 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Set Semantic Tagging: End-to-End Multi-label Prediction using Neural Attention for Complex Query Reformulation and Automated Text Categorization
Nov 11, 2019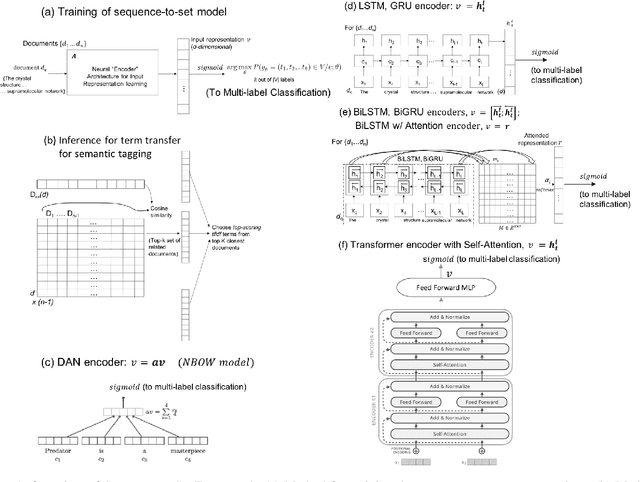

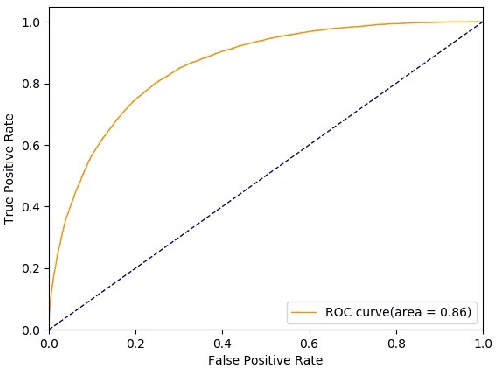
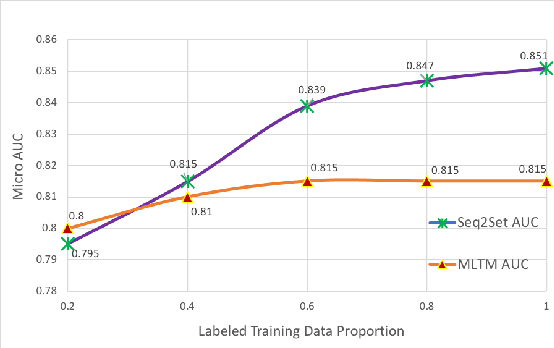
Novel contexts may often arise in complex querying scenarios such as in evidence-based medicine (EBM) involving biomedical literature, that may not explicitly refer to entities or canonical concept forms occurring in any fact- or rule-based knowledge source such as an ontology like the UMLS. Moreover, hidden associations between candidate concepts meaningful in the current context, may not exist within a single document, but within the collection, via alternate lexical forms. Therefore, inspired by the recent success of sequence-to-sequence neural models in delivering the state-of-the-art in a wide range of NLP tasks, we develop a novel sequence-to-set framework with neural attention for learning document representations that can effect term transfer within the corpus, for semantically tagging a large collection of documents. We demonstrate that our proposed method can be effective in both a supervised multi-label classification setup for text categorization, as well as in a unique unsupervised setting with no human-annotated document labels that uses no external knowledge resources and only corpus-derived term statistics to drive the training. Further, we show that semi-supervised training using our architecture on large amounts of unlabeled data can augment performance on the text categorization task when limited labeled data is available. Our approach to generate document encodings employing our sequence-to-set models for inference of semantic tags, gives to the best of our knowledge, the state-of-the-art for both, the unsupervised query expansion task for the TREC CDS 2016 challenge dataset when evaluated on an Okapi BM25--based document retrieval system; and also over the MLTM baseline (Soleimani et al, 2016), for both supervised and semi-supervised multi-label prediction tasks on the del.icio.us and Ohsumed datasets. We will make our code and data publicly available.
Comparison of Quality Indicators in User-generated Content Using Social Media and Scholarly Text
Oct 24, 2019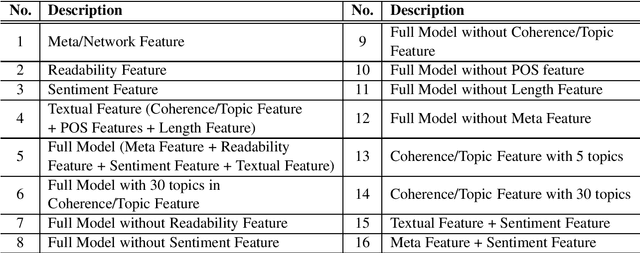
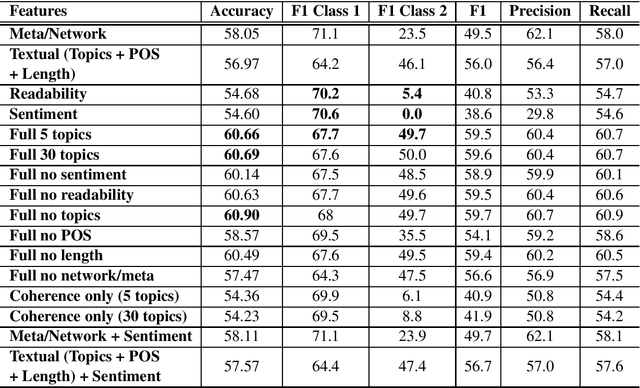

Predicting the quality of a text document is a critical task when presented with the problem of measuring the performance of a document before its release. In this work, we evaluate various features including those extracted from the text content (textual) and those describing higher-level characteristics of the text (meta) features that are not directly available from the text, and show how these features inform prediction of document quality in different ways. Moreover, we also compare our methods on both social user-generated data such as tweets, and scholarly user-generated data such as academic articles, showing how the same features differently influence prediction of quality across these disparate domains.
Learning to Answer Subjective, Specific Product-Related Queries using Customer Reviews by Adversarial Domain Adaptation
Oct 22, 2019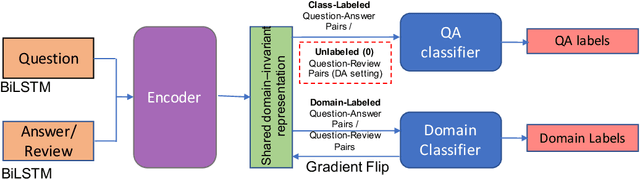
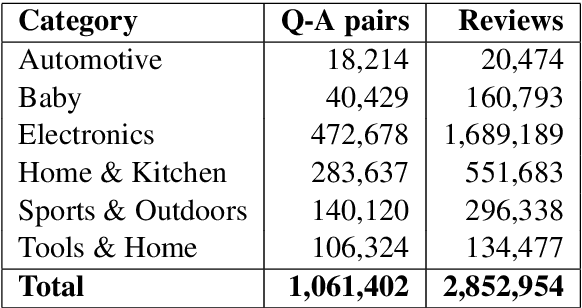

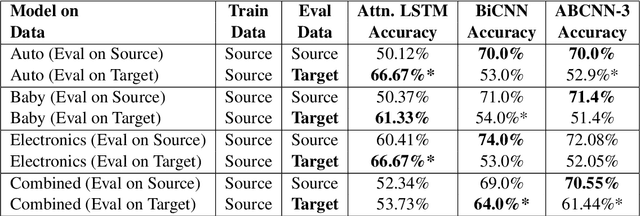
Online customer reviews on large-scale e-commerce websites, represent a rich and varied source of opinion data, often providing subjective qualitative assessments of product usage that can help potential customers to discover features that meet their personal needs and preferences. Thus they have the potential to automatically answer specific queries about products, and to address the problems of answer starvation and answer augmentation on associated consumer Q & A forums, by providing good answer alternatives. In this work, we explore several recently successful neural approaches to modeling sentence pairs, that could better learn the relationship between questions and ground truth answers, and thus help infer reviews that can best answer a question or augment a given answer. In particular, we hypothesize that our adversarial domain adaptation-based approach, due to its ability to additionally learn domain-invariant features from a large number of unlabeled, unpaired question-review samples, would perform better than our proposed baselines, at answering specific, subjective product-related queries using reviews. We validate this hypothesis using a small gold standard dataset of question-review pairs evaluated by human experts, significantly surpassing our chosen baselines. Moreover, our approach, using no labeled question-review sentence pair data for training, gives performance at par with another method utilizing labeled question-review samples for the same task.