Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Quality Indicators in User-generated Content Using Social Media and Scholarly Text
Paper and Code
Oct 24, 2019
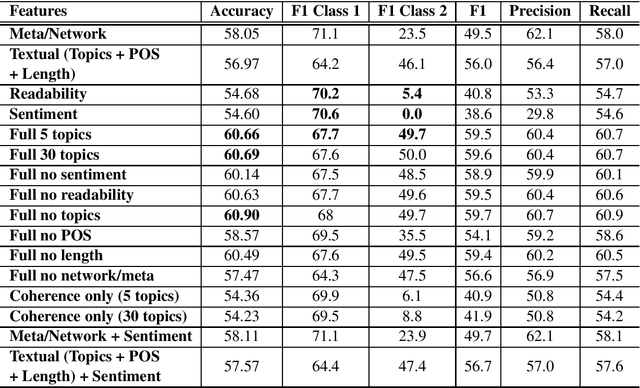

Predicting the quality of a text document is a critical task when presented with the problem of measuring the performance of a document before its release. In this work, we evaluate various features including those extracted from the text content (textual) and those describing higher-level characteristics of the text (meta) features that are not directly available from the text, and show how these features inform prediction of document quality in different ways. Moreover, we also compare our methods on both social user-generated data such as tweets, and scholarly user-generated data such as academic articles, showing how the same features differently influence prediction of quality across these disparate domains.
* 8 pages, 3 tables
View paper on