 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroVAC: Introspective Variational Classifiers for Learning Interpretable Latent Subspaces
Paper and Code
Sep 14, 2020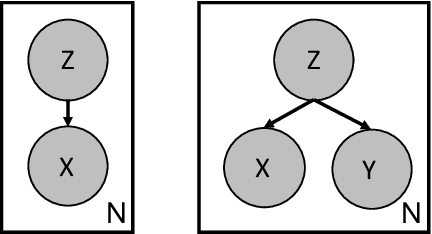

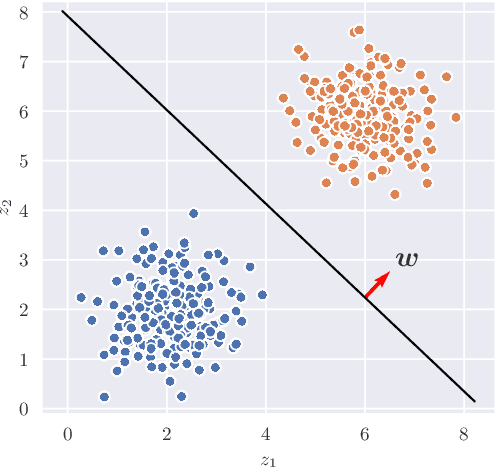

Learning useful representations of complex data has been the subject of extensive research for many years. With the diffusion of Deep Neural Networks, Variational Autoencoders have gained lots of attention since they provide an explicit model of the data distribution based on an encoder/decoder architecture which is able to both generate images and encode them in a low-dimensional subspace. However, the latent space is not easily interpretable and the generation capabilities show some limitations since images typically look blurry and lack details. In this paper, we propose the Introspective Variational Classifier (IntroVAC), a model that learns interpretable latent subspaces by exploiting information from an additional label and provides improved image quality thanks to an adversarial training strategy.We show that IntroVAC is able to learn meaningful directions in the latent space enabling fine-grained manipulation of image attributes. We validate our approach on the CelebA dataset.