 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkip2-LoRA: A Lightweight On-device DNN Fine-tuning Method for Low-cost Edge Devices
Oct 28, 2024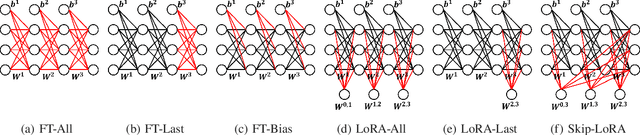

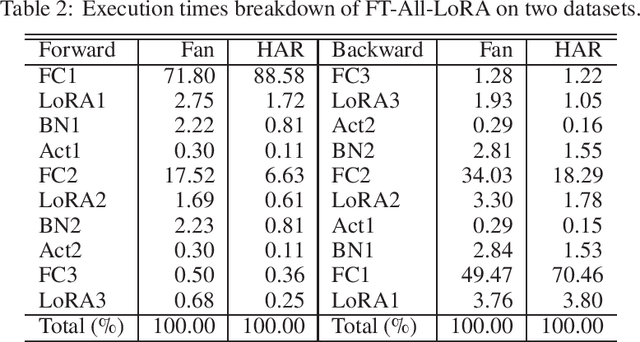

This paper proposes Skip2-LoRA as a lightweight fine-tuning method for deep neural networks to address the gap between pre-trained and deployed models. In our approach, trainable LoRA (low-rank adaptation) adapters are inserted between the last layer and every other layer to enhance the network expressive power while keeping the backward computation cost low. This architecture is well-suited to cache intermediate computation results of the forward pass and then can skip the forward computation of seen samples as training epochs progress. We implemented the combination of the proposed architecture and cache, denoted as Skip2-LoRA, and tested it on a $15 single board computer. Our results show that Skip2-LoRA reduces the fine-tuning time by 90.0% on average compared to the counterpart that has the same number of trainable parameters while preserving the accuracy, while taking only a few seconds on the microcontroller board.
An FPGA-Based Accelerator for Graph Embedding using Sequential Training Algorithm
Dec 23, 2023A graph embedding is an emerging approach that can represent a graph structure with a fixed-length low-dimensional vector. node2vec is a well-known algorithm to obtain such a graph embedding by sampling neighboring nodes on a given graph with a random walk technique. However, the original node2vec algorithm typically relies on a batch training of graph structures; thus, it is not suited for applications in which the graph structure changes after the deployment. In this paper, we focus on node2vec applications for IoT (Internet of Things) environments. To handle the changes of graph structures after the IoT devices have been deployed in edge environments, in this paper we propose to combine an online sequential training algorithm with node2vec. The proposed sequentially-trainable model is implemented on a resource-limited FPGA (Field-Programmable Gate Array) device to demonstrate the benefits of our approach. The proposed FPGA implementation achieves up to 205.25 times speedup compared to the original model on CPU. Evaluation results using dynamic graphs show that although the original model decreases the accuracy, the proposed sequential model can obtain better graph embedding that can increase the accuracy even when the graph structure is changed.