 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Search Algorithms for Unsupervised Variable Selection: A Comparative Study
Paper and Code
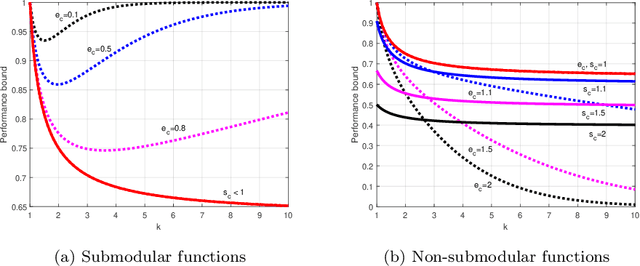
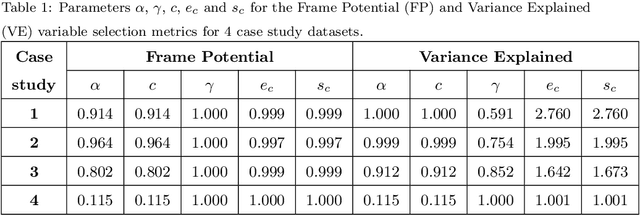
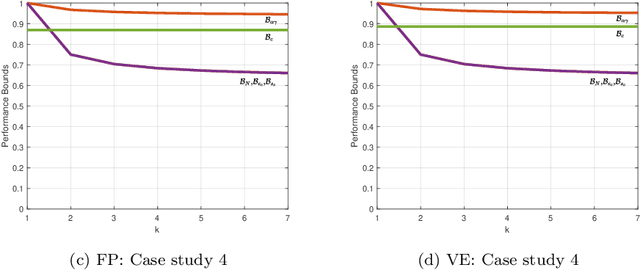

Dimensionality reduction is a important step in the development of scalable and interpretable data-driven models, especially when there are a large number of candidate variables. This paper focuses on unsupervised variable selection based dimensionality reduction, and in particular on unsupervised greedy selection methods, which have been proposed by various researchers as computationally tractable approximations to optimal subset selection. These methods are largely distinguished from each other by the selection criterion adopted, which include squared correlation, variance explained, mutual information and frame potential. Motivated by the absence in the literature of a systematic comparison of these different methods, we present a critical evaluation of seven unsupervised greedy variable selection algorithms considering both simulated and real world case studies. We also review the theoretical results that provide performance guarantees and enable efficient implementations for certain classes of greedy selection function, related to the concept of submodularity. Furthermore, we introduce and evaluate for the first time, a lazy implementation of the variance explained based forward selection component analysis (FSCA) algorithm. Our experimental results show that: (1) variance explained and mutual information based selection methods yield smaller approximation errors than frame potential; (2) the lazy FSCA implementation has similar performance to FSCA, while being an order of magnitude faster to compute, making it the algorithm of choice for unsupervised variable selection.