 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining, Evaluating and Enhancing Neural Networks' Learned Representations
Paper and Code
Feb 18, 2022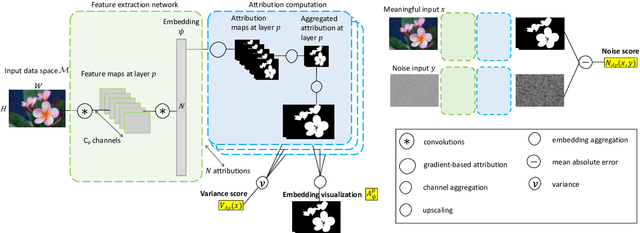
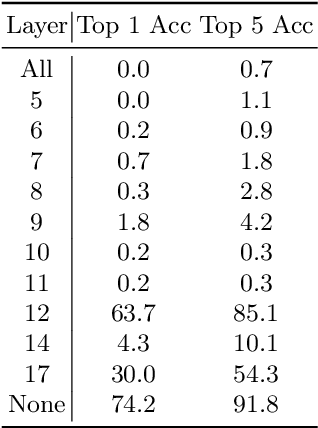
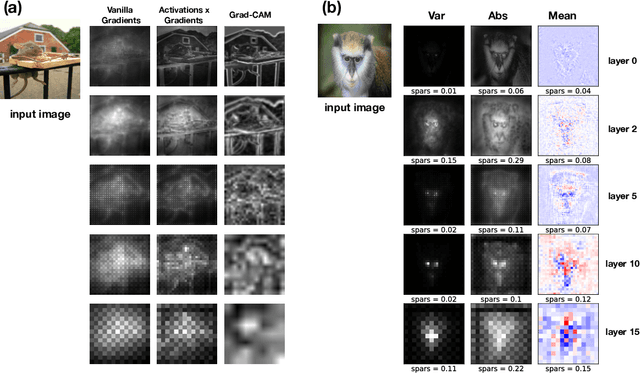
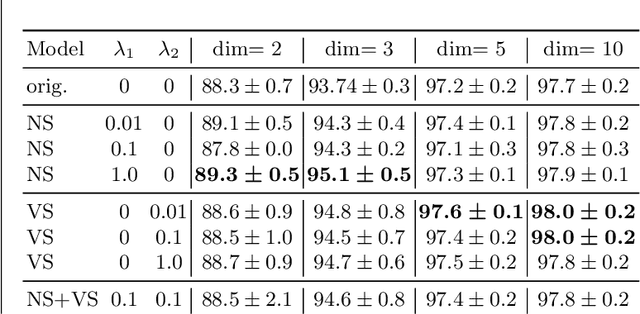
Most efforts in interpretability in deep learning have focused on (1) extracting explanations of a specific downstream task in relation to the input features and (2) imposing constraints on the model, often at the expense of predictive performance. New advances in (unsupervised) representation learning and transfer learning, however, raise the need for an explanatory framework for networks that are trained without a specific downstream task. We address these challenges by showing how explainability can be an aid, rather than an obstacle, towards better and more efficient representations. Specifically, we propose a natural aggregation method generalizing attribution maps between any two (convolutional) layers of a neural network. Additionally, we employ such attributions to define two novel scores for evaluating the informativeness and the disentanglement of latent embeddings. Extensive experiments show that the proposed scores do correlate with the desired properties. We also confirm and extend previously known results concerning the independence of some common saliency strategies from the model parameters. Finally, we show that adopting our proposed scores as constraints during the training of a representation learning task improves the downstream performance of the model.