 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkip2-LoRA: A Lightweight On-device DNN Fine-tuning Method for Low-cost Edge Devices
Paper and Code
Oct 28, 2024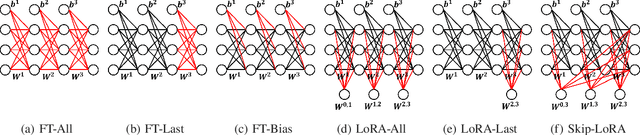

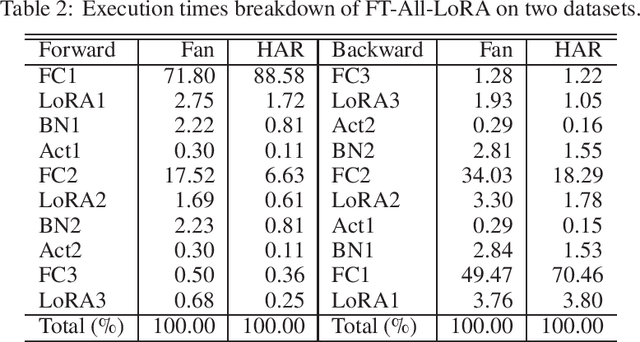

This paper proposes Skip2-LoRA as a lightweight fine-tuning method for deep neural networks to address the gap between pre-trained and deployed models. In our approach, trainable LoRA (low-rank adaptation) adapters are inserted between the last layer and every other layer to enhance the network expressive power while keeping the backward computation cost low. This architecture is well-suited to cache intermediate computation results of the forward pass and then can skip the forward computation of seen samples as training epochs progress. We implemented the combination of the proposed architecture and cache, denoted as Skip2-LoRA, and tested it on a $15 single board computer. Our results show that Skip2-LoRA reduces the fine-tuning time by 90.0% on average compared to the counterpart that has the same number of trainable parameters while preserving the accuracy, while taking only a few seconds on the microcontroller board.