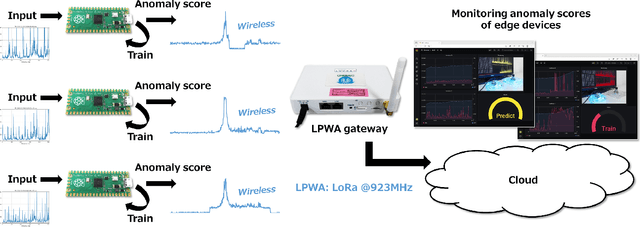
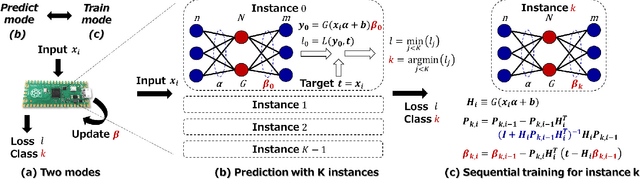
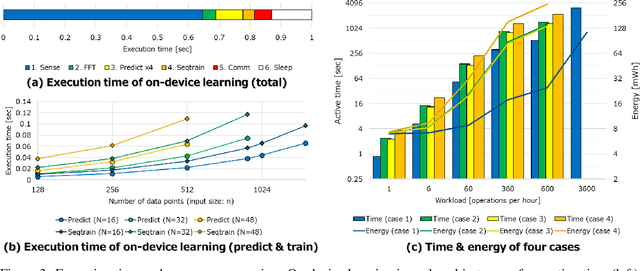
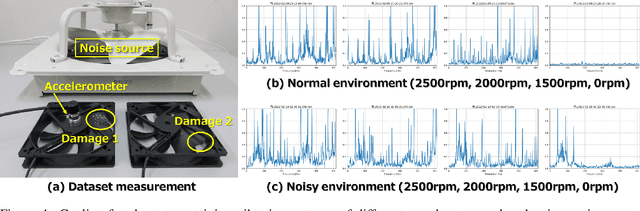
In real-world edge AI applications, their accuracy is often affected by various environmental factors, such as noises, location/calibration of sensors, and time-related changes. This article introduces a neural network based on-device learning approach to address this issue without going deep. Our approach is quite different from de facto backpropagation based training but tailored for low-end edge devices. This article introduces its algorithm and implementation on a wireless sensor node consisting of Raspberry Pi Pico and low-power wireless module. Experiments using vibration patterns of rotating machines demonstrate that retraining by the on-device learning significantly improves an anomaly detection accuracy at a noisy environment while saving computation and communication costs for low power.
An Overflow/Underflow-Free Fixed-Point Bit-Width Optimization Method for OS-ELM Digital Circuit
Mar 17, 2021



Currently there has been increasing demand for real-time training on resource-limited IoT devices such as smart sensors, which realizes standalone online adaptation for streaming data without data transfers to remote servers. OS-ELM (Online Sequential Extreme Learning Machine) has been one of promising neural-network-based online algorithms for on-chip learning because it can perform online training at low computational cost and is easy to implement as a digital circuit. Existing OS-ELM digital circuits employ fixed-point data format and the bit-widths are often manually tuned, however, this may cause overflow or underflow which can lead to unexpected behavior of the circuit. For on-chip learning systems, an overflow/underflow-free design has a great impact since online training is continuously performed and the intervals of intermediate variables will dynamically change as time goes by. In this paper, we propose an overflow/underflow-free bit-width optimization method for fixed-point digital circuit of OS-ELM. Experimental results show that our method realizes overflow/underflow-free OS-ELM digital circuits with 1.0x - 1.5x more area cost compared to an ordinary simulation-based optimization method where overflow or underflow can happen.
An FPGA-Based On-Device Reinforcement Learning Approach using Online Sequential Learning
May 10, 2020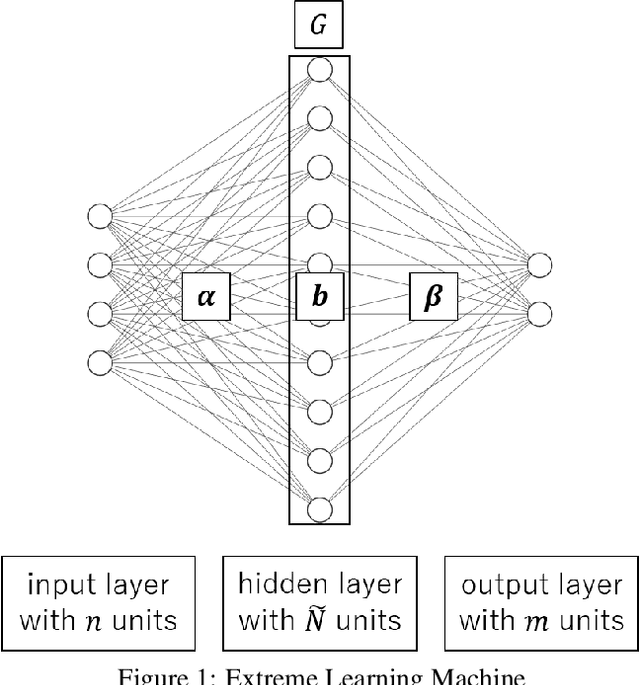

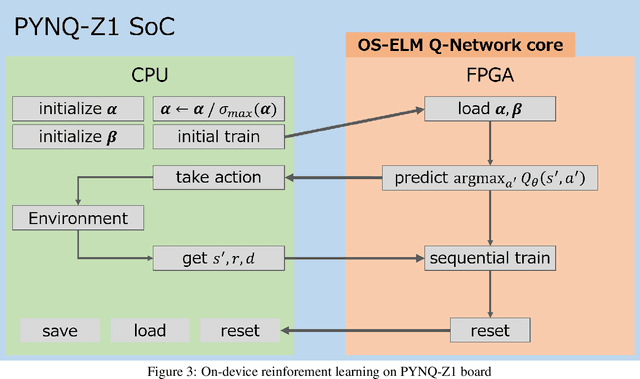
DQN (Deep Q-Network) is a method to perform Q-learning for reinforcement learning using deep neural networks. DQNs require large buffers for experience reply and rely on backpropagation based iterative optimization, making them difficult to be implemented on resource-limited edge devices. In this paper, we propose a lightweight on-device reinforcement learning approach for low-cost FPGA devices. It exploits a recently proposed neural-network based on-device learning approach that does not rely on the backpropagation method but uses ELM (Extreme Learning Machine) and OS-ELM (Online Sequential ELM) based training algorithms. In addition, we propose a combination of L2 regularization and spectral normalization for the on-device reinforcement learning, so that output values of the neural networks can be fit into a certain range and the reinforcement learning becomes stable. The proposed reinforcement learning approach is designed for Xilinx PYNQ-Z1 board as a low-cost FPGA platform. The experiment results using OpenAI Gym demonstrate that the proposed algorithm and its FPGA implementation complete a CartPole-v0 task 29.76x and 126.06x faster than a conventional DQN-based approach when the number of hidden-layer nodes is 64.
An On-Device Federated Learning Approach for Cooperative Anomaly Detection
Feb 27, 2020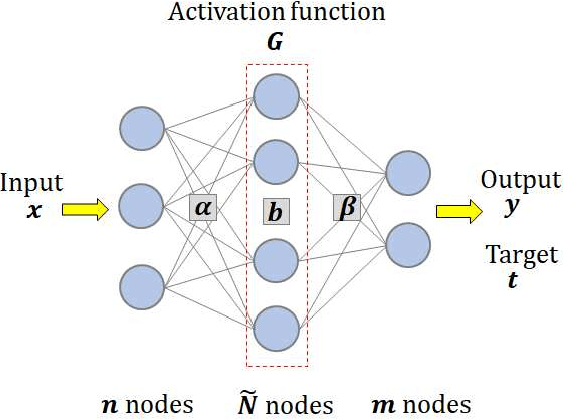
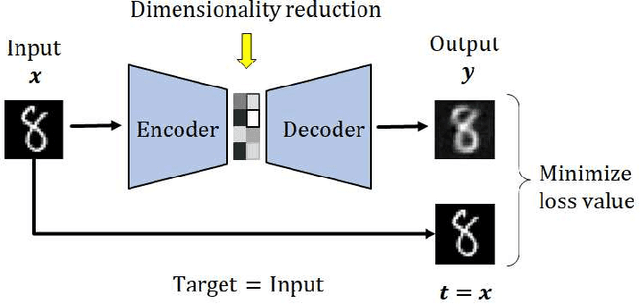
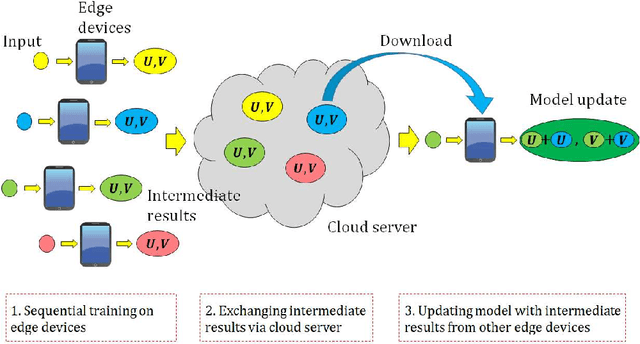
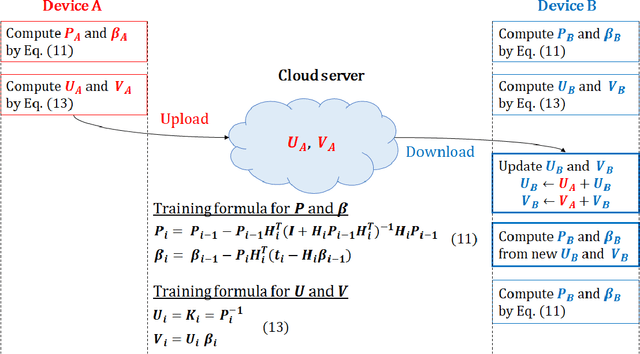
Most edge AI focuses on prediction tasks on resource-limited edge devices, while the training is done at server machines, so retraining a model on the edge devices to reflect environmental changes is a complicated task. To follow such a concept drift, a neural-network based on-device learning approach is recently proposed, so that edge devices train incoming data at runtime to update their model. In this case, since a training is done at distributed edge devices, the issue is that only a limited amount of training data can be used for each edge device. To address this issue, one approach is a cooperative learning or federated learning, where edge devices exchange their trained results and update their model by using those collected from the other devices. In this paper, as an on-device learning algorithm, we focus on OS-ELM (Online Sequential Extreme Learning Machine) and combine it with Autoencoder for anomaly detection. We extend it for an on-device federated learning so that edge devices exchange their trained results and update their model by using those collected from the other edge devices. Experimental results using a driving dataset of cars demonstrate that the proposed on-device federated learning can produce more accurate model by combining trained results from multiple edge devices compared to a single model.
A Neural Network Based On-device Learning Anomaly Detector for Edge Devices
Aug 28, 2019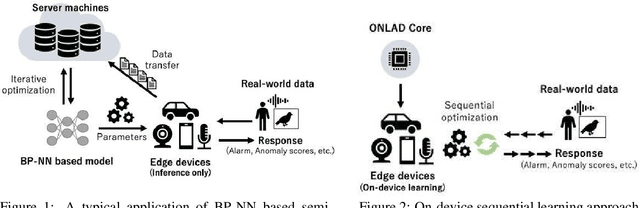
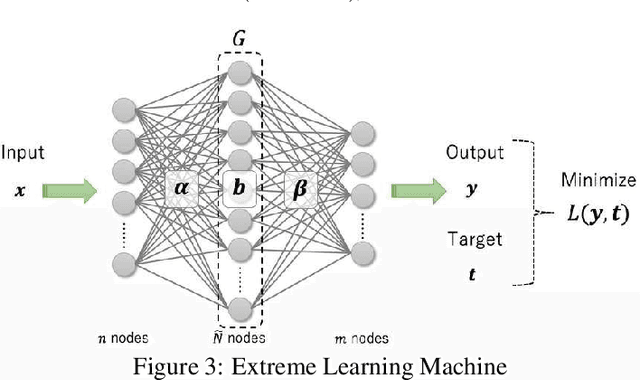
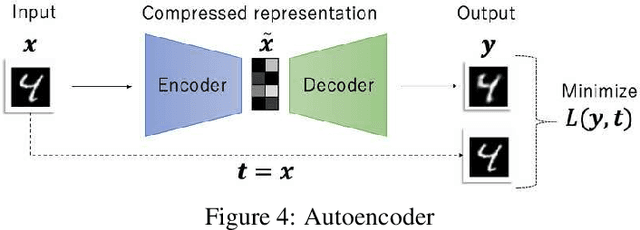

Semi-supervised anomaly detection is referred as an approach to identify rare data instances (i.e, anomalies) on the assumption that all the available training data belong to the majority (i.e., the normal class). A typical strategy is to model the distribution of normal data, then identify data samples far from the distribution as anomalies. Nowadays, backpropagation based neural networks (i.e., BP-NNs) have been drawing attention as well as in the field of semi-supervised anomaly detection because of their high generalization capability for real-world high dimensional data. As a typical application, such BP-NN based models are iteratively optimized in server machines with accumulated data gathered from edge devices. However, there are two issues in this framework: (1) BP-NNs' iterative optimization approach often takes too long time to follow changes of the distribution of normal data (i.e., concept drift), and (2) data transfers between servers and edge devices have a potential risk to cause data breaches. To address these underlying issues, we propose an ON-device sequential Learning semi-supervised Anomaly Detector called ONLAD. The aim of this work is to propose the algorithm, and also to implement it as an IP core called ONLAD Core so that various kinds of edge devices can adopt our approach at low power consumption. Experimental results using open datasets show that ONLAD has favorable anomaly detection capability especially in a testbed which simulates concept drift. Experimental results on hardware performance of the FPGA based ONLAD Core show that its training latency and prediction latency are x1.95 - x4.51 and x2.29 - x4.73 faster than those of BP-NN based software implementations. It is also confirmed that our on-board implementation of ONLAD Core actually works at x6.7 - x27.1 lower power consumption than the other software implementations at a high workload.