 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Search Algorithms for Unsupervised Variable Selection: A Comparative Study
Mar 03, 2021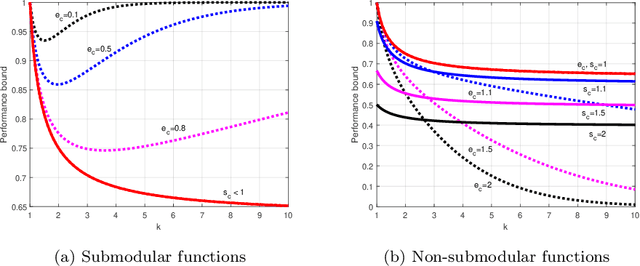
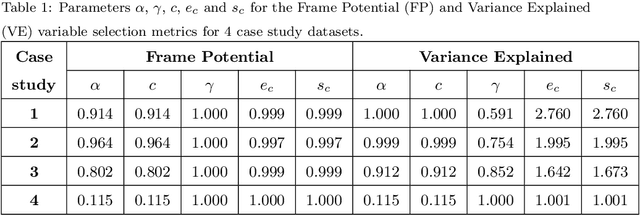
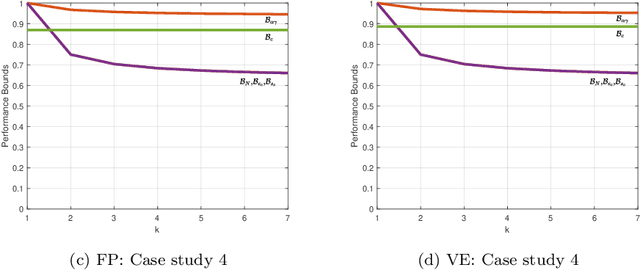

Dimensionality reduction is a important step in the development of scalable and interpretable data-driven models, especially when there are a large number of candidate variables. This paper focuses on unsupervised variable selection based dimensionality reduction, and in particular on unsupervised greedy selection methods, which have been proposed by various researchers as computationally tractable approximations to optimal subset selection. These methods are largely distinguished from each other by the selection criterion adopted, which include squared correlation, variance explained, mutual information and frame potential. Motivated by the absence in the literature of a systematic comparison of these different methods, we present a critical evaluation of seven unsupervised greedy variable selection algorithms considering both simulated and real world case studies. We also review the theoretical results that provide performance guarantees and enable efficient implementations for certain classes of greedy selection function, related to the concept of submodularity. Furthermore, we introduce and evaluate for the first time, a lazy implementation of the variance explained based forward selection component analysis (FSCA) algorithm. Our experimental results show that: (1) variance explained and mutual information based selection methods yield smaller approximation errors than frame potential; (2) the lazy FSCA implementation has similar performance to FSCA, while being an order of magnitude faster to compute, making it the algorithm of choice for unsupervised variable selection.
IntroVAC: Introspective Variational Classifiers for Learning Interpretable Latent Subspaces
Sep 14, 2020

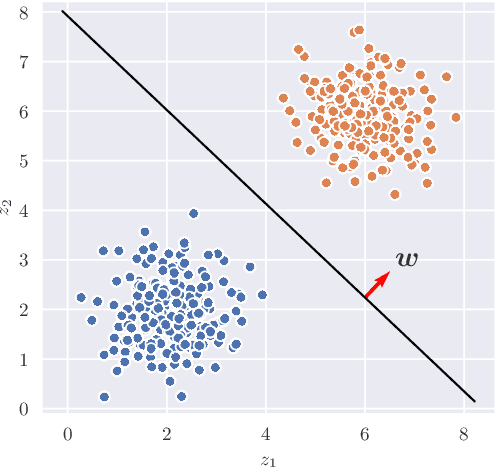

Learning useful representations of complex data has been the subject of extensive research for many years. With the diffusion of Deep Neural Networks, Variational Autoencoders have gained lots of attention since they provide an explicit model of the data distribution based on an encoder/decoder architecture which is able to both generate images and encode them in a low-dimensional subspace. However, the latent space is not easily interpretable and the generation capabilities show some limitations since images typically look blurry and lack details. In this paper, we propose the Introspective Variational Classifier (IntroVAC), a model that learns interpretable latent subspaces by exploiting information from an additional label and provides improved image quality thanks to an adversarial training strategy.We show that IntroVAC is able to learn meaningful directions in the latent space enabling fine-grained manipulation of image attributes. We validate our approach on the CelebA dataset.
Adversarial Training Reduces Information and Improves Transferability
Aug 21, 2020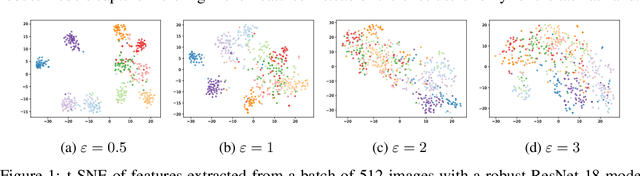

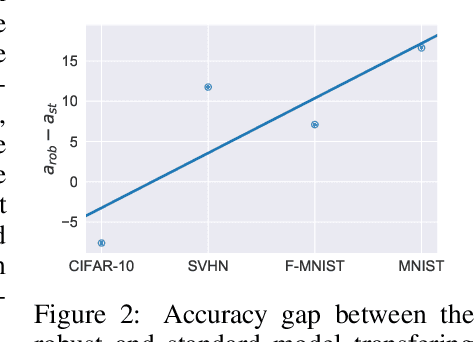

Recent results show that features of adversarially trained networks for classification, in addition to being robust, enable desirable properties such as invertibility. The latter property may seem counter-intuitive as it is widely accepted by the community that classification models should only capture the minimal information (features) required for the task. Motivated by this discrepancy, we investigate the dual relationship between Adversarial Training and Information Theory. We show that the Adversarial Training can improve linear transferability to new tasks, from which arises a new trade-off between transferability of representations and accuracy on the source task. We validate our results employing robust networks trained on CIFAR-10, CIFAR-100 and ImageNet on several datasets. Moreover, we show that Adversarial Training reduces Fisher information of representations about the input and of the weights about the task, and we provide a theoretical argument which explains the invertibility of deterministic networks without violating the principle of minimality. Finally, we leverage our theoretical insights to remarkably improve the quality of reconstructed images through inversion.
$β$-Variational Classifiers Under Attack
Aug 20, 2020

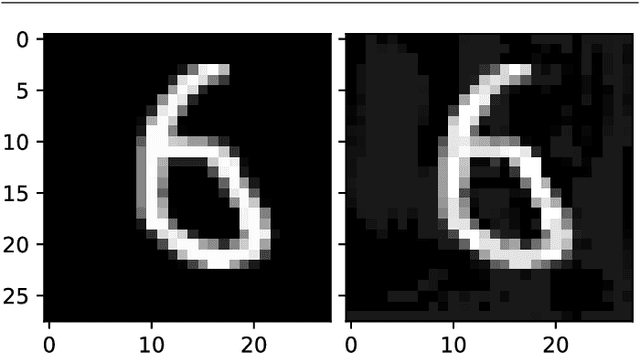
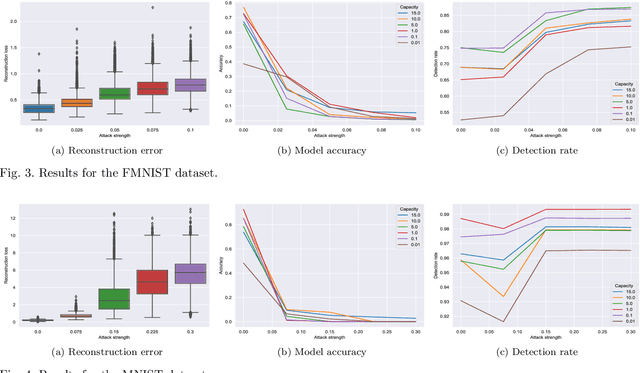
Deep Neural networks have gained lots of attention in recent years thanks to the breakthroughs obtained in the field of Computer Vision. However, despite their popularity, it has been shown that they provide limited robustness in their predictions. In particular, it is possible to synthesise small adversarial perturbations that imperceptibly modify a correctly classified input data, making the network confidently misclassify it. This has led to a plethora of different methods to try to improve robustness or detect the presence of these perturbations. In this paper, we perform an analysis of $\beta$-Variational Classifiers, a particular class of methods that not only solve a specific classification task, but also provide a generative component that is able to generate new samples from the input distribution. More in details, we study their robustness and detection capabilities, together with some novel insights on the generative part of the model.
Proximal Deterministic Policy Gradient
Aug 03, 2020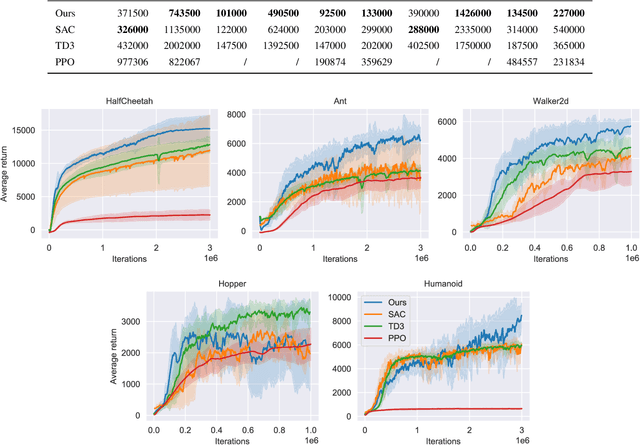
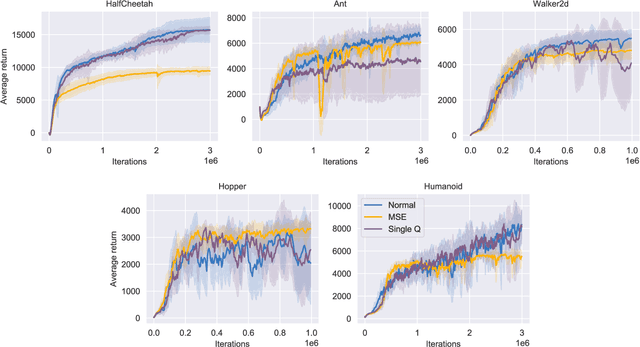
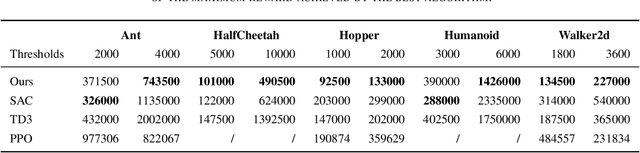
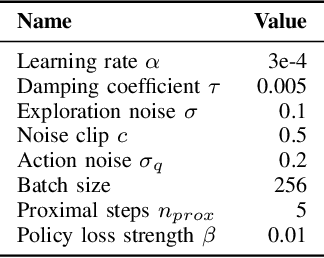
This paper introduces two simple techniques to improve off-policy Reinforcement Learning (RL) algorithms. First, we formulate off-policy RL as a stochastic proximal point iteration. The target network plays the role of the variable of optimization and the value network computes the proximal operator. Second, we exploits the two value functions commonly employed in state-of-the-art off-policy algorithms to provide an improved action value estimate through bootstrapping with limited increase of computational resources. Further, we demonstrate significant performance improvement over state-of-the-art algorithms on standard continuous-control RL benchmarks.