 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modeling on Lie Groups via Euclidean Generalized Score Matching
Feb 04, 2025
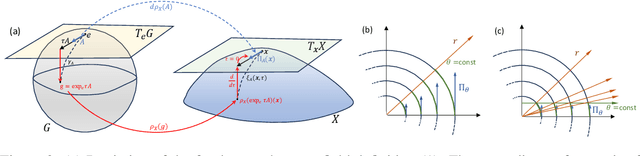
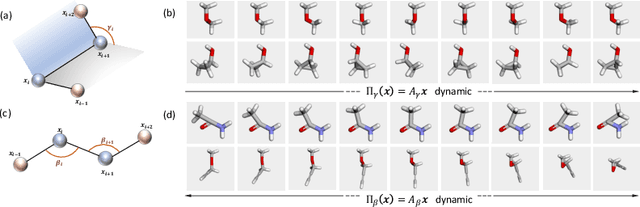

We extend Euclidean score-based diffusion processes to generative modeling on Lie groups. Through the formalism of Generalized Score Matching, our approach yields a Langevin dynamics which decomposes as a direct sum of Lie algebra representations, enabling generative processes on Lie groups while operating in Euclidean space. Unlike equivariant models, which restrict the space of learnable functions by quotienting out group orbits, our method can model any target distribution on any (non-Abelian) Lie group. Standard score matching emerges as a special case of our framework when the Lie group is the translation group. We prove that our generalized generative processes arise as solutions to a new class of paired stochastic differential equations (SDEs), introduced here for the first time. We validate our approach through experiments on diverse data types, demonstrating its effectiveness in real-world applications such as SO(3)-guided molecular conformer generation and modeling ligand-specific global SE(3) transformations for molecular docking, showing improvement in comparison to Riemannian diffusion on the group itself. We show that an appropriate choice of Lie group enhances learning efficiency by reducing the effective dimensionality of the trajectory space and enables the modeling of transitions between complex data distributions. Additionally, we demonstrate the universality of our approach by deriving how it extends to flow matching.
From slides (through tiles) to pixels: an explainability framework for weakly supervised models in pre-clinical pathology
Feb 03, 2023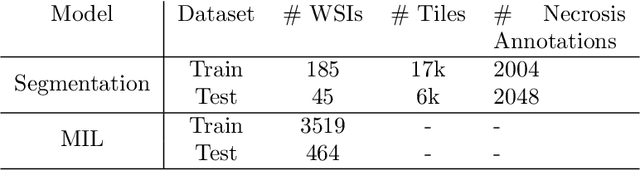
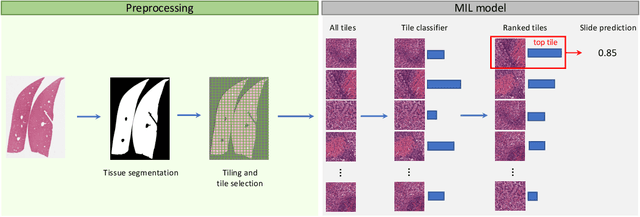

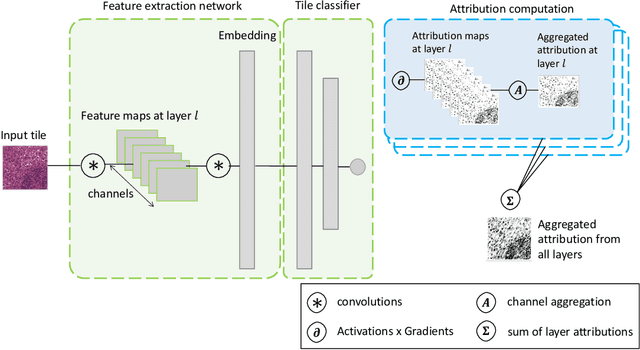
In pre-clinical pathology, there is a paradox between the abundance of raw data (whole slide images from many organs of many individual animals) and the lack of pixel-level slide annotations done by pathologists. Due to time constraints and requirements from regulatory authorities, diagnoses are instead stored as slide labels. Weakly supervised training is designed to take advantage of those data, and the trained models can be used by pathologists to rank slides by their probability of containing a given lesion of interest. In this work, we propose a novel contextualized eXplainable AI (XAI) framework and its application to deep learning models trained on Whole Slide Images (WSIs) in Digital Pathology. Specifically, we apply our methods to a multi-instance-learning (MIL) model, which is trained solely on slide-level labels, without the need for pixel-level annotations. We validate quantitatively our methods by quantifying the agreements of our explanations' heatmaps with pathologists' annotations, as well as with predictions from a segmentation model trained on such annotations. We demonstrate the stability of the explanations with respect to input shifts, and the fidelity with respect to increased model performance. We quantitatively evaluate the correlation between available pixel-wise annotations and explainability heatmaps. We show that the explanations on important tiles of the whole slide correlate with tissue changes between healthy regions and lesions, but do not exactly behave like a human annotator. This result is coherent with the model training strategy.
Explaining, Evaluating and Enhancing Neural Networks' Learned Representations
Feb 18, 2022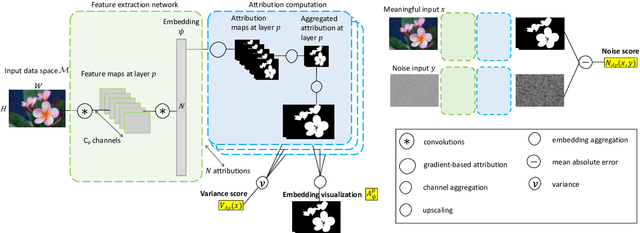
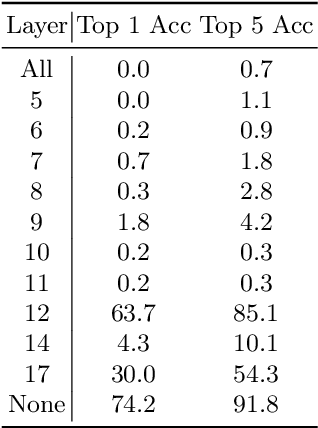
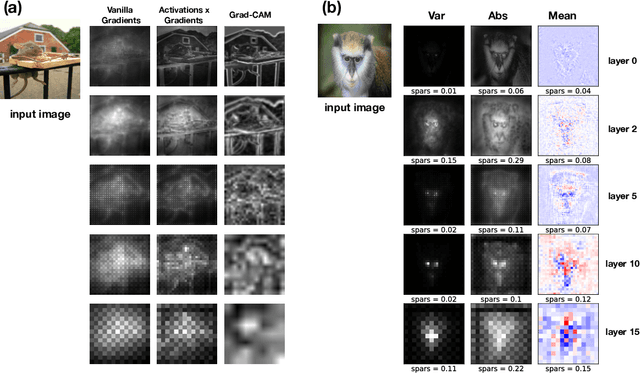
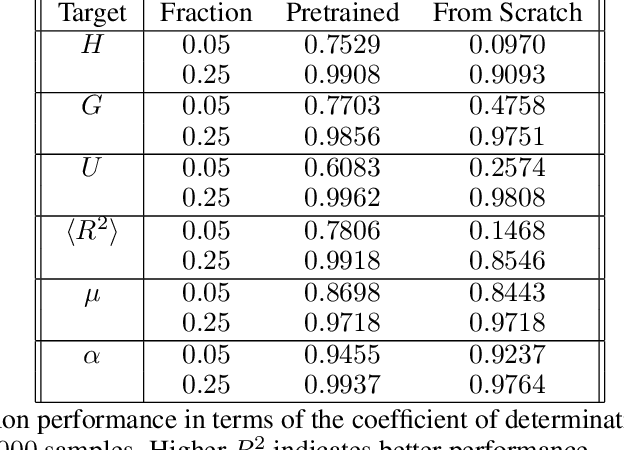
Most efforts in interpretability in deep learning have focused on (1) extracting explanations of a specific downstream task in relation to the input features and (2) imposing constraints on the model, often at the expense of predictive performance. New advances in (unsupervised) representation learning and transfer learning, however, raise the need for an explanatory framework for networks that are trained without a specific downstream task. We address these challenges by showing how explainability can be an aid, rather than an obstacle, towards better and more efficient representations. Specifically, we propose a natural aggregation method generalizing attribution maps between any two (convolutional) layers of a neural network. Additionally, we employ such attributions to define two novel scores for evaluating the informativeness and the disentanglement of latent embeddings. Extensive experiments show that the proposed scores do correlate with the desired properties. We also confirm and extend previously known results concerning the independence of some common saliency strategies from the model parameters. Finally, we show that adopting our proposed scores as constraints during the training of a representation learning task improves the downstream performance of the model.
Unsupervised Learning of Group Invariant and Equivariant Representations
Feb 15, 2022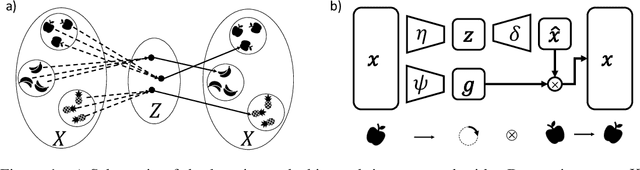
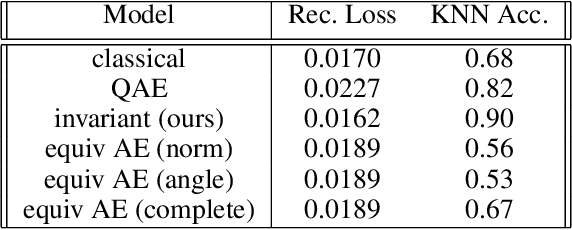

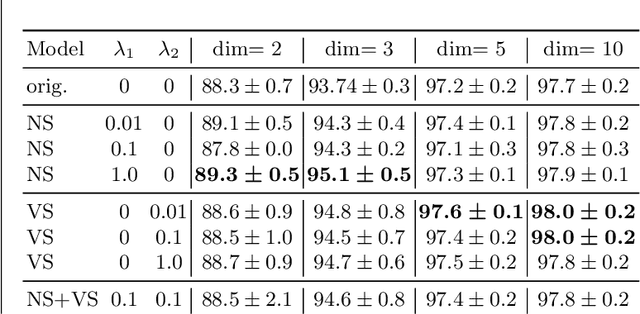
Equivariant neural networks, whose hidden features transform according to representations of a group G acting on the data, exhibit training efficiency and an improved generalisation performance. In this work, we extend group invariant and equivariant representation learning to the field of unsupervised deep learning. We propose a general learning strategy based on an encoder-decoder framework in which the latent representation is disentangled in an invariant term and an equivariant group action component. The key idea is that the network learns the group action on the data space and thus is able to solve the reconstruction task from an invariant data representation, hence avoiding the necessity of ad-hoc group-specific implementations. We derive the necessary conditions on the equivariant encoder, and we present a construction valid for any G, both discrete and continuous. We describe explicitly our construction for rotations, translations and permutations. We test the validity and the robustness of our approach in a variety of experiments with diverse data types employing different network architectures.
Parameterized Hypercomplex Graph Neural Networks for Graph Classification
Mar 30, 2021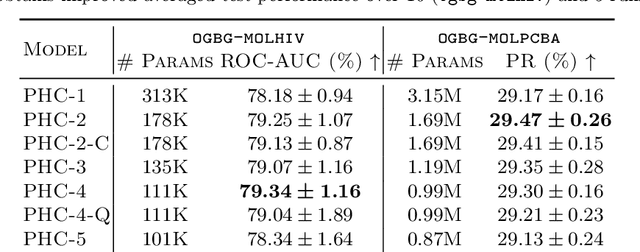
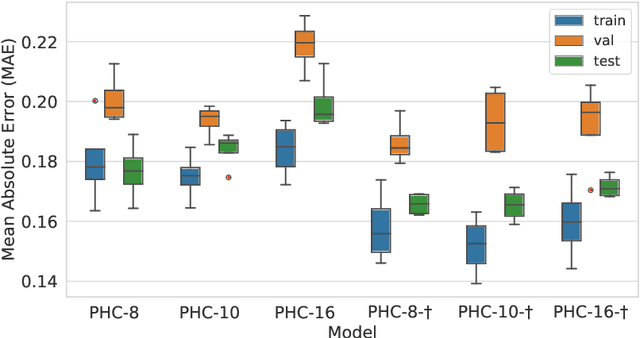
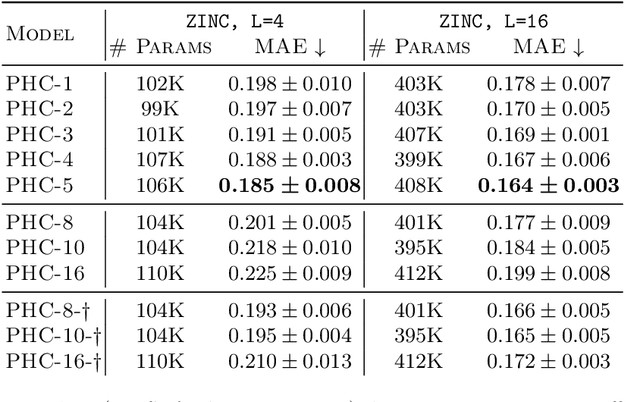
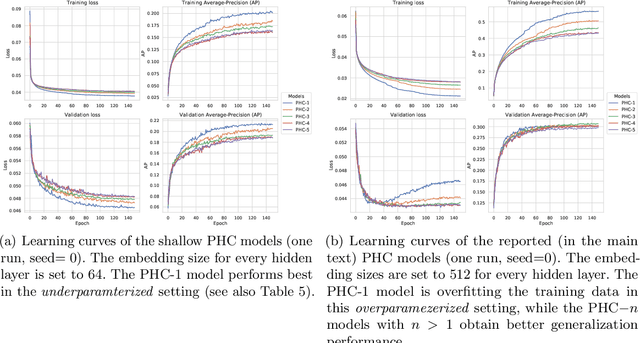
Despite recent advances in representation learning in hypercomplex (HC) space, this subject is still vastly unexplored in the context of graphs. Motivated by the complex and quaternion algebras, which have been found in several contexts to enable effective representation learning that inherently incorporates a weight-sharing mechanism, we develop graph neural networks that leverage the properties of hypercomplex feature transformation. In particular, in our proposed class of models, the multiplication rule specifying the algebra itself is inferred from the data during training. Given a fixed model architecture, we present empirical evidence that our proposed model incorporates a regularization effect, alleviating the risk of overfitting. We also show that for fixed model capacity, our proposed method outperforms its corresponding real-formulated GNN, providing additional confirmation for the enhanced expressivity of HC embeddings. Finally, we test our proposed hypercomplex GNN on several open graph benchmark datasets and show that our models reach state-of-the-art performance while consuming a much lower memory footprint with 70& fewer parameters. Our implementations are available at https://github.com/bayer-science-for-a-better-life/phc-gnn.